AI Software Juggles Probabilities to Learn from Less Data
Machine learning is becoming extremely powerful, but it requires extreme amounts of data.
You can, for instance, train a deep-learning algorithm to recognize a cat with a cat-fancier’s level of expertise, but you’ll need to feed it tens or even hundreds of thousands of images of felines, capturing a huge amount of variation in size, shape, texture, lighting, and orientation. It would be lot more efficient if, a bit like a person, an algorithm could develop an idea about what makes a cat a cat from fewer examples.
A Boston-based startup called Gamalon has developed technology that lets computers do this in some situations, and it is releasing two products Tuesday based on the approach.
If the underlying technique can be applied to many other tasks, then it could have a big impact. The ability to learn from less data could let robots explore and understand new environments very quickly, or allow computers to learn about your preferences without sharing your data.
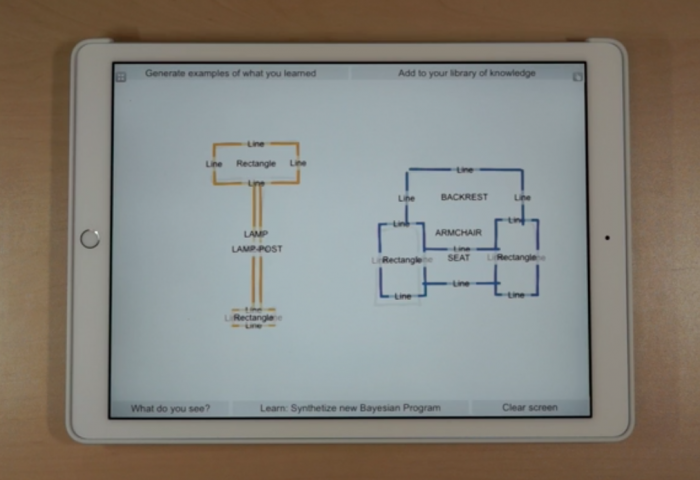
Gamalon uses a technique that it calls Bayesian program synthesis to build algorithms capable of learning from fewer examples. Bayesian probability, named after the 18th century mathematician Thomas Bayes, provides a mathematical framework for refining predictions about the world based on experience. Gamalon’s system uses probabilistic programming—or code that deals in probabilities rather than specific variables—to build a predictive model that explains a particular data set. From just a few examples, a probabilistic program can determine, for instance, that it’s highly probable that cats have ears, whiskers, and tails. As further examples are provided, the code behind the model is rewritten, and the probabilities tweaked. This provides an efficient way to learn the salient knowledge from the data.
Probabilistic programming techniques have been around for a while. In 2015, for example, a team from MIT and NYU used probabilistic methods to have computers learn to recognize written characters and objects after seeing just one example (see “This AI Algorithm Learns Simple Tasks as Fast as We Do”). But the approach has mostly been an academic curiosity.
There are difficult computational challenges to overcome, because the program has to consider many different possible explanations, says Brenden Lake, a research fellow at NYU who led the 2015 work.
Still, in theory, Lake says, the approach has significant potential because it can automate aspects of developing a machine-learning model. “Probabilistic programming will make machine learning much easier for researchers and practitioners,” Lake says. “It has the potential to take care of the difficult [programming] parts automatically.”
There are certainly significant incentives to develop easier-to-use and less data-hungry machine-learning approaches. Machine learning currently involves acquiring a large raw data set, and often then labeling it manually. The learning is then done inside large data centers, using many computer processors churning away in parallel for hours or days. “There are only a few really large companies that can really afford to do this,” says Ben Vigoda, cofounder and CEO of Gamalon.
In theory, Gamalon’s approach could make it a lot easier for someone to build and refine a machine-learning model, too. Perfecting a deep-learning algorithm requires a great deal of mathematical and machine-learning expertise. “There’s a black art to setting these systems up,” Vigoda says. With Gamalon’s approach, a programmer could train a model by feeding in significant examples.
Vigoda showed MIT Technology Review a demo with a drawing app that uses the technique. It is similar to the one released last year by Google, which uses deep learning to recognize the object a person is trying to sketch (see “Want to Understand AI? Try Sketching a Duck for a Neural Network”). But whereas Google’s app needs to see a sketch that matches the ones it has seen previously, Gamalon’s version uses a probabilistic program to recognize the key features of an object. For instance, one program understands that a triangle sitting atop a square is most likely a house. This means even if your sketch is very different from what it has seen before, providing it has those features, it will guess correctly.
The technique could have significant near-term commercial applications, too. The company’s first products use Bayesian program synthesis to recognize concepts in text.
One product, called Gamalon Structure, can extract concepts from raw text more efficiently than is normally possible. For example, it can take a manufacturer’s description of a television and determine what product is being described, the brand, the product name, the resolution, the size, and other features. Another product, Gamalon Match, is used to categorize the products and price in a store’s inventory. In each case, even when different acronyms or abbreviations are used for a product or feature, the system can quickly be trained to recognize them.
Vigoda believes the ability to learn will have other practical benefits. A computer could learn about a user’s interests without requiring an impractical amount of data or hours of training. Personal data might not need to be shared with large companies, either, if machine learning can be done efficiently on a user’s smartphone or laptop. And a robot or a self-driving car could learn about a new obstacle without needing to see hundreds of thousands of examples.
Deep Dive
Artificial intelligence
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Is robotics about to have its own ChatGPT moment?
Researchers are using generative AI and other techniques to teach robots new skills—including tasks they could perform in homes.
An AI startup made a hyperrealistic deepfake of me that’s so good it’s scary
Synthesia's new technology is impressive but raises big questions about a world where we increasingly can’t tell what’s real.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.