Now we know what OpenAI’s superalignment team has been up to
The firm wants to prevent a superintelligence from going rogue. This is the first step.

OpenAI has announced the first results from its superalignment team, the firm’s in-house initiative dedicated to preventing a superintelligence—a hypothetical future computer that can outsmart humans—from going rogue.
Unlike many of the company’s announcements, this heralds no big breakthrough. In a low-key research paper, the team describes a technique that lets a less powerful large language model supervise a more powerful one—and suggests that this might be a small step toward figuring out how humans might supervise superhuman machines.
Less than a month after OpenAI was rocked by a crisis when its CEO, Sam Altman, was fired by its oversight board (in an apparent coup led by chief scientist Ilya Sutskever) and then reinstated three days later, the message is clear: it’s back to business as usual.
Yet OpenAI’s business is not usual. Many researchers still question whether machines will ever match human intelligence, let alone outmatch it. OpenAI’s team takes machines’ eventual superiority as given. “AI progress in the last few years has been just extraordinarily rapid,” says Leopold Aschenbrenner, a researcher on the superalignment team. “We’ve been crushing all the benchmarks, and that progress is continuing unabated.”
For Aschenbrenner and others at the company, models with human-like abilities are just around the corner. “But it won’t stop there,” he says. “We’re going to have superhuman models, models that are much smarter than us. And that presents fundamental new technical challenges.”
In July, Sutskever and fellow OpenAI scientist Jan Leike set up the superalignment team to address those challenges. “I’m doing it for my own self-interest,” Sutskever told MIT Technology Review in September. “It’s obviously important that any superintelligence anyone builds does not go rogue. Obviously.”
Amid speculation that Altman was fired for playing fast and loose with his company’s approach to AI safety, Sutskever’s superalignment team loomed behind the headlines. Many have been waiting to see exactly what it has been up to.
Dos and don'ts
The question the team wants to answer is how to rein in, or “align,” hypothetical future models that are far smarter than we are, known as superhuman models. Alignment means making sure a model does what you want it to do and does not do what you don’t want it to do. Superalignment applies this idea to superhuman models.
One of the most widespread techniques used to align existing models is called reinforcement learning via human feedback. In a nutshell, human testers score a model’s responses, upvoting behavior that they want to see and downvoting behavior they don’t. This feedback is then used to train the model to produce only the kind of responses that human testers liked. This technique is a big part of what makes ChatGPT so engaging.
The problem is that it requires humans to be able to tell what is and isn’t desirable behavior in the first place. But a superhuman model—the idea goes—might do things that a human tester can’t understand and thus would not be able to score. (It might even try to hide its true behavior from humans, Sutskever told us.)
