Collection of 13,500 Nastygrams Could Advance War on Trolls
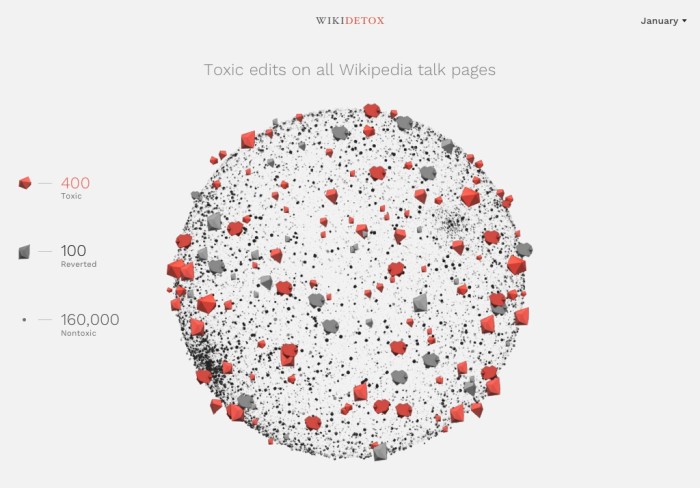
Misogyny, racism, profanity—a collection of more than 13,500 online personal attacks has it all.
The nastygrams came from the discussion pages of Wikipedia. The collection, along with over 100,000 more benign posts, has been released by researchers from Alphabet and the Wikimedia Foundation, the nonprofit behind Wikipedia. They say the data will boost efforts to train software to understand and police online harassment.
“Our goal is to see how can we help people discuss the most controversial and important topics in a productive way all across the Internet,” says Lucas Dixon, chief research scientist at Jigsaw, a group inside Alphabet that builds technology in service of causes such as free speech and fighting corruption (see "If Only AI Could Save Us From Ourselves").
Jigsaw and Wikimedia researchers used a crowdsourcing service to have people comb through more than 115,000 messages posted on Wikipedia discussion pages, checking for any that were a personal attack as defined by the community’s rules. The collaborators have already used the data to train machine-learning algorithms that rival crowdsourced workers at spotting personal attacks. When they ran it through the full collection of 63 million discussion posts made by Wikipedia editors, they found that only around one in 10 attacks had resulted in action by moderators.
Wikimedia Foundation made reducing harassment among Wikipedia editors a priority last year. The policy adds to existing efforts to soften the prickly and bureaucratic atmosphere of the Wikipedia community, which has been found to deter new contributors from participating. Both problems could help explain why it has seen editor numbers slide, and struggled to broaden participation beyond a core male, Western demographic (see “The Decline of Wikipedia”).
Jigsaw and Wikimedia Foundation are not the first to study online abuse, nor are they the first aiming to design software that can detect and fight it. But collections of comments labeled to flag harassing and non-harassing posts—which are needed to train machine-learning software—have been scarce, says Ellery Wulczyn, a data science researcher with Wikimedia Foundation.
He estimates that the collection of personal attacks and comments from Wikipedia is between 10 and 100 times larger than those previously available. Machine-learning algorithms need large numbers of labeled examples to learn how to accurately filter data.
Whether algorithms trained to spot abuse can be deployed as effective moderators is still unclear, though. Software is far from understanding all the nuances of language. Some people may be motivated to tune their abusive language to evade detection, says Wikimedia’s Wulczyn. “If we were to build interventions that humans have an adversarial relationship with, we don’t know what would happen,” he says.
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.