Facebook has a neural network that can do advanced math
Here’s a challenge for the mathematically inclined among you. Solve the following differential equation for y:
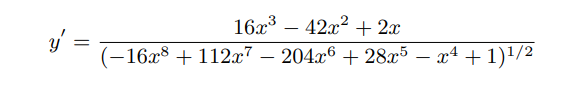
You have 30 seconds. Quick! No dallying.
The answer, of course, is:
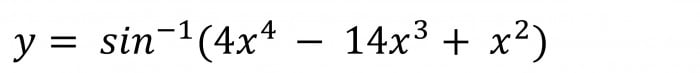
If you were unable to find a solution, don’t feel too bad. This expression is so tricky that even various powerful mathematics software packages failed too, even after 30 seconds of number-crunching.
And yet today, Guillaume Lample and François Charton, at Facebook AI Research in Paris, say they have developed an algorithm that does the job with just a moment’s thought. These guys have trained a neural network to perform the necessary symbolic reasoning to differentiate and integrate mathematical expressions for the first time. The work is a significant step toward more powerful mathematical reasoning and a new way of applying neural networks beyond traditional pattern-recognition tasks.
First, some background. Neural networks have become hugely accomplished at pattern-recognition tasks such as face and object recognition, certain kinds of natural language processing, and even playing games like chess, Go, and Space Invaders.
But despite much effort, nobody has been able to train them to do symbolic reasoning tasks such as those involved in mathematics. The best that neural networks have achieved is the addition and multiplication of whole numbers.
For neural networks and humans alike, one of the difficulties with advanced mathematical expressions is the shorthand they rely on. For example, the expression x3 is a shorthand way of writing x multiplied by x multiplied by x. In this example, “multiplication” is shorthand for repeated addition, which is itself shorthand for the total value of two quantities combined.
It’s easy to see that even a simple mathematical expression is a highly condensed description of a sequence of much simpler mathematical operations.
So it’s no surprise that neural networks have struggled with this kind of logic. If they don’t know what the shorthand represents, there is little chance of their learning to use it. Indeed, humans have a similar problem, often instilled from an early age.
Nevertheless, at the fundamental level, processes like integration and differentiation still involve pattern recognition tasks, albeit hidden by mathematical shorthand.
Enter Lample and Charton, who have come up with an elegant way to unpack mathematical shorthand into its fundamental units. They then teach a neural network to recognize the patterns of mathematical manipulation that are equivalent to integration and differentiation. Finally, they let the neural network loose on expressions it has never seen and compare the results with the answers derived by conventional solvers like Mathematica and Matlab.
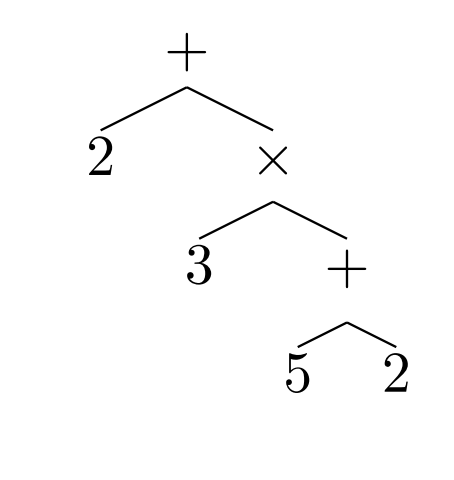
The first part of this process is to break down mathematical expressions into their component parts. Lample and Charton do this by representing expressions as tree-like structures. The leaves on these trees are numbers, constants, and variables like x; the internal nodes are operators like addition, multiplication, differentiate-with-respect-to, and so on.
For example, the expression 2 + 3 x (5+2) can be written as:
And the expression
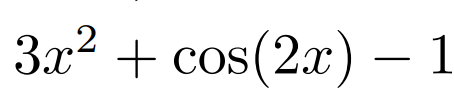
is:
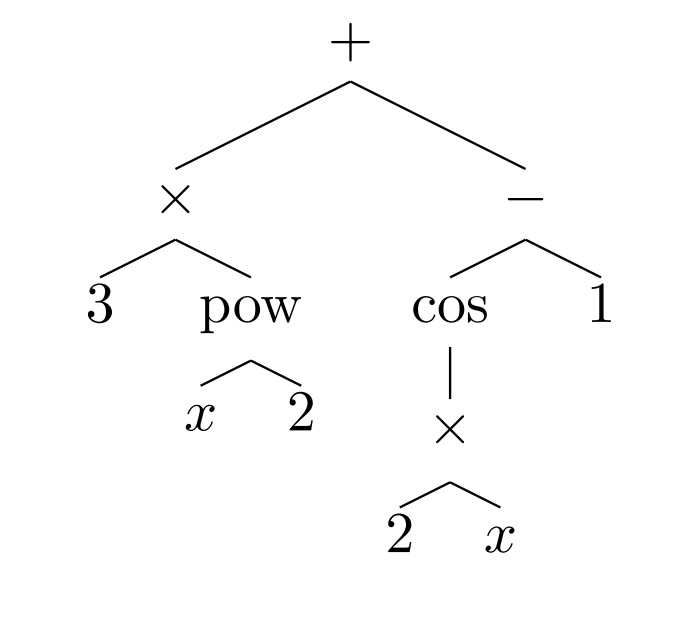
And so on.
