Now AI Machines Are Learning to Understand Stories
Artificial-intelligence techniques are taking the world by storm. Last year, Google’s DeepMind research team unveiled a machine that had taught itself to play arcade video games. Earlier this year, a team of Chinese researchers demonstrated a face-recognition system that outperforms humans, and last week, the Chinese internet giant Baidu revealed a single speech-recognition system capable of transcribing both English and Mandarin Chinese.
Two factors have made this possible. The first is a better understanding of many-layered neural networks and how to fine-tune them for specific tasks. The second is the creation of the vast databases necessary to train these networks.
These databases are hugely important. For face recognition, for example, a neural network needs to see many thousands of real-world images in which faces from all angles, sometimes occluded, are clearly labeled. That requires many hours of human annotation but this is now possible thanks to crowdsourcing techniques and Web services such as Amazon’s Mechanical Turk.
The rapid progress in this area means that much of the low-hanging fruit is being quickly cleaned up—face recognition, object recognition, speech recognition, and so on. However, it is much harder to create databases for more complex reasoning tasks, such as understanding stories.
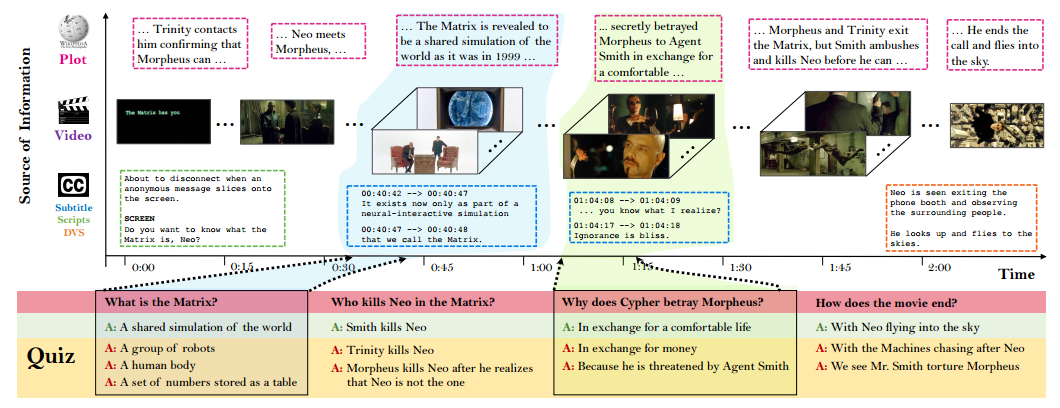
Today, that starts to change thanks to the work of Makarand Tapaswi at the Karlsruhe Institute of Technology in Germany and a few pals, who have put together a database about movies that should serve as a test arena for deep learning machines and their abilities to reason about stories.
The key insight behind their project is that the ability to answer questions about a story or movie is an important indicator of whether or not it has been understood. So the goal of the research is to create multiple choice quizzes about movies that consist of a set of questions along with several feasible answers, only one of which is correct.
Their approach is straightforward. Tapaswi and co begin by gathering plot synopses from Wikipedia for around 300 movies. These vary in detail from a just a single paragraph to over 20 paragraphs.
They link this to the movie itself, which is a substantial body of data. “An average movie is about two hours in length and has over 198K frames and almost 2,000 shots,” they say.
Movies clearly show information that can answer questions of the type “Who did what to whom?” But they do not always contain the information to answer questions about why things happen, for which additional knowledge of the world is sometimes necessary.
So Tapaswi and co also gather information from additional databases. For example, they mine “described video” text for blind people that is designed to contain enough information to understand what is going on without seeing it; and they also mine the original movies scripts which are often useful, although directors do not always follow them exactly.
The team then asked human annotators to choose read the synopses for each movie. They then had to formulate a number of questions about each paragraph they read, along with the answer. On average, the annotators wrote five questions per paragraph. They also had to highlight a section of the text that provided the answer to each question.
Finally, Tapaswi and co asked the annotators to read each question and answer and come up with four wrong answers to create a multiple choice quiz. The resulting database contains over 7,000 questions about 300 films.
The questions fall into several categories. Here are a few examples (guess the movies, if you can):
Person name (who)
Who is Epps attracted to?
What is the nickname of Jeff Lebowski?
Reasoning (why)
Why does Arwen wish to stay in Middle Earth?
Why is Bruce afraid of bats?
Abstract (what)
What power does the green essence contain?
As explained at the hearing, what was the primary cause of the accident?
Reason:action (how)
How does Kale pass the time when he first begins his house arrest sentence?
How does Hal defeat Parallax?
Location (where)
What is the name of the gym where the CD is left behind?
Where does Aragorn lead the Fellowship?
Action (what)
What does WALL-E do once he thinks that EVE has shut down?
What do Jane and Kevin do one year after meeting?
Object/Thing (what)
What does the group find in the trolls’ cave?
What do the men who assault the Dude destroy in his home?
Person type (what)
Who is Daniel Cleaver?
What is Rachel Dawes’s profession?
Yes/No (is, does)
Does Madeleine accept money for her work for Arthur Case?
Is Faramir Denethor’s oldest son?
Causality (what happens)
What does Mark do after Bridget visits him and asks him forgiveness?
What happens during Miley’s date with Travis?
These are relatively straightforward for humans who have watched a film. But these guys test the database on a few simple machine-based question-answering strategies to see how well they fare. None do particularly well but the point, of course, is to help train future generations of these machines that presumably will be better.
That’s a big ask. One interesting point is that deep neural nets need large databases to help them learn. And the more complex the task, the bigger the database needs to be.
So an important question is how big a database needs to be to train a deep learning algorithm to answer question about movies. That’s difficult to answer, even to within an order of magnitude.
So a significant goal will be to find out whether this database is anywhere near big enough to help constrain modern AI machines as they learn to do this task. That’s something Tapaswi and co will soon find out.
In the meantime, they are making the database available online in the new year at: http://movieqa.cs.toronto.edu/home/. If the AI research doesn’t work out, it should at least be useful for pub quizzes.
Ref: http://arxiv.org/abs/1512.02902 : MovieQA: Understanding Stories in Movies through Question-Answering
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.