Google’s new version of Gemini can handle far bigger amounts of data
The updated AI model can now do some seriously impressive things with long videos or text.
Google DeepMind today launched the next generation of its powerful artificial-intelligence model Gemini, which has an enhanced ability to work with large amounts of video, text, and images.
It’s an advancement from the three versions of Gemini 1.0 that Google announced back in December, ranging in size and complexity from Nano to Pro to Ultra. (It rolled out Gemini 1.0 Pro and 1.0 Ultra across many of its products last week.) Google is now releasing a preview of Gemini 1.5 Pro to select developers and business customers. The company says that the mid-tier Gemini 1.5 Pro matches its previous top-tier model, Gemini 1.0 Ultra, in performance but uses less computing power (yes, the names are confusing!).
Crucially, the 1.5 Pro model can handle much larger amounts of data from users, including bigger prompts. While every AI model has a ceiling on how much data it can digest, the standard version of the new Gemini 1.5 Pro can handle inputs as large as 128,000 tokens, which are words or parts of words that an AI model breaks inputs into. That’s on a par with the best version of GPT-4 (GPT-4 Turbo).
However, a limited group of developers will be able to submit up to 1 million tokens to Gemini 1.5 Pro, which equates to roughly one hour of video, 11 hours of audio, or 700,000 words of text. That’s a significant jump that makes it possible to do things that no other models are currently capable of.
In one demonstration video shown by Google, using the million-token version, researchers fed the model a 402-page transcript of the Apollo moon landing mission. Then they showed Gemini a hand-drawn sketch of a boot, and asked it to identify the moment in the transcript that the drawing represents.
“This is the moment Neil Armstrong landed on the moon,” the chatbot responded correctly. “He said, ‘One small step for man, one giant leap for mankind.’”
The model was also able to identify moments of humor. When asked by the researchers to find a funny moment in the Apollo transcript, it picked out when astronaut Mike Collins referred to Armstrong as “the Czar.” (Probably not the best line, but you get the point.)
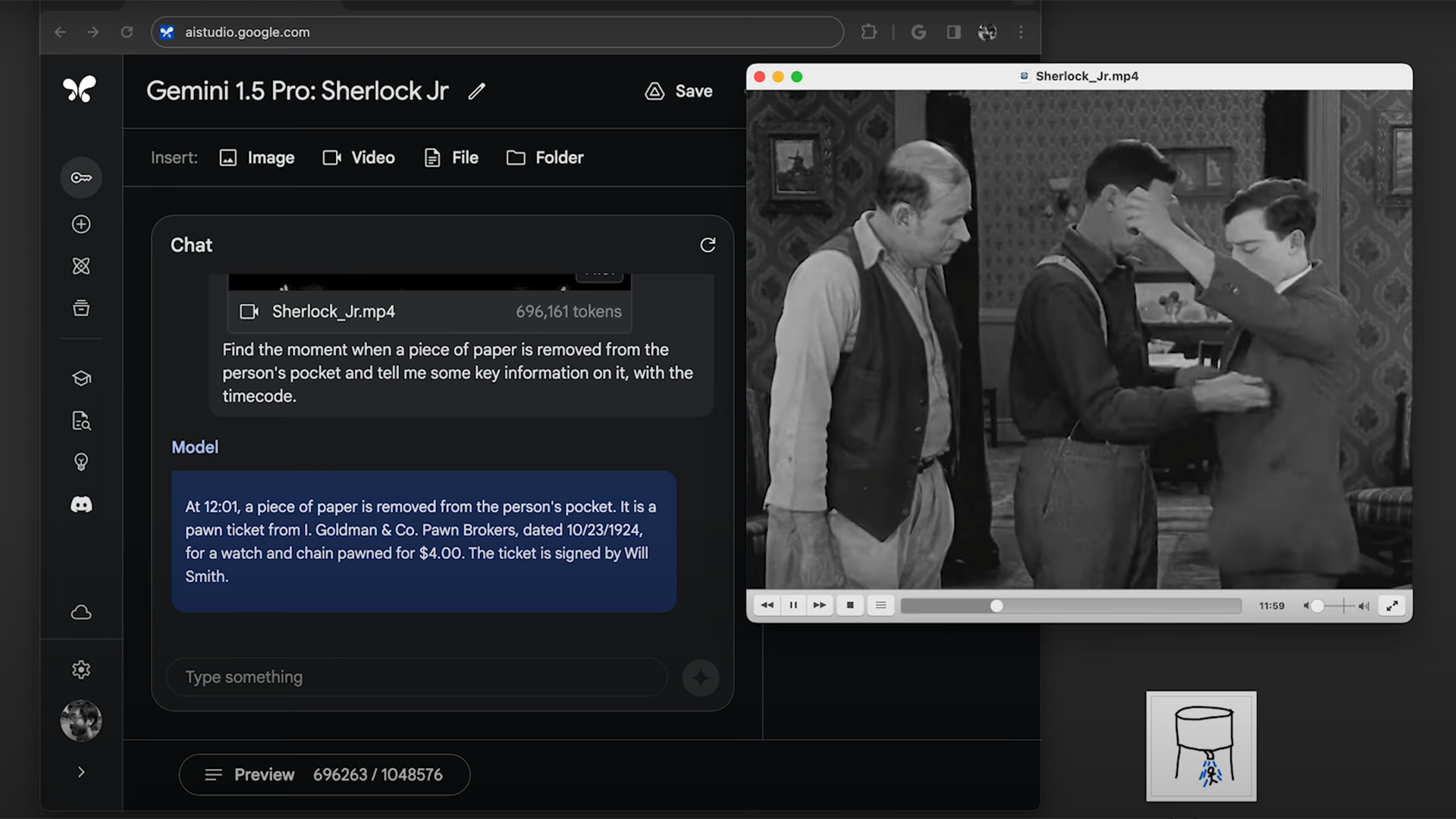
In another demonstration, the team uploaded a 44-minute silent film featuring Buster Keaton and asked the AI to identify what information was on a piece of paper that, at some point in the movie, is removed from a character’s pocket. In less than a minute, the model found the scene and correctly recalled the text written on the paper. Researchers also repeated a similar task from the Apollo experiment, asking the model to find a scene in the film on the basis of a drawing. It completed this task too.