Trees are equal when they are mathematically equivalent. For example,
2 + 3 = 5 = 12 - 7 = 1 x 5 are all equivalent; therefore their trees are equivalent too.
Many mathematical operations are easier to handle in this way. “For instance, expression simplification amounts to finding a shorter equivalent representation of a tree,” say Lample and Charton.
These trees can also be written as sequences, taking each node consecutively. In this form, they are ripe for processing by a neural network approach called seq2seq.
Interestingly, this approach is often also used for machine translation, where a sequence of words in one language has to be translated into a sequence of words in another language. Indeed, Lample and Charton say their approach essentially treats mathematics as a natural language.
The next stage is the training process, and this requires a huge database of examples to learn from. Lample and Charton create this database by randomly assembling mathematical expressions from a library of binary operators such as addition, multiplication, and so on; unary operators such as cos, sin, and exp; and a set of variables, integers, and constants, such as π and e. They also limit the number of internal nodes to keep the equations from becoming too big.
Even with relatively small numbers of nodes and mathematical components, the number of possible expressions is vast. Each random equation is then integrated and differentiated using a computer algebra system. Any expression that cannot be integrated is discarded.
In this way, the researchers generate a massive training data set consisting, for example, of 80 million examples of first- and second-order differential equations and 20 million examples of expressions integrated by parts.
By crunching this data set, the neural network then learns how to compute the derivative or integral of a given mathematical expression.
Finally, Lample and Charton put their neural network through its paces by feeding it 5,000 expressions it has never seen before and comparing the results it produces in 500 cases with those from commercially available solvers, such as Maple, Matlab, and Mathematica.
These solvers use an algorithmic approach worked out in the 1960s by the American mathematician Robert Risch. However, Risch’s algorithm is huge, running to 100 pages for integration alone. So symbolic algebra software often uses cut-down versions to speed things up.
The comparisons between these and the neural-network approach are revealing. “On all tasks, we observe that our model significantly outperforms Mathematica,” say the researchers. “On function integration, our model obtains close to 100% accuracy, while Mathematica barely reaches 85%.” And the Maple and Matlab packages perform less well than Mathematica on average.
In many cases, the conventional solvers are unable to find a solution at all, given 30 seconds to try. By comparison, the neural net takes about a second to find its solutions. The example at the top of this page is one of those.
One interesting outcome is that the neural network often finds several equivalent solutions to the same problem. That’s because mathematical expressions can usually be written in many different ways.
This ability is something of a tantalizing mystery for the researchers. “The ability of the model to recover equivalent expressions, without having been trained to do so, is very intriguing,” say Lample and Charton.
That’s a significant breakthrough. “To the best of our knowledge, no study has investigated the ability of neural networks to detect patterns in mathematical expressions,” say the pair.
Now that they have, the result clearly has huge potential in the increasingly important and complex world of computational mathematics.
The researchers do not reveal Facebook’s plans for this approach. But it’s not hard to see how it could offer its own symbolic algebra service that outperforms the market leaders.
However, the competitors are unlikely to sit still. Expect a mighty battle in the world of computational mathematics.
Ref: arxiv.org/abs/1912.01412 : Deep Learning For Symbolic Mathematics
Deep Dive
Computing
How ASML took over the chipmaking chessboard
MIT Technology Review sat down with outgoing CTO Martin van den Brink to talk about the company’s rise to dominance and the life and death of Moore’s Law.
How Wi-Fi sensing became usable tech
After a decade of obscurity, the technology is being used to track people’s movements.
Why it’s so hard for China’s chip industry to become self-sufficient
Chip companies from the US and China are developing new materials to reduce reliance on a Japanese monopoly. It won’t be easy.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.