The Extraordinary Link Between Deep Neural Networks and the Nature of the Universe
In the last couple of years, deep learning techniques have transformed the world of artificial intelligence. One by one, the abilities and techniques that humans once imagined were uniquely our own have begun to fall to the onslaught of ever more powerful machines. Deep neural networks are now better than humans at tasks such as face recognition and object recognition. They’ve mastered the ancient game of Go and thrashed the best human players.
But there is a problem. There is no mathematical reason why networks arranged in layers should be so good at these challenges. Mathematicians are flummoxed. Despite the huge success of deep neural networks, nobody is quite sure how they achieve their success.
Today that changes thanks to the work of Henry Lin at Harvard University and Max Tegmark at MIT. These guys say the reason why mathematicians have been so embarrassed is that the answer depends on the nature of the universe. In other words, the answer lies in the regime of physics rather than mathematics.
First, let’s set up the problem using the example of classifying a megabit grayscale image to determine whether it shows a cat or a dog.
Such an image consists of a million pixels that can each take one of 256 grayscale values. So in theory, there can be 2561000000 possible images, and for each one it is necessary to compute whether it shows a cat or dog. And yet neural networks, with merely thousands or millions of parameters, somehow manage this classification task with ease.
In the language of mathematics, neural networks work by approximating complex mathematical functions with simpler ones. When it comes to classifying images of cats and dogs, the neural network must implement a function that takes as an input a million grayscale pixels and outputs the probability distribution of what it might represent.
The problem is that there are orders of magnitude more mathematical functions than possible networks to approximate them. And yet deep neural networks somehow get the right answer.
Now Lin and Tegmark say they’ve worked out why. The answer is that the universe is governed by a tiny subset of all possible functions. In other words, when the laws of physics are written down mathematically, they can all be described by functions that have a remarkable set of simple properties.
So deep neural networks don’t have to approximate any possible mathematical function, only a tiny subset of them.
To put this in perspective, consider the order of a polynomial function, which is the size of its highest exponent. So a quadratic equation like y=x2 has order 2, the equation y=x24 has order 24, and so on.
Obviously, the number of orders is infinite and yet only a tiny subset of polynomials appear in the laws of physics. “For reasons that are still not fully understood, our universe can be accurately described by polynomial Hamiltonians of low order,” say Lin and Tegmark. Typically, the polynomials that describe laws of physics have orders ranging from 2 to 4.
The laws of physics have other important properties. For example, they are usually symmetrical when it comes to rotation and translation. Rotate a cat or dog through 360 degrees and it looks the same; translate it by 10 meters or 100 meters or a kilometer and it will look the same. That also simplifies the task of approximating the process of cat or dog recognition.
These properties mean that neural networks do not need to approximate an infinitude of possible mathematical functions but only a tiny subset of the simplest ones.
There is another property of the universe that neural networks exploit. This is the hierarchy of its structure. “Elementary particles form atoms which in turn form molecules, cells, organisms, planets, solar systems, galaxies, etc.,” say Lin and Tegmark. And complex structures are often formed through a sequence of simpler steps.
This is why the structure of neural networks is important too: the layers in these networks can approximate each step in the causal sequence.
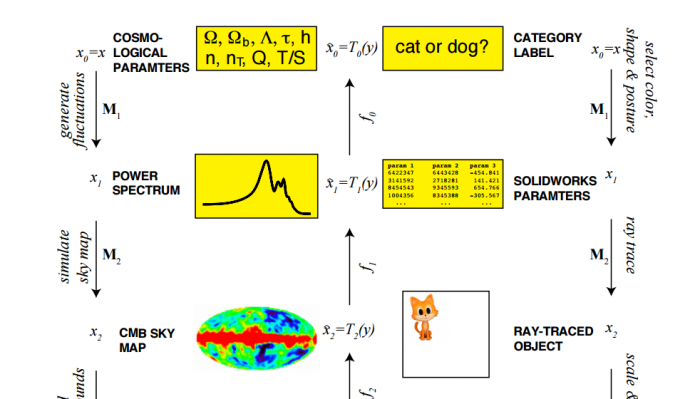
Lin and Tegmark give the example of the cosmic microwave background radiation, the echo of the Big Bang that permeates the universe. In recent years, various spacecraft have mapped this radiation in ever higher resolution. And of course, physicists have puzzled over why these maps take the form they do.
Tegmark and Lin point out that whatever the reason, it is undoubtedly the result of a causal hierarchy. “A set of cosmological parameters (the density of dark matter, etc.) determines the power spectrum of density fluctuations in our universe, which in turn determines the pattern of cosmic microwave background radiation reaching us from our early universe, which gets combined with foreground radio noise from our galaxy to produce the frequency-dependent sky maps that are recorded by a satellite-based telescope,” they say.
Each of these causal layers contains progressively more data. There are only a handful of cosmological parameters but the maps and the noise they contain are made up of billions of numbers. The goal of physics is to analyze the big numbers in a way that reveals the smaller ones.
And when phenomena have this hierarchical structure, neural networks make the process of analyzing it significantly easier.
“We have shown that the success of deep and cheap learning depends not only on mathematics but also on physics, which favors certain classes of exceptionally simple probability distributions that deep learning is uniquely suited to model,” conclude Lin and Tegmark.
That’s interesting and important work with significant implications. Artificial neural networks are famously based on biological ones. So not only do Lin and Tegmark’s ideas explain why deep learning machines work so well, they also explain why human brains can make sense of the universe. Evolution has somehow settled on a brain structure that is ideally suited to teasing apart the complexity of the universe.
This work opens the way for significant progress in artificial intelligence. Now that we finally understand why deep neural networks work so well, mathematicians can get to work exploring the specific mathematical properties that allow them to perform so well. “Strengthening the analytic understanding of deep learning may suggest ways of improving it,” say Lin and Tegmark.
Deep learning has taken giant strides in recent years. With this improved understanding, the rate of advancement is bound to accelerate.
Ref: arxiv.org/abs/1608.08225: Why Does Deep and Cheap Learning Work So Well?
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.