The Challenges and Threats of Automated Lip Reading
Back in the 16th century, a Spanish Benedictine monk called Pietro Ponce pioneered the seemingly magical art of lip reading. Although the technique probably predates him, Ponce was the first successful lip reading teacher.
Then, as now, the technique was primarily used to help people with hearing difficulties interpret speech. But it is also used by others to eavesdrop on conversations. Indeed, various experiments show that our ability to interpret speech improves when we can see the moving lips of the speaker. In other words, almost everybody uses lip reading to a certain extent.
That raises an interesting question. Can the process of lip reading be automated and performed by computer? And if so, how successful can this approach be and what kind of threat does it pose to privacy?
Today, we get some answers thanks to the work of Ahmad Hassanat at Mu’tah University in Jordan. He outlines the challenges that researchers face in the field of automated lip reading, otherwise known as visual speech recognition. What is clear from his analysis is that if lip reading is going to be successfully automated, significant challenges still need to be overcome.
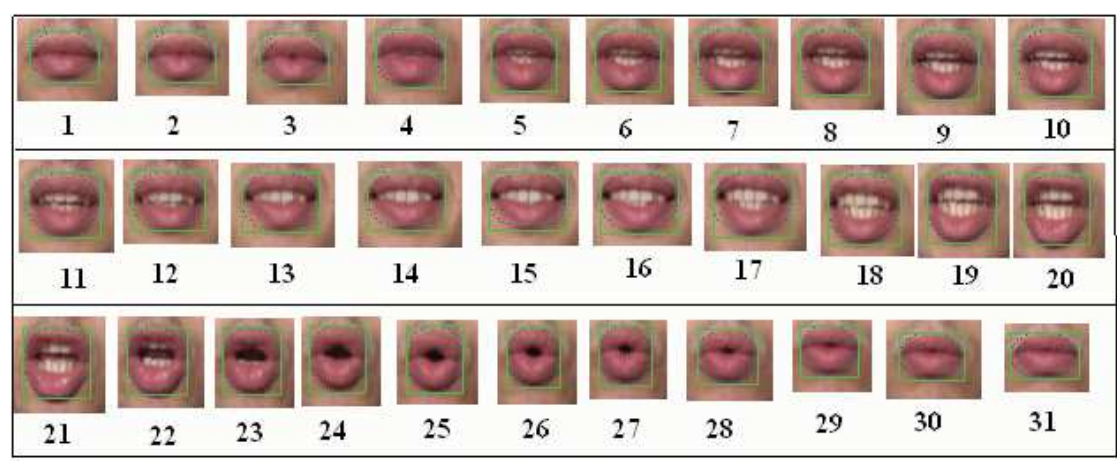
The fundamental process of lip reading is to recognize a sequence of shapes formed by the mouth and then match it to a specific word or sequence of words.
There is a significant challenge here. During speech, the mouth forms between 10 and 14 different shapes, known as visemes. By contrast, speech contains around 50 individual sounds known as phonemes. So a single viseme can represent several different phonemes.
And therein lies the problem. A sequence of visemes cannot usually be associated with a unique word or sequence of words. Instead, a sequence of visemes can have several different solutions. The challenge for the lip reader is to choose the one that the speaker has used.
The problem is compounded by the fact that a speaker’s lips are often obscured so that on average, a lip reader only sees about 50 percent of the spoken words. The result is that lip reading is by no means perfect even for the most experienced practitioners.
Experiments show just how difficult it is, even when vocabulary is hugely limited. when people are asked to decide which of the digits 1 to 9 have been spoken, purely by lip reading, their success rate averages just over 50 percent. Not good at all.
So it is easy to imagine that the prospects for automating this technique are poor. But Hassanat points to a growing body of research that tackles this problem, aided by a rapid improvement in machine vision in recent years.
The first problem for automated lip reading is face and lip recognition. This has improved in leaps and bounds in recent years. A more difficult challenge is in recognizing, extracting and categorizing the geometric features of the lips during speech.
This is done by measuring the height and width of the lips as well as other features such as the shape of the ellipse bounding the lips, the amount of teeth on view and the redness of the image, which determines the amount of tongue that is visible.
Determining the exact contour of the lips is hard because of the relatively small difference between pixels showing face and lips. Indeed, Hassanat says this is not necessary since the bounding ellipse and the height and shape of the mouth provide a decent approximation of the real contours. “We argue that it is not necessary to use all or some of the lip’s contour points to define the outer shape of the lips,” he says.
The experiments he and others have done have found other problems though. One is that beards and mustaches can significantly confuse visual speech recognition systems. Consequently, they are more successful with female than male speakers.
Another problem is that some people are more expressive with their lips than others so it easier to interpret what they are saying from lip movements alone. Indeed, some people hardly move their lips at all and these so-called “visual-speechless persons” are almost impossible to interpret.
Nevertheless, Hassanat’s own visual speech recognition system is remarkably good. His experiments achieve an average success rate of 76 percent, albeit in carefully controlled conditions. The success rate is even higher for women because of the absence of beards and mustaches.
All this suggests that there is significant potential for visual speech recognition systems in the future, particularly as an aid to other forms of speech recognition.
However, important challenges remain. In particular, Hassanat points out that the best human lip readers rely on significant amounts of additional information to interpret speech, such as the context of the conversation, the speaker’s body movements and a good knowledge of grammar, idioms and common speech.
These are factors that computers have yet to get to grips with. Automated lip reading may still be some way off but the early signs are that it is by no means impossible.
And that raises a whole set of other privacy-related issues. For example, it may be that videos of conversations without sound are impossible to interpret now but may be easy to interpret in future. How might politicians, business leaders and popular figures fair under that kind of future analysis?
Something to think about next time you see a CCTV camera.
Ref: arxiv.org/abs/1409.1411: Visual Speech Recognition
Keep Reading
Most Popular
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.