Machine-Learning Algorithm Can Show Whether State Secrets Are Properly Classified
The U.S. State Department generates some two billion e-mails every year. A significant fraction of these contain sensitive or secret information and so have to be classified, a process that is time-consuming and costly. In 2015 alone, it spent $16 billion to protect classified information.
But the reliability of this process of classification is unclear. Nobody knows whether the rules for classifying information are applied consistently and reliably. Indeed, there is significant dispute over what even constitutes information that should be classified.
What’s more, it’s easy to imagine that human error plays a considerable role in the misclassification of official secrets. But nobody knows how significant these errors might be.
Today that changes thanks to the work of Renato Rocha Souza at the Brazilian think tank Fundação Getulio Vargas in Rio De Janeiro and colleagues at Columbia University in New York. These guys have used a machine-learning algorithm to study over a million declassified State Department cables from the 1970s.
Their work provides an unprecedented insight into the nature of official secrets, how humans apply the rules, and how often errors creep into the process to reveal sensitive information or hide otherwise innocuous details. The algorithms also reveal suspicious patterns in the way cables go missing.
The team began with a corpus of a million cables, which they downloaded from the U.S. National Archives in the form of XML files. Each cable is a text message exchanged between the State Department and a diplomatic mission in a foreign country such as an embassy or consulate.
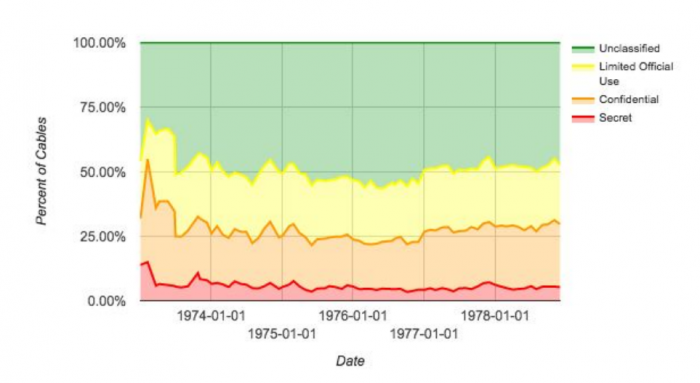
The cables are labelled as “secret,” “confidential,” “limited official use,” or as “unclassified.” Secret information is defined as having the potential to seriously damage national security, confidential information is defined as having the potential to cause damage but not serious damage. The Limited Official Use category was undefined in the 1970s and even today remains controversial.
The cables also contain other information. Each message has a date, a sender and receiver, a subject and, of course, the message text.
Souza and co used a variety of machine-learning approaches to determine how these factors correlate with the classification label. And having discovered this correlation, they then tested the algorithm to see how well it could predict whether a given cable was classified or not.
The results make for interesting reading. Souza and co say that the message itself is the best indicator of whether a cable is classified. “Of all the features, the relative frequency of different words in the body was the most useful in identifying sensitive information,” they say. The sender and recipient data is also a good indicator of the level of sensitivity but can lead the algorithm to classify many cables that were not classified as ones that were. In other words, this leads to a high rate of false positives.
When the machine-learning algorithm combines the various kinds of metadata in its decisions, it can spot some 90 percent of cables that are classified, with a false positive rate of just 11 percent. And Souza and co say it should be possible to do better if cables that are still classified were included.
False positives and false negatives are themselves interesting. These are cables that the machine predicted would be classified but weren’t and vice versa. In many cases, the machine revealed cables that had been misclassified by humans. One example is a cable about Japanese government sensitivity over U.S. inspections of its nuclear facilities. This cable was unclassified, but should have been since the text reveals that it was originally confidential, the researchers say.
One limitation of the data is that many cables have been lost, ostensibly because of problems converting them into an electronic format. Perhaps the most interesting aspect of this work is that it suggests that these messages may have gone missing for other reasons.
One clue is the rate at which the messages disappeared, which differ for classified and unclassified cables. “Electronic messages classified as ‘Secret’ were more than three times more likely to go missing compared to Unclassified and Limited Official Use messages,” say Souza and co.
What’s more, the metadata associated with the cables often survives when the electronic message has been lost. How this could have happened is a puzzle.
Also, if the messages were lost when they were converted from one format to another, they would be most likely to go missing when the State Department set up its new data storage system. “It’s notable that most of these [missing] cables do not date to when the State Department first set up the system, when one might expect it would have been troubleshooting ways to reliably transfer data between different hardware and software platforms,” say the team.
The work has important implications for the balance between transparency and secrecy. Machines can clearly help to monitor the practice of classifying data. But they cannot do this any better on average than the databases from which they learn. If these contain errors, as the State Department’s cables clearly do, the machines will inevitably be hamstrung.
But an interesting question is whether the data that this kind of machine learning reveals should itself be classified if it reveals patterns of behavior that could be damaging to the national interest. For example, the rate at which confidential information is erroneously labeled as unclassified could be useful for a foreign power attempting to gather classified information from unclassified cables.
Clearly there is more work to be done. Souza and co say that despite the State Department’s huge spending on protecting classified information, there is little or no published research on the consistency of classification. Neither is there much understanding of just how much this kind of machine learning can reveal.
Perhaps all this work is being done behind closed doors. On the other hand, perhaps not.
Ref: arxiv.org/abs/1611.00356: Using Artificial Intelligence to Identify State Secrets
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.