This is how we lost control of our faces
The largest ever study of facial-recognition data shows how much the rise of deep learning has fueled a loss of privacy.
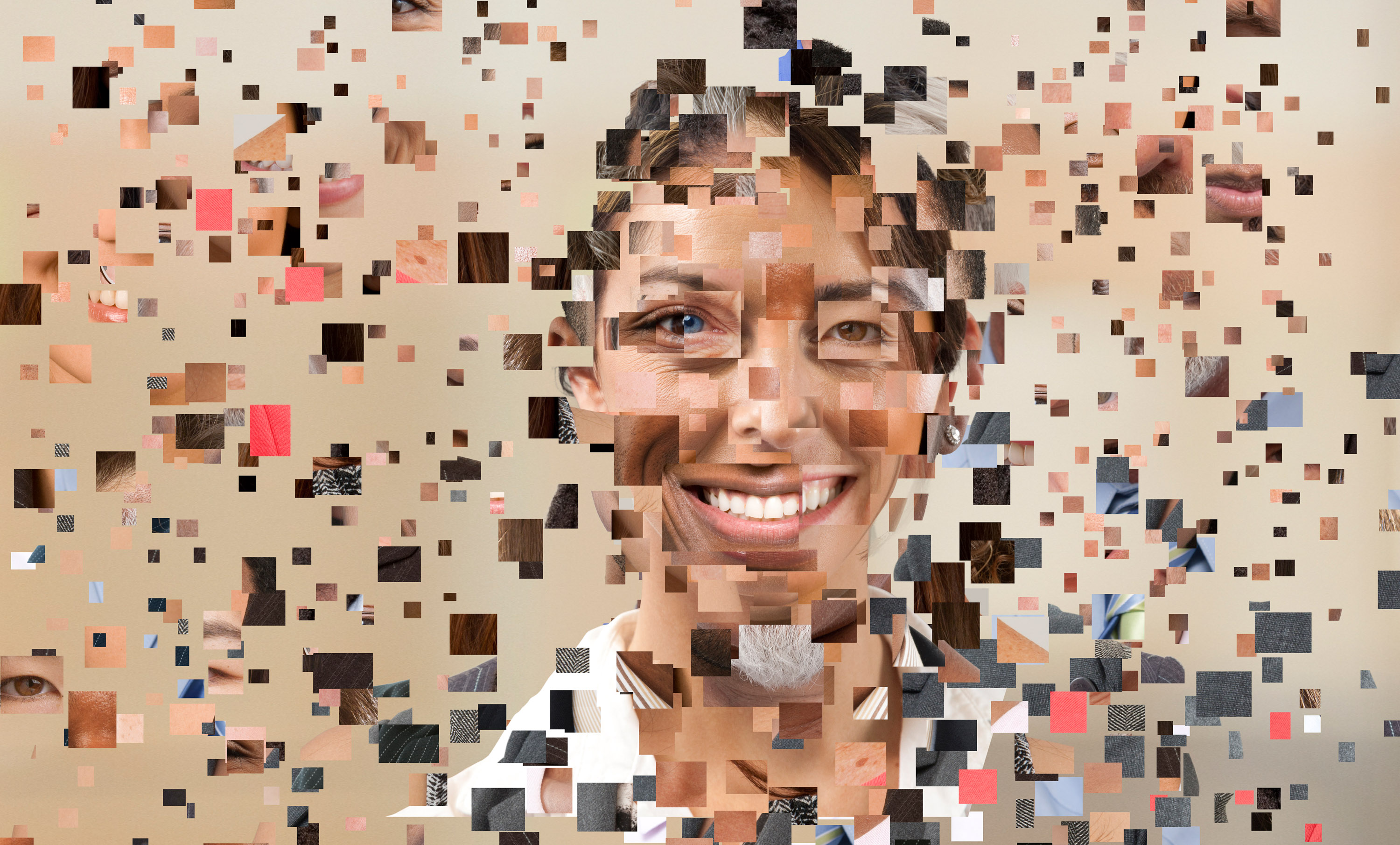
In 1964, mathematician and computer scientist Woodrow Bledsoe first attempted the task of matching suspects’ faces to mugshots. He measured out the distances between different facial features in printed photographs and fed them into a computer program. His rudimentary successes would set off decades of research into teaching machines to recognize human faces.
Now a new study shows just how much this enterprise has eroded our privacy. It hasn’t just fueled an increasingly powerful tool of surveillance. The latest generation of deep-learning-based facial recognition has completely disrupted our norms of consent.
