Sponsored
Build a modern application with purpose-built AWS databases
Provided byAmazon Web Services
The days of one-size-fits-all, monolithic databases are behind us. As Werner Vogels, CTO and vice president of Amazon.com, said, “Seldom can one database fit the needs of multiple distinct use cases.” In the past, web applications were constructed by using the LAMP stack (Linux, Apache, MySQL, and PHP), where a single database was used for many different experiences. In contrast, today’s web applications from customers such as Expedia, Airbnb, and Capital One do not use a single database—they use several different types of databases.
Indeed, developers today build highly distributed applications using a multitude of purpose-built databases. In a sense, developers are doing what they do best—dividing complex applications into smaller pieces—which allows them to choose the right tool for the right job.
In this blog post, we discuss AWS purpose-built databases and how to use them to create rich experiences for your customers. We also walk through a detailed example of these databases powering different experiences in an application, and provide the tools you need to spin up the app for yourself in minutes.
AWS customers tell us they want to build scalable, high-performing, and functional applications that have specific performance and business needs. Over the last several years, we have responded to these customer needs by introducing new services such as Amazon Neptune for graph databases, Amazon Aurora for fully managed, commercial-grade relational databases, as well as an ever-improving feature set such as Amazon Aurora Serverless. At AWS re:Invent 2018, AWS announced several new additions and features to our family of purpose-built databases:
- Amazon Quantum Ledger Database (QLDB), a purpose-built ledger database.
- Amazon Timestream, a time-series database service for internet-of-things (IoT) and operational applications.
- Amazon DynamoDB on-demand capacity mode, a billing option that lets you pay for only the resources you consume.
- Amazon Aurora Global Database, spanning multiple AWS regions while replicating writes with a typical latency of less than one second.
In January 2019, AWS announced Amazon DocumentDB (with MongoDB compatibility). With these additions, developers have a choice of relational, key-value, document, in-memory, search, graph, time-series, and ledger databases to fit their individual use cases. Each of these databases is built to be the right tool for the right job.
How AWS customers are using purpose-built databases
How are AWS customers leveraging all of these purpose-built databases together? At AWS re:Invent 2018, we presented Databases on AWS: The Right Tool for the Right Job. In this session, we discussed how AWS customers are using different databases together to deliver rich, end-to-end experiences for their customers.
We showed a demo in the session that provides a real-world example of how customers build applications by using purpose-built architecture on AWS. The demonstration outlines how a web storefront (in this case, a bookstore) is built on top of multiple databases, each addressing a different use case. A clip of the demo follows, starting at 21:43.
How to address different use cases with different purpose-built databases
The preceding clip showcased an online bookstore demo application (see the following screenshot). As with any modern, full-stack web application, this application has multiple different use cases, including a product catalog, product search, best sellers list, and social recommendations.
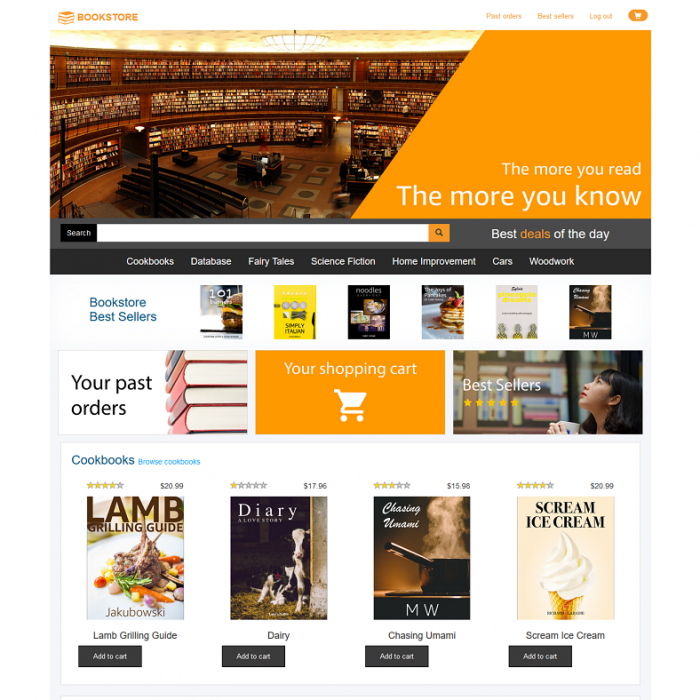
Figure 1: A screenshot of the AWS Bookstore Demo App
Let’s start with the product catalog use case. When a user accesses the bookstore’s web storefront, they might expect to see a list of products. Products typically contain unique identifiers and attributes such as descriptions, quantities, locations, and prices. In a technical sense, the method for retrieving these types of attributes is often a key-value lookup based on the product’s unique identifier. This means that an application can retrieve these other attributes when a product’s unique identifier is provided. This use case makes Amazon DynamoDB a great fit as the durable system of record for the bookstore’s product catalog because DynamoDB provides fast, predictable performance at any scale for key-value lookups. With DynamoDB, the product catalog can start off with a few hundred products and scale to billions of products without having to rearchitect or change databases.
