Linguistics Breakthrough Heralds Machine Translation for Thousands of Rare Languages
The best guess is that humans currently speak about 6,900 different languages. More than half the global population communicates using just a handful of them—Chinese, English, Hindi, Spanish, and Russian. Indeed, 95 percent of people communicate using just 100 languages.
The other argots are much less common. Indeed, linguists estimate that about a third of the world’s languages are spoken by fewer than 1,000 people and are in danger of dying out in the next 100 years or so. With them will go the unique cultural heritage that they embody—stories, phrases, jokes, herbal remedies, and even unique emotions.
It’s easy to think that machine learning can help. The problem is that machine translation relies on huge annotated data sets to ply its trade. These data sets consist of vast corpora of books, articles, and websites that have been manually translated into other languages. This acts like a Rosetta Stone for machine-learning algorithms, and the bigger the data set, the better they learn.
But these huge data sets simply do not exist for most languages. That’s why machine translation works only for a tiny fraction of the most common lingos. Google Translate, for example, only speaks about 90 languages.
So an important challenge for linguists is to find a way to automatically analyze less common languages to better understand them.
Today, Ehsaneddin Asgari and Hinrich Schutze at Ludwig-Maximilian University of Munich in Germany say they have done just that. Their new approach reveals important elements of almost any language that can then be used as a stepping stone for machine translation.
The new technique is based around a single text that has been translated into at least 2,000 different languages. This is the Bible, and linguists have long recognized its importance in their discipline.
Consequently, they have created a database called the Parallel Bible Corpus, which consists of translations of the New Testament in 1,169 languages. This data set is not big enough for the kind of industrial machine learning that Google and others perform. So Asgari and Schutze have come up with another approach based on the way tenses appear in different languages.
Most languages use specific words or letter combinations to signify tenses. So the new trick is to manually identify these signals in several languages and then use data-mining techniques to hunt through other translations looking for words or strings of letters that play the same role.
For example, in English the present tense is signified by the word “is,” the future tense by the word “will,” and the past tense by the word “was.” Of course, there are other signifiers too.
Asgari and Schutze’s idea is to find all these words in the English translation of the Bible along with other examples from a handful other language translations. Then look for words or letters strings that play the same role in other languages. For example, the letter string “-ed” also signifies the past tense in English.
But there is a twist. Asgari and Schutze do not start with English because it is a relatively old language with many exceptions to the rule, which makes it hard to learn.
Instead, they start with a set of Creole languages that have developed from a mixture of other languages. Because they are younger, Creole languages have had less time to develop these linguistic idiosyncrasies. And that means they generally contain better markers of linguistic features such as tense. “Our rationale is that Creole languages are more regular than other languages because they are young and have not accumulated ‘historical baggage’ that may make computational analysis more difficult,” they say.
One of these languages is Seychelles Creole, which uses the word “ti” to signify the past tense. For example, “mon travay” means “I work” in this language, while “mon ti travay” means “I worked” and “mon ti pe travay” means “I was working.” So “ti” is a good signifier of past tense.
Asgari and Schutze compile a list of past tense signifiers in 10 other languages and then mine the Parallel Bible Corpus for other words and letter strings that perform the same function. They repeat this for the present tense and future tense.
The results make for interesting reading. The technique reveals linguistics constructions related to tense in common languages such as “-ed” in English and “-te” in German, as well as the words and phrases that perform the same functions in much less common languages such as the past tense signifier “den” in the Gourmanchema language from Burkino Faso, and “yi” in Yalunka, spoken in Mali, and so on.
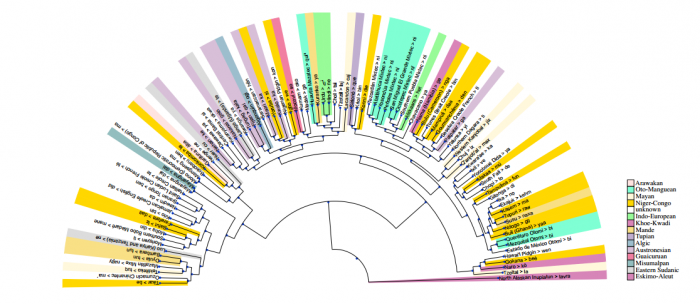
This work allows the researchers to create maps showing how languages using similar tense constructions are related (see diagram).
That’s interesting work. Asgari and Schutze have developed a computational method to analyze the way people use the past, present, and future tense in over 1,000 languages. This is the largest cross-language computational study ever undertaken. Indeed, the number of languages involved is an order of magnitude greater than in other studies.
The work has significant application. The language tense maps allow the researchers to quickly work out the relations between languages and how they are connected. That could be used to better understand the evolution of language.
And the same approach could also be used for other linguistic features. “We only require that a linguistic feature is overtly marked in a few of thousands of languages as opposed to requiring that it be marked in all languages under investigation,” say Asgari and Schutze.
The implications go further. Computational linguistics has had a profound impact on our understanding of language, the way it varies around the world and how machines can understand it. This emerging discipline has made it possible to automatically translate many languages directly into others in written and spoken form. Indeed, the promise is that instantaneous machine translation will soon match and then outperform the ability of human interpreters.
But the utility of machine translation for certain languages makes them more popular at the expense of languages that are not catered for. That’s why machine translation could hasten the demise of endangered languages.
Indeed, linguists have seen a similar phenomenon with other forms mass communication, such as satellite TV services. These generally broadcast in a single language, which then becomes more desirable and popular than languages that are not broadcast.
Asgari and Schutze’s work could help to reverse this pattern of decline. Of course, it’s a big step from this work to accurate machine translation, but it is a step in the right direction.
Ref: arxiv.org/abs/1704.08914: Past, Present, Future: A Computational Investigation of the Typology of Tense in 1,000 Languages
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.