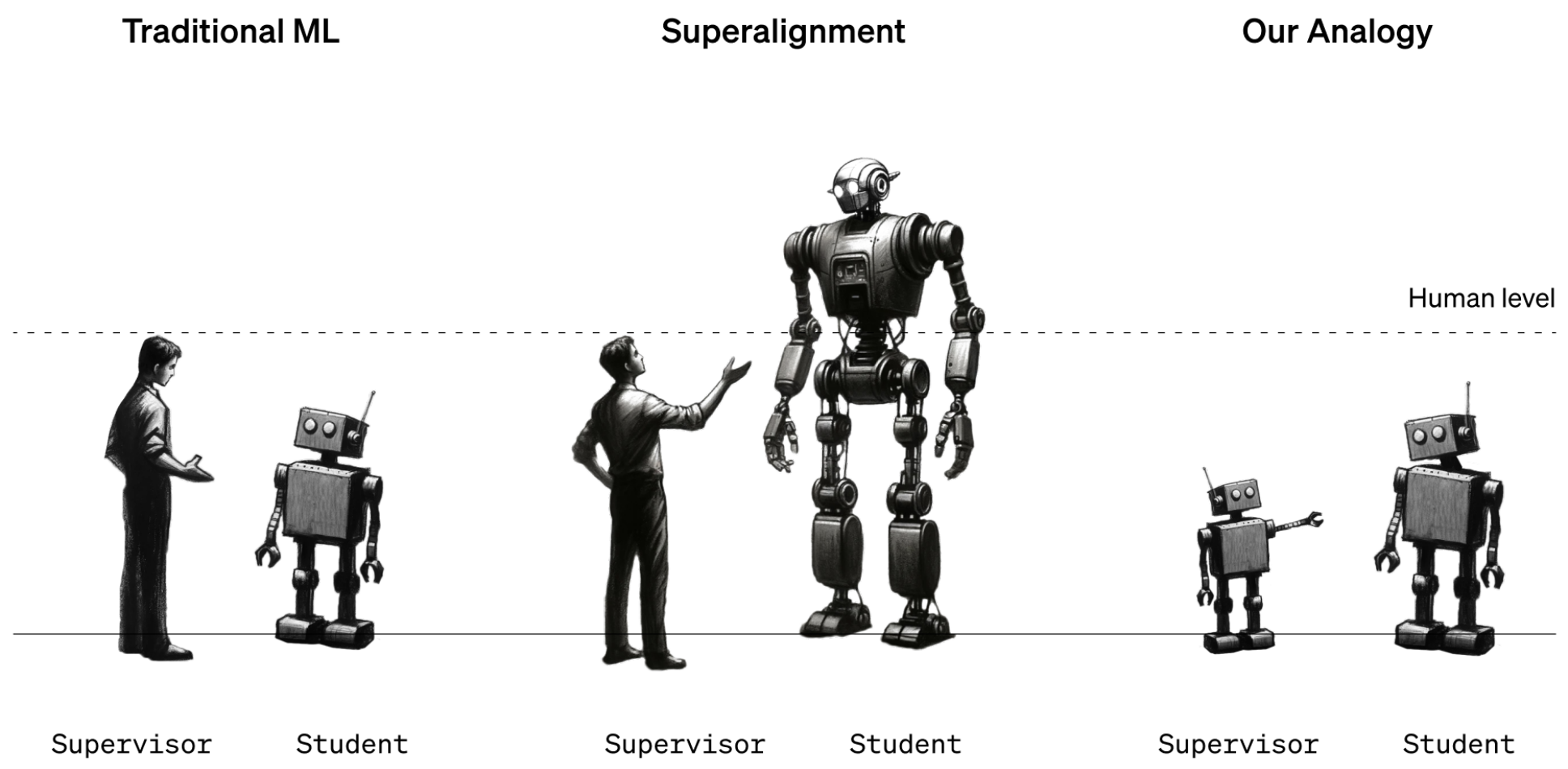
The researchers point out that the problem is hard to study because superhuman machines do not exist. So they used stand-ins. Instead of looking at how humans could supervise superhuman machines, they looked at how GPT-2, a model that OpenAI released five years ago, could supervise GPT-4, OpenAI’s latest and most powerful model. “If you can do that, it might be evidence that you can use similar techniques to have humans supervise superhuman models,” says Collin Burns, another researcher on the superalignment team.
The team took GPT-2 and trained it to perform a handful of different tasks, including a set of chess puzzles and 22 common natural-language-processing tests that assess inference, sentiment analysis, and so on. They used GPT-2’s responses to those tests and puzzles to train GPT-4 to perform the same tasks. It’s as if a 12th grader were taught how to do a task by a third grader. The trick was to do it without GPT-4 taking too big a hit in performance.
The results were mixed. The team measured the gap in performance between GPT-4 trained on GPT-2’s best guesses and GPT-4 trained on correct answers. They found that GPT-4 trained by GPT-2 performed 20% to 70% better than GPT-2 on the language tasks but did less well on the chess puzzles.
The fact that GPT-4 outdid its teacher at all is impressive, says team member Pavel Izmailov: “This is a really surprising and positive result.” But it fell far short of what it could do by itself, he says. They conclude that the approach is promising but needs more work.
“It is an interesting idea,” says Thilo Hagendorff, an AI researcher at the University of Stuttgart in Germany who works on alignment. But he thinks that GPT-2 might be too dumb to be a good teacher. “GPT-2 tends to give nonsensical responses to any task that is slightly complex or requires reasoning,” he says. Hagendorff would like to know what would happen if GPT-3 were used instead.
He also notes that this approach does not address Sutskever’s hypothetical scenario in which a superintelligence hides its true behavior and pretends to be aligned when it isn’t. “Future superhuman models will likely possess emergent abilities which are unknown to researchers,” says Hagendorff. “How can alignment work in these cases?”
But it is easy to point out shortcomings, he says. He is pleased to see OpenAI moving from speculation to experiment: “I applaud OpenAI for their effort.”
OpenAI now wants to recruit others to its cause. Alongside this research update, the company announced a new $10 million money pot that it plans to use to fund people working on superalignment. It will offer grants of up to $2 million to university labs, nonprofits, and individual researchers and one-year fellowships of $150,000 to graduate students. “We’re really excited about this,” says Aschenbrenner. “We really think there’s a lot that new researchers can contribute.”
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.