A machine has figured out Rubik’s Cube all by itself
Yet another bastion of human skill and intelligence has fallen to the onslaught of the machines. A new kind of deep-learning machine has taught itself to solve a Rubik’s Cube without any human assistance.
The milestone is significant because the new approach tackles an important problem in computer science—how to solve complex problems when help is minimal.
First some background. The Rubik’s Cube is a three-dimensional puzzle developed in 1974 by the Hungarian inventor Erno Rubik, the object being to align all squares of the same color on the same face of the cube. It became an international best-selling toy and sold over 350 million units.
The puzzle has also attracted considerable interest from computer scientists and mathematicians. One question that has intrigued them is the smallest number of moves needed to solve it from any position. The answer, proved in 2014, turns out to be 26.
Another common challenge is to design algorithms that can solve the cube from any position. Rubik himself, within a month of inventing the toy, came up with an algorithm that could do this.
But attempts to automated the process have all relied on algorithms that have been hand-crafted by humans.
More recently, computer scientists have tried to find ways for machines to solve the problem themselves. One idea is to use the same kind of approach that has been so successful with games like chess and Go.
In these scenarios, a deep-learning machine is given the rules of the game and then plays against itself. Crucially, it is rewarded at each step according to how it performs. This reward process is hugely important because it helps the machine to distinguish good play from bad play. In other words, it helps the machine learn.
But this doesn’t work in many real-world situations, because rewards are often rare or hard to determine.
For example, random turns of a Rubik’s Cube cannot easily be rewarded, since it is hard to judge whether the new configuration is any closer to a solution. And a sequence of random turns can go on for a long time without reaching a solution, so the end-state reward can only be offered rarely.
In chess, by contrast, there is a relatively large search space but each move can be evaluated and rewarded accordingly. That just isn’t the case for the Rubik’s Cube.
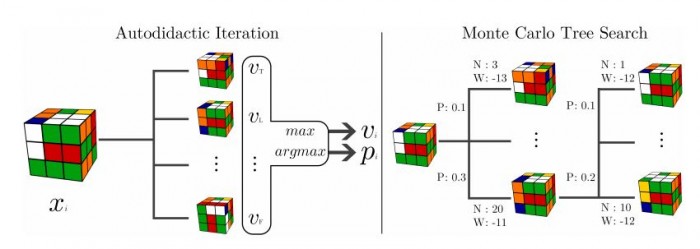
Enter Stephen McAleer and colleagues from the University of California, Irvine. These guys have pioneered a new kind of deep-learning technique, called “autodidactic iteration,” that can teach itself to solve a Rubik’s Cube with no human assistance. The trick that McAleer and co have mastered is to find a way for the machine to create its own system of rewards.
Here’s how it works. Given an unsolved cube, the machine must decide whether a specific move is an improvement on the existing configuration. To do this, it must be able to evaluate the move.
Autodidactic iteration does this by starting with the finished cube and working backwards to find a configuration that is similar to the proposed move. This process is not perfect, but deep learning helps the system figure out which moves are generally better than others.
Having been trained, the network then uses a standard search tree to hunt for suggested moves for each configuration.
The result is an algorithm that performs remarkably well. “Our algorithm is able to solve 100% of randomly scrambled cubes while achieving a median solve length of 30 moves—less than or equal to solvers that employ human domain knowledge,” say McAleer and co.
That’s interesting because it has implications for a variety of other tasks that deep learning has struggled with, including puzzles like Sokoban, games like Montezuma’s Revenge, and problems like prime number factorization.
Indeed, McAleer and co have other goals in their sights: “We are working on extending this method to find approximate solutions to other combinatorial optimization problems such as prediction of protein tertiary structure.”
Whether these problems will be as amenable to this approach is not clear. They do not generally benefit from a proof that they can be solved in a small number of moves, as the Rubik’s Cube problem does. That undoubtedly worked in the team’s favor here.
McAleer and co argue that their approach is a form of reasoning about problems. They point out that one definition of reasoning is: “algebraically manipulating previously acquired knowledge in order to answer a new question.”
They say that this is exactly what their algorithm—called DeepCube—does. By contrast, conventional deep-learning machines simply recognize certain patterns. “DeepCube is able to teach itself how to reason in order to solve a complex environment with only one reward state using pure reinforcement learning,” they say.
Perhaps. The real test, of course, will be how this approach copes with more complex problems such as protein folding. We’ll be watching to see how it does.
Ref: arxiv.org/abs/1805.07470 : Solving the Rubik's Cube Without Human Knowledge
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.