The second use case is to enable customers to search the product catalog. When customers come to the bookstore they want to locate the product they intend to buy or search through the catalog to find their next great read. In today’s world, users are trained to be efficient with keyword searches to find what they are looking for. Amazon Elasticsearch Service (Amazon ES) is a database technology that solves these user needs. With natural-language capabilities, faceted navigation, and ranked results, Amazon ES helps customers quickly find the items they want in the product catalog.
The bookstore application needs to keep the product catalog (in DynamoDB) in sync with the search index in Amazon ES. Whenever a product is added, updated, or removed from the catalog’s product table in DynamoDB, the change also needs to be reflected in the search index in Amazon ES. One easy way to do this is to use Amazon DynamoDB Streams with AWS Lambda to asynchronously update the Amazon ES index every time a change is made to the product catalog in DynamoDB.
The third use case is a best sellers list for the product catalog that will enable the bookstore’s users to see what the “top 20” purchased books are. For this experience, the ideal database allows the bookstore to maintain a leaderboard without having to do long and expensive summation queries across all purchases every time a user refreshes the web page. Amazon ElastiCache for Redis provides exactly what is needed, including built-in, in-memory data structures such as sorted sets that allow the bookstore to create a best sellers list quickly and effectively. To get it running, the bookstore can use DynamoDB Streams (similar to the product search use case) from the orders table to update the latest status in ElastiCache every time a new item is purchased. With the best sellers list available, the bookstore can show a part of it on its website’s homepage as well. Plus, because the data is in-memory and available through the built-in sorted sets, the bookstore will experience microsecond read latencies for queries on the best sellers list.
The fourth use case is to provide social recommendations to help the bookstore’s customers find more contextually appropriate content—in this case, content based on what their friends have purchased. Because social recommendations are on the bookstore’s homepage and other pages on the site, the recommendations have to be fast. Also, as the website grows, the solution needs to scale with more products, pages, and users. With these requirements, a purpose-built graph database such as Amazon Neptune is a natural fit to navigate links in the data, enabling recommendations that are based on social connections and related purchase activity. Neptune provides the needed functionality and performance we need to quickly build and execute queries to traverse graph relationships, and it will scale as the website (and application) grows without compromising on performance.
