Machine-Learning Algorithm Identifies Tweets Sent Under the Influence of Alcohol
Sending your ex-partner a teary-eyed tweet at 1 a.m. after a bottle of chardonnay isn’t necessarily the best of way of achieving reconciliation. We all know that alcohol and tweeting is not always a good combination.
Yet a surprising number of us indulge in this peculiar form of indiscretion. And this practice has given Nabil Hossain and pals at the University of Rochester an interesting idea.
Today, these guys show how they’ve trained a machine to spot alcohol-related tweets. And they also show how to use this data to monitor alcohol-related activity and the way it is distributed throughout society. They say the method could have a significant impact on the way we understand and respond to the public health issues that alcohol and other activities raise.
Hossain and co’s work is based on two breakthroughs. The first is a way to train a machine-learning algorithm to spot tweets that relate to alcohol and those sent by people drinking alcohol at the time. The second is a way to find a Twitter user’s home location with much greater accuracy than has ever been possible and therefore to determine whether they are drinking at home or not.
The team began by collecting geotagged tweets sent during the year up to July 2014 from New York City and from Monroe County on the northern border of the state, which includes the city of Rochester. From this set, they filter all the tweets that mention alcohol or alcohol-related words, such as drunk, beer, party, and so on.
They then used workers on Amazon’s Mechanical Turk crowdsourcing service to analyze the tweets in more detail. For each tweet, they asked three Turkers to decide whether the message referred to alcohol and if so whether it referred to the tweeter drinking alcohol. Finally, they asked whether the tweet was sent at the same time the tweeter was imbibing.
That process involved some 11,000 geolocated tweets associated with alcohol (although details about the size of this study, and therefore its significance, are sadly lacking from the paper). That’s a big enough data set to train a machine-learning algorithm to spot alcohol-related tweets itself.
That led them to the next question—where are these people when they are tweeting about drinking? And in particular, are they at home or somewhere else?
Researchers have devised various methods for working out people’s home location using only their geolocated tweets. These include choosing the place they tweet from most, choosing the place they send the last tweet of the day from, or the place they tweet from between and 1 a.m. and 6 a.m. However, all of these methods have weaknesses that make them difficult to rely on.
Hossain and co developed another approach. They drew up a list of words and phrases people are likely to use in tweets sent from their homes, such as “Finally home!” or bath, sofa, TV, and so on. They filtered geolocated tweets containing these words and asked three Turkers whether they thought each tweet was sent from home or not, keeping only those for which the three Turkers all answered yes.
Hossain and co designated these tweets as a ground truth data set for home location and used it to train a machine-learning algorithm to identify other patterns associated with home-based tweets. The algorithm looked to see how home location is correlated with other indicators such as location of the last tweet of the day, the most popular location of a tweet, the percentage of tweets from a certain location, and so on.
Relying on several indicators to determine home location significantly improves the accuracy of the approach, compared to those that use a single indicator. Indeed, Hossain and co say they can work out home location to within 100 meters with an accuracy of up to 80 percent. That’s significantly better than previous work.
Together, these two techniques allowed the team to work out when and where people are drinking. And they used this to compare drinking patterns in New York City and in the suburban area of Monroe county.
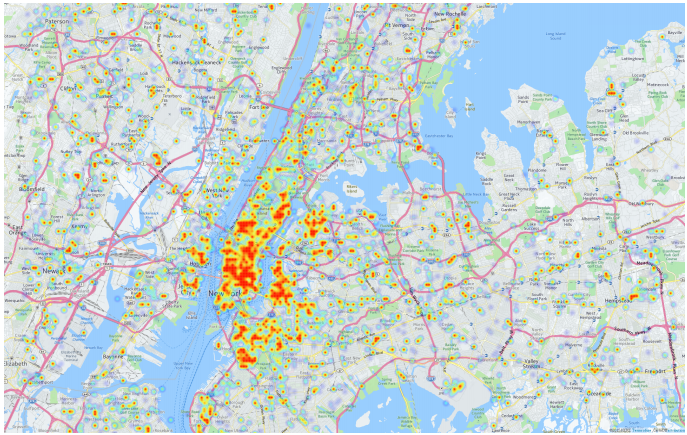
They do this by dividing each area into 100 x 100 grids and marking those areas where there are tweets associated with alcohol. That allows them to draw up and compare “heat maps” of alcohol use for each area.
They also distinguish tweets about drinking made from a home location from those made elsewhere. And they map out the outlets selling alcohol in each area. That allows the researchers to investigate the relationship between the density of tweets sent from different regions while intoxicated and the density of alcohol outlets.
The results make for interesting reading. First, Hossain and co point out that a higher proportion of tweets in New York City are associated with alcohol than in Monroe County. “One possible explanation is that a crowded city such as NYC with highly dense alcohol outlets and many people socializing is likely to have a higher rate of drinking,” they say.
What’s more, the geolocation data reveals that a higher proportion of people drink at home (or within 100 meters of home) in New York City than in Monroe County, where a high proportion of people drink further than a kilometer from home.
The heat maps also reveal interesting patterns. It allows the team to home in on 100 x 100 meter grid squares where there have been at least five tweets about alcohol. “We believe that such grids are regions of unusual drinking activities,” say Hossain and co.
They also found a correlation between the density of alcohol outlets in a region and the number of tweets indicating that somebody is drinking now. That raises an interesting question about how correlation and causation are linked in this case. Does a high density of alcohol outlets cause people to drink more? Or do drinkers flock to areas with a high density of alcohol outlets? Of course, this kind of data by itself cannot answer this.
However, the great power of this technique is that it is cheap and quick. By contrast, getting a similar insight into drinking patterns by other means is hugely expensive and time consuming.
It would usually require people to be carefully selected, to fill in preprepared questionnaires and for these to be analyzed in detail. The machine-learning approach could even monitor this activity in real time. “Our results demonstrate that tweets can provide powerful and fine-grained cues of activities going on in cities,” they say.
There are caveats of course. There is a clear bias in data gathered from Twitter since young people and certain minorities are overrepresented. But similar biases are present in other data collecting methods—for example, surveys tend to underrepresent people who don’t want to fill out surveys, such as some immigrants. Identifying and dealing with biases is an important part of all data collecting methods.
Hossain and co have big plans for their technique. In future, they want to study how alcohol consumption varies with age, sex, ethnicity, and so on; how different settings influence drinking-and-tweeting, such as friends’ houses, stadium, park, and so on; and to compare the rate at which drinkers flow into and out of adjacent neighborhoods.
The social aspect of Twitter will be useful, too. “We can explore the social network of drinkers to find out how social interactions and peer pressure in social media influence the tendency to reference drinking,” say Hossain and co.
All that could help to inform the debate about the health-related aspects of alcohol, which is the third largest cause of preventable death in the U.S. That’s 75,000 deaths that alcohol causes each year—a number that puts the significance of this work in perspective compared to the trials and tribulations of love lives.
Ref: arxiv.org/abs/1603.03181 : Inferring Fine-grained Details on User Activities and Home Location from Social Media: Detecting Drinking-While-Tweeting Patterns in Communities
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.