Google says it put Gemini 1.5 Pro through the usual battery of tests it uses when developing large language models, including evaluations that combine text, code, images, audio, and video. It found that 1.5 Pro outperformed 1.0 Pro on 87% of the benchmarks and more or less matched 1.0 Ultra across all of them while using less computing power.
The ability to handle larger inputs, Google says, is a result of progress in what’s called mixture-of-experts architecture. An AI using this design divides its neural network into chunks, activating only the parts that are relevant to the task at hand rather than firing up the whole network at once. (Google is not alone in using this architecture; the French AI firm Mistral released a model using it, and GPT-4 is rumored to employ the tech as well.)
“In one way it operates much like our brain does, where not the whole brain activates all the time,” says Oriol Vinyals, a deep learning team lead at DeepMind. This compartmentalizing saves the AI computing power and can generate responses faster.
“That kind of fluidity going back and forth across different modalities, and using that to search and understand, is very impressive,” says Oren Etzioni, former technical director of the Allen Institute for Artificial Intelligence, who was not involved in the work. “This is stuff I have not seen before.”
An AI that can operate across modalities would more closely resemble the way that human beings behave. “People are naturally multimodal,” Etzioni says; we can effortlessly switch between speaking, writing, and drawing images or charts to convey ideas.
Etzioni cautioned against taking too much meaning from the developments, however. “There’s a famous line,” he says. “Never trust an AI demo.”
For one thing, it’s not clear how much the demonstration videos left out or cherry-picked from various tasks (Google indeed received criticism for its early Gemini launch for not disclosing that the video was sped up). It’s also possible the model would not be able to replicate some of the demonstrations if the input wording were slightly tweaked. AI models in general, says Etzioni, are brittle.
Today’s release of Gemini 1.5 Pro is limited to developers and enterprise customers. Google did not specify when it will be available for wider release.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.