A radical new neural network design could overcome big challenges in AI

David Duvenaud was collaborating on a project involving medical data when he ran up against a major shortcoming in AI.
An AI researcher at the University of Toronto, he wanted to build a deep-learning model that would predict a patient’s health over time. But data from medical records is kind of messy: throughout your life, you might visit the doctor at different times for different reasons, generating a smattering of measurements at arbitrary intervals. A traditional neural network struggles to handle this. Its design requires it to learn from data with clear stages of observation. Thus it is a poor tool for modeling continuous processes, especially ones that are measured irregularly over time.
The challenge led Duvenaud and his collaborators at the university and the Vector Institute to redesign neural networks as we know them. Last week their paper was among four others crowned “best paper” at the Neural Information Processing Systems conference, one of the largest AI research gatherings in the world.
Neural nets are the core machinery that make deep learning so powerful. A traditional neural net is made up of stacked layers of simple computational nodes that work together to find patterns in data. The discrete layers are what keep it from effectively modeling continuous processes (we’ll get to that).
In response, the research team's design scraps the layers entirely. (Duvenaud is quick to note that they didn’t come up with this idea. They were just the first to implement it in a generalizable way.) To understand how this is possible, let’s walk through what the layers do in the first place.
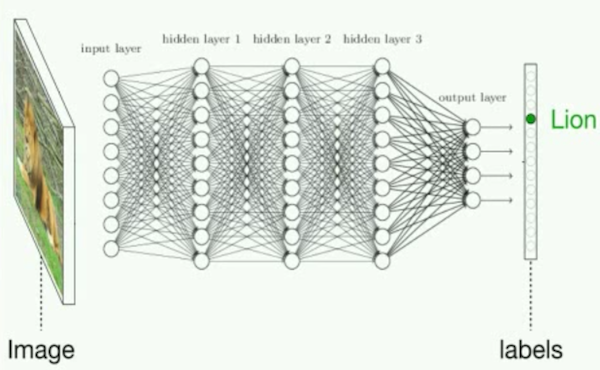
The most common process for training a neural network (a.k.a. supervised learning) involves feeding it a bunch of labeled data. Let’s say you wanted to build a system that recognizes different animals. You’d feed a neural net animal pictures paired with corresponding animal names. Under the hood, it begins to solve a crazy mathematical puzzle. It looks at all the picture-name pairs and figures out a formula that reliably turns one (the image) into the other (the category). Once it cracks that puzzle, it can reuse the formula again and again to correctly categorize any new animal photo—most of the time.
But finding a single formula to describe the entire picture-to-name transformation would be overly broad and result in a low-accuracy model. It would be like trying to use a single rule to differentiate cats and dogs. You could say dogs have floppy ears. But some dogs don’t and some cats do, so you’d end up with a lot of false negatives and positives.
This is where a neural net’s layers come in. They break up the transformation process into steps and let the network find a series of formulas that each describe a stage of the process. So the first layer might take in all the pixels and use a formula to pick out which ones are most relevant for cats versus dogs. A second layer might use another to construct larger patterns from groups of pixels and figure out whether the image has whiskers or ears. Each subsequent layer would identify increasingly complex features of the animal, until the final layer decides “dog” on the basis of the accumulated calculations. This step-by-step breakdown of the process allows a neural net to build more sophisticated models—which in turn should lead to more accurate predictions.
The layer approach has served the AI field well—but it also has a drawback. If you want to model anything that transforms continuously over time, you also have to chunk it up into discrete steps. In practice, if we returned to the health example, that would mean grouping your medical records into finite periods like years or months. You could see how this would be inexact. If you went to the doctor on January 11 and again on November 16, the data from both visits would be grouped together under the same year.
So the best way to model reality as close as possible is to add more layers to increase the granularity. (Why not break your records up into days or even hours? You could have gone to the doctor twice in one day!) Taken to the extreme, this means the best neural network for this job would have an infinite number of layers to model infinitesimal step-changes. The question is whether this idea is even practical.
If this is starting to sound familiar, that’s because we have arrived at exactly the kind of problem that calculus was invented to solve. Calculus gives you all these nice equations for how to calculate a series of changes across infinitesimal steps—in other words, it saves you from the nightmare of modeling continuous change in discrete units. This is the magic of Duvenaud and his collaborators’ paper: it replaces the layers with calculus equations.
The result is really not even a network anymore; there are no more nodes and connections, just one continuous slab of computation. Nonetheless, sticking with convention, the researchers named this design an “ODE net”—ODE for “ordinary differential equations.” (They still need to work on their branding.)
If your brain hurts (trust me, mine does too), here’s a nice analogy that Duvenaud uses to tie it all together. Consider a continuous musical instrument like a violin, where you can slide your hand along the string to play any frequency you want; now consider a discrete one like a piano, where you have a distinct number of keys to play a limited number of frequencies. A traditional neural network is like a piano: try as you might, you won’t be able to play a slide. You will only be able to approximate the slide by playing a scale. Even if you retuned your piano so the note frequencies were really close together, you would still be approximating the slide with a scale. Switching to an ODE net is like switching your piano to a violin. It’s not necessarily always the right tool, but it is more suitable for certain tasks.
In addition to being able to model continuous change, an ODE net also changes certain aspects of training. With a traditional neural net, you have to specify the number of layers you want in your net at the start of training, then wait until the training is done to find out how accurate the model is. The new method allows you to specify your desired accuracy first, and it will find the most efficient way to train itself within that margin of error. On the flip side, you know from the start how much time it will take a traditional neural net to train. Not so much when using an ODE net. These are the trade-offs that researchers will have to make, explains Duvenaud, when they decide which technique to use in the future.
Currently, the paper offers a proof of concept for the design, “but it’s not ready for prime time yet,” Duvenaud says. Like any initial technique proposed in the field, it still needs to fleshed out, experimented on, and improved until it can be put into production. But the method has the potential to shake up the field—in the same way that Ian Goodfellow did when he published his paper on GANs.
“Many of the key advances in the field of machine learning have come in the area of neural networks,” says Richard Zemel, the research director at the Vector Institute, who was not involved in the paper. “The paper will likely spur a whole range of follow-up work, particularly in time-series models, which are foundational in AI applications such as health care.”
Just remember that when ODE nets blow up, you read about it here first.
Corrections: An earlier version of the article incorrectly captioned the image at the top of the article as an ordinary differential equation. It shows the trajectories of neural ordinary differential equations. The article has also been updated to refer to the new design as an "ODE net" rather than "ODE solver," to avoid confusion with existing ODE solvers from other fields.
__
This article originally appeared in our AI newsletter The Algorithm. To have it delivered directly to your inbox, subscribe here for free.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.