Deborah Raji, a fellow at nonprofit Mozilla, and Genevieve Fried, who advises members of the US Congress on algorithmic accountability, examined over 130 facial-recognition data sets compiled over 43 years. They found that researchers, driven by the exploding data requirements of deep learning, gradually abandoned asking for people’s consent. This has led more and more of people’s personal photos to be incorporated into systems of surveillance without their knowledge.
It has also led to far messier data sets: they may unintentionally include photos of minors, use racist and sexist labels, or have inconsistent quality and lighting. The trend could help explain the growing number of cases in which facial-recognition systems have failed with troubling consequences, such as the false arrests of two Black men in the Detroit area last year.
People were extremely cautious about collecting, documenting, and verifying face data in the early days, says Raji. “Now we don’t care anymore. All of that has been abandoned,” she says. “You just can’t keep track of a million faces. After a certain point, you can’t even pretend that you have control.”
A history of facial-recognition data
The researchers identified four major eras of facial recognition, each driven by an increasing desire to improve the technology. The first phase, which ran until the 1990s, was largely characterized by manually intensive and computationally slow methods.
But then, spurred by the realization that facial recognition could track and identify individuals more effectively than fingerprints, the US Department of Defense pumped $6.5 million into creating the first large-scale face data set. Over 15 photography sessions in three years, the project captured 14,126 images of 1,199 individuals. The Face Recognition Technology (FERET) database was released in 1996.
The following decade saw an uptick in academic and commercial facial-recognition research, and many more data sets were created. The vast majority were sourced through photo shoots like FERET’s and had full participant consent. Many also included meticulous metadata, Raji says, such as the age and ethnicity of subjects, or illumination information. But these early systems struggled in real-world settings, which drove researchers to seek larger and more diverse data sets.
In 2007, the release of the Labeled Faces in the Wild (LFW) data set opened the floodgates to data collection through web search. Researchers began downloading images directly from Google, Flickr, and Yahoo without concern for consent. A subsequent dataset compiled by other researchers called LFW+ also relaxed standards around the inclusion of minors, using photos found with search terms like “baby,” “juvenile,” and “teen” to increase diversity. This process made it possible to create significantly larger data sets in a short time, but facial recognition still faced many of the same challenges as before. This pushed researchers to seek yet more methods and data to overcome the technology’s poor performance.
Then, in 2014, Facebook used its user photos to train a deep-learning model called DeepFace. While the company never released the data set, the system’s superhuman performance elevated deep learning to the de facto method for analyzing faces. This is when manual verification and labeling became nearly impossible as data sets grew to tens of millions of photos, says Raji. It’s also when really strange phenomena start appearing, like auto-generated labels that include offensive terminology.
The way the data sets were used began to change around this time, too. Instead of trying to match individuals, new models began focusing more on classification. “Instead of saying, ‘Is this a photo of Karen? Yes or no,’ it turned into ‘Let’s predict Karen’s internal personality, or her ethnicity,’ and boxing people into these categories,” Raji says.
Amba Kak, the global policy director at AI Now, who did not participate in the research, says the paper offers a stark picture of how the biometrics industry has evolved. Deep learning may have rescued the technology from some of its struggles, but “that technological advance also has come at a cost,” she says. “It’s thrown up all these issues that we now are quite familiar with: consent, extraction, IP issues, privacy.”
Harm that begets harm
Raji says her investigation into the data has made her gravely concerned about deep-learning-based facial recognition.
“It’s so much more dangerous,” she says. “The data requirement forces you to collect incredibly sensitive information about, at minimum, tens of thousands of people. It forces you to violate their privacy. That in itself is a basis of harm. And then we’re hoarding all this information that you can’t control to build something that likely will function in ways you can’t even predict. That’s really the nature of where we’re at.”
She hopes the paper will provoke researchers to reflect on the trade-off between the performance gains derived from deep learning and the loss of consent, meticulous data verification, and thorough documentation. “Was it worth abandoning all of these practices in order to do deep learning?” she says.
She urges those who want to continue building facial recognition to consider developing different techniques: “For us to really try to use this tool without hurting people will require re-envisioning everything we know about it.”
Correction, Feb 15, 2021: A previous version of the article stated that the Labeled Faces in the Wild (LFW) dataset "relaxed standards around the inclusion of minors." It was in fact the LFW+ dataset, which was compiled afterwards by a different group of researchers.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.