Facebook Creates Software That Matches Faces Almost as Well as You Do
Asked whether two unfamiliar photos of faces show the same person, a human being will get it right 97.53 percent of the time. New software developed by researchers at Facebook can score 97.25 percent on the same challenge, regardless of variations in lighting or whether the person in the picture is directly facing the camera.
That’s a significant advance over previous face-matching software, and it demonstrates the power of a new approach to artificial intelligence known as deep learning, which Facebook and its competitors have bet heavily on in the past year (see “Deep Learning”). This area of AI involves software that uses networks of simulated neurons to learn to recognize patterns in large amounts of data.
“You normally don’t see that sort of improvement,” says Yaniv Taigman, a member of Facebook’s AI team, a research group created last year to explore how deep learning might help the company (see “Facebook Launches Advanced AI Effort”). “We closely approach human performance,” says Taigman of the new software. He notes that the error rate has been reduced by more than a quarter relative to earlier software that can take on the same task.
Facebook’s new software, known as DeepFace, performs what researchers call facial verification (it recognizes that two images show the same face), not facial recognition (putting a name to a face). But some of the underlying techniques could be applied to that problem, says Taigman, and might therefore improve Facebook’s accuracy at suggesting whom users should tag in a newly uploaded photo.
However, DeepFace remains purely a research project for now. Facebook released a research paper on the project last week, and the researchers will present the work at the IEEE Conference on Computer Vision and Pattern Recognition in June. “We are publishing our results to get feedback from the research community,” says Taigman, who developed DeepFace along with Facebook colleagues Ming Yang and Marc’Aurelio Ranzato and Tel Aviv University professor Lior Wolf.
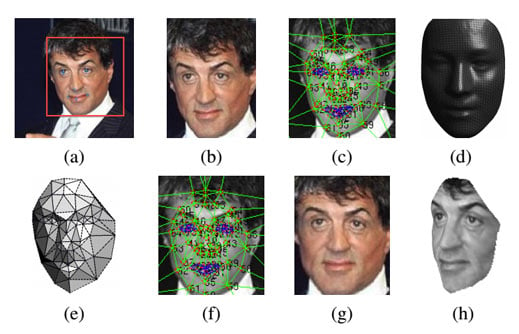
DeepFace processes images of faces in two steps. First it corrects the angle of a face so that the person in the picture faces forward, using a 3-D model of an “average” forward-looking face. Then the deep learning comes in as a simulated neural network works out a numerical description of the reoriented face. If DeepFace comes up with similar enough descriptions from two different images, it decides they must show the same face.
The performance of the final software was tested against a standard data set that researchers use to benchmark face-processing software, which has also been used to measure how humans fare at matching faces.
Neeraj Kumar, a researcher at the University of Washington who has worked on face verification and recognition, says that Facebook’s results show how finding enough data to feed into a large neural network can allow for significant improvements in machine-learning software. “I’d bet that a lot of the gain here comes from what deep learning generally provides: being able to leverage huge amounts of outside data in a much higher-capacity learning model,” he says.
The deep-learning part of DeepFace consists of nine layers of simple simulated neurons, with more than 120 million connections between them. To train that network, Facebook’s researchers tapped a tiny slice of data from their company’s hoard of user images—four million photos of faces belonging to almost 4,000 people. “Since they have access to lots of data of this form, they can successfully train a high-capacity model,” says Kumar.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.