AAD22L: Automatic Acronym Detection in 22 Languages Unveiled in Europe
We’ve all had the experience of reading a report, scientific paper or just a long news article that is ruined by TMUA (Too Many Unnecessary Acronyms). The author introduces one acronym in the first paragraph, others in the second and third paragraphs leading to a final paragraph that is no more than a sequence of incomprehensible capital letters.
Today, we have help thanks to the work of Maud Ehrmann at Sapienza University of Rome in Italy and a few pals who have developed a text analyser that recognises over 1 million acronyms in 22 different languages. The work is part of a broader effort to analyse the content of news stories to keep track of the media’s coverage of organisations, companies, governments and so on.
The task of spotting acronyms in text is relatively simple. These guys have adapted an algorithm that was originally developed to spot acronyms in medical texts in English. It looks for short, upper case expressions in brackets and assumes that the words immediately to the left of the brackets are the long form expansion of the acronym.
The algorithm then filters the results to remove letter sequences that include things like currency symbols and a space after the first letter and so on.
That leads to a few inevitable problems. One occurs when the algorithm fails to recognise the acronym at all. “The major reason for non-recognition are cases where the acronym’s short form is in a different language from the long form, such as in the German Vereinigte Nationen (UNO), where the German long form is followed by the English short form,” say Ehrmann and co.(UNO stands for the Organisation of United Nations, more commonly known as the UN in English.
Another problem is when the algorithm finds the wrong long form version of an acronym. An example of this would be “Charles Otieno (CEO)” and tends to occur with generic acronyms that can be applied to large number of people or organisations.
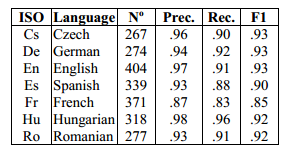
Nevertheless, these issues are minor and the algorithm generally works well. Ehrmann and co say it finds acronyms with a precision greater than 90 per cent for all 22 languages that they tested, withthe exception of French (87 per cent).
And they speculate that it should work well with any language that uses upper case text to represent acronyms. “While we suspect that the method will work well with languages using for instance the Cyrillic or Greek alphabets, it will probably not work well for languages using the Arabic or Hebrew scripts because these do not distinguish case,” they say.
Ehrmann and co have plans to extend the work even further. One idea is to find ways of linking the long forms of acronyms across different languages. Another is to find ways to automatically recognise and understand acronyms that are not accompanied by their long form expansion (a tricky problems even for humans). That might be possible by mining the local context for clues but this is an ambitious goal.
Interestingly, three out of the four authors behind this work are at the Joint Research Centre, the European Commission’s research laboratory in Belgium. Language is a significant and expensive problem for the EC, the executive body of European Union. It must facilitate communication between people in 28 countries using 24 official languages at a cost of around €330 million per year, or about 60 cents for every EU citizen.
So there is considerable interest in automating as much of this as possible. Acronyms are small but useful first step.
Ref: arxiv.org/abs/1309.6185: Acronym Recognition and Processing in 22 Languages
Keep Reading
Most Popular
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.