Random Image Experiment Reveals The Building Blocks of Human Imagination
Here’s a curious experiment. Take some white noise and use it to produce a set of images that are essentially random arrangements of different coloured blocks. Show these images to a number of people and ask whether any of the images remind them of, say, a car.
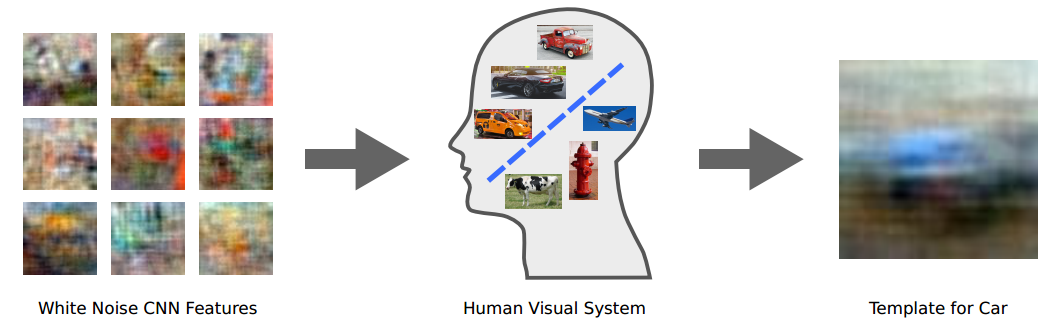
Most of the time, these random images will appear to people as, well, random. But every now and again somebody will say that an image does remind them of a car. Set this image aside. And repeat.
After assessing, say, 100,000 images in this way, you’ll end up with a set of essentially random pictures that remind people of cars. Take the average of these and you will find something interesting. The resulting image does indeed look like a blurry car, not a specific kind of car but a very general template of one.
“Although our dataset consists of only white noise, a car emerges,” say Carl Vondrick and pals at the Massachusetts Institute of Technology in Cambridge, who carried out the research.
Today, these guys say that this process extracts the visual template that the human brain uses to distinguish objects such as cars from not-cars. And because this process is based on noise and imagination alone, Vondrick and co say it provides a unique insight into the nature of human imagination.
The experimental details are relatively straightforward. Vondrick and co use the noise-based process to generate datasets consisting of 100,000 images. They then asked workers on Amazon’s Mechanical Turk to classify each image as a car or not. They carry out various quality assurance tests so that they include only results from the best performing workers.
In separate tests, they also ask workers to find images of people, televisions, bottles, sports balls and so on. In each case, when the selected images are averaged, a blurry template of these objects emerge.
One of the interesting discoveries Vondrick and co have made is that there are cultural differences between imaginations formed in different parts of the world. For example, ask people in India to pick out images that remind them of a sports ball and the resulting template is a red circular blur. But ask people from the US to do the same exercise and the result is an orange/brown blur.
The difference is easy to explain. In India, the most popular sport is cricket which is played with a red ball. But in the US, the most popular sports are American football and basketball, which are played with orange or brown balls. Clearly, the cultural landscape has an important impact on human imagination.
One bizarre finding is that when the team asked people from Singapore to identify cars, the resulting template appears to show a car as viewed from the front. By contrast, people in US produced a template showing a car from the side. Just why this is so, is not yet clear.
Yet the results are more than merely curious. Vondrick and co have used the templates to train machine vision algorithms and say the results significantly outperform other training mechanisms. For example, a machine vision algorithm trained with a single imaginative template of a car is much better at recognising cars in other images than the same algorithm trained with a single ordinary image of a car.
That is fascinating work that provides an important insight into the nature of the human mind. It also provides an important new way to train machine vision algorithms to behave more like humans.
One extraordinary feature of imagination is that it allows humans to visualise objects they have never seen. Computers are still a long way from this but the work of Vondrick and co could be an important stepping stone. “Our hope is that our ideas will inspire future work on building machines with the ability to imagine new visual concepts just like a human,” say the team.
Ref: arxiv.org/abs/1410.4627 : Acquiring Visual Classifiers from Human Imagination
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.