In order to fetch and update all of this information, the web storefront makes a series of different API calls. Here’s a view of what the application looks like in the backend, utilizing Amazon API Gateway and AWS Lambda:
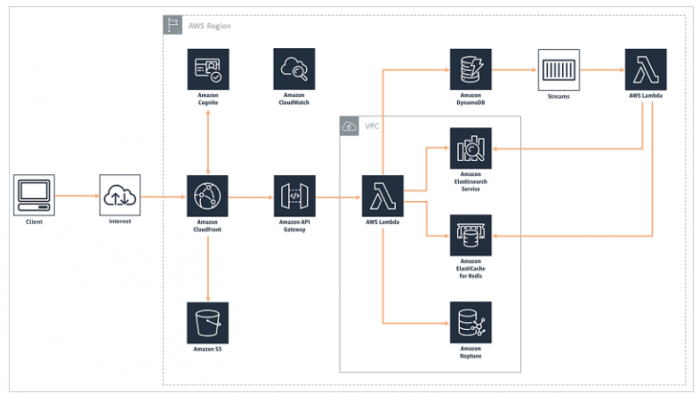
Figure 2: Architectural diagram of the AWS Bookstore Demo App
For this bookstore application, we assessed the application’s main use cases and chose the best database for each use case. Purpose-built databases enable you to create scalable, high-performing, and functional backend infrastructures to power your applications, addressing each use case with the most appropriate component. By following this approach, you can build a similar architecture with your own resources.
Get it up and running
Every customer who creates a web application has to go through almost the exact same process of choosing components, but that is only half the battle. Perhaps more importantly, after choosing their desired architecture, they have to build the stack from scratch, every time. This made us think: why not make the architecture easier to build? With so many customers going through a very similar process, how can we simplify this? For customers who are still in the learning or exploratory phases, how can we help them get a full-stack application up and running in minutes using these purpose-built databases?
To answer these questions, we created a single AWS CloudFormation template to automate the creation of this entire bookstore demo application stack, end-to-end, in just a few minutes. Further, we made all of the source code, images, and sample data available on GitHub for you to deploy, explore, modify, and extend.
Figure 3: The AWS Bookstore Demo App repository on GitHub
As we demonstrated in the re:Invent session, the AWS Bookstore Demo App is a working application that utilizes four purpose-built databases to provide a powerful, functional user experience. You can deploy the application in your AWS account with a few clicks using AWS CloudFormation (for more information, see the readme.md file on GitHub). Once deployed in your account, you can explore the data sets in Amazon DynamoDB, Amazon Elasticsearch, Amazon ElastiCache for Redis, and Amazon Neptune. The readme.md file includes additional steps that walk you through how to do this step by step, along with commentary on how everything fits together. You can use the app as a sandbox or learning tool to explore how an architecture like this fits together, or as a starting template to build your own application.
What if my application requirements are different?
The AWS Bookstore Demo App is just one example of how you can use purpose-built databases to build a scalable and high-performance full-stack application, such as a web storefront. If you want to start with this stack as a baseline but your use case is more fitting for a relational database (like Amazon RDS), you can modify the application to use that, instead. If you want to leverage ElastiCache for caching in front of some of the other database components to improve performance, you can add that as well. In fact, we encourage you to fork our repo and modify the demo application to explore areas that you want to learn more about. You can swap out database types, try different components, and load your own resources and data. If you develop something interesting that you feel would be valuable for others to use, please submit a pull request so that we can extend the demo.
If your application is quite different, but you still are looking for a basic full-stack application to build on top of, the AWS Bookstore Demo App is built on top of AWS Full-Stack Template (also available on GitHub). AWS Full-Stack Template provides the foundational services, components, and plumbing needed to get a basic web application up and running, saving you time and helping you focus on your application’s differentiators. You can build on top of AWS Full-Stack Template to create any application you envision, whether a travel booking tool, a blog, or another web app. The AWS Bookstore Demo App is just one example of what you can create using AWS Full-Stack Template.
The next time you use an application, try to imagine which database is behind the curtains. More than likely, there are several databases (and other services) working in concert together to power your experience. If you want to learn more and start building, take one of these full-stack applications for a spin. We look forward to seeing what you build!
Deep Dive
Computing
How ASML took over the chipmaking chessboard
MIT Technology Review sat down with outgoing CTO Martin van den Brink to talk about the company’s rise to dominance and the life and death of Moore’s Law.
How Wi-Fi sensing became usable tech
After a decade of obscurity, the technology is being used to track people’s movements.
Why it’s so hard for China’s chip industry to become self-sufficient
Chip companies from the US and China are developing new materials to reduce reliance on a Japanese monopoly. It won’t be easy.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.