How Mechanical Turkers Crowdsourced a Huge Lexicon of Links Between Words and Emotion
One of the buzzphrases associated with the social web is sentiment analysis. This is the ability to determine a person’s opinion or state of mind by analysing the words they post on Twitter, Facebook or some other medium.
Much has been promised with this method—the ability to measure satisfaction with politicians, movies and products; the ability to better manage customer relations; the ability to create dialogue for emotion-aware games; the ability to measure the flow of emotion in novels; and so on.
The idea is to entirely automate this process—to analyse the firehose of words produced by social websites using advanced data mining techniques to gauge sentiment on a vast scale.
But all this depends on how well we understand the emotion and polarity (whether negative or positive) that people associate with each word or combinations of words.
Today, Saif Mohammad and Peter Turney at the National Research Council Canada in Ottawa unveil a huge database of words and their associated emotions and polarity, which they have assembled quickly and inexpensively using Amazon’s crowdsourcing Mechanical Turk website. They say this crowdsourcing mechanism makes it possible to increase the size and quality of the database quickly and easily.
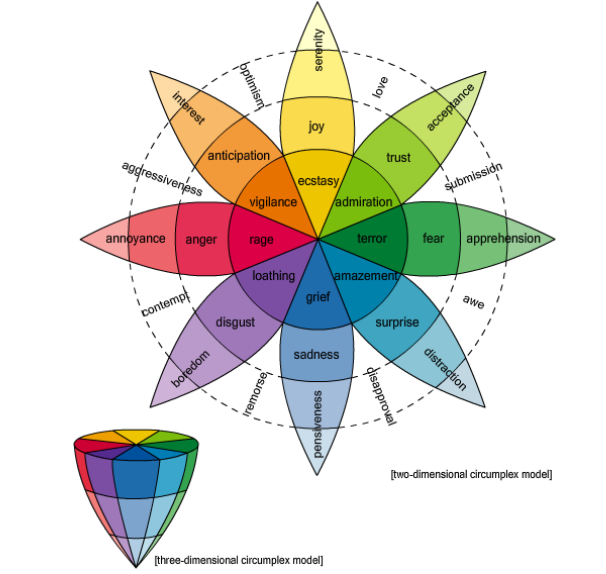
Most psychologists believe that there are essentially six basic emotions– joy, sadness, anger, fear, disgust, and surprise– or at most eight if you include trust and anticipation. So the task of any word-emotion lexicon is to determine how strongly a word is associated with each of these emotions.
One way to do this is to use a small group of experts to associate emotions with a set of words. One of the most famous databases, created in the 1960s and known as the General Inquirer database, has over 11,000 words labelled with 182 different tags, including some of the emotions that psychologist now think are the most basic.
A more modern database is the WordNet Affect Lexicon, which has a few hundred words tagged in this way. This used a small group of experts to manually tag a set of seed words with the basic emotions. The size of this database was then dramatically increased by automatically associating the same emotions with all the synonyms of these words.
One of the problems with these approaches is the sheer time it takes to compile a large database so Mohammad and Turney tried a different approach.
These guys selected about 10,000 words from an existing thesaurus and the lexicons described above and then created a set of five questions to ask about each word that would reveal the emotions and polarity associated with it. That’s a total of over 50,000 questions.
They then asked these questions to over 2000 people, or Turkers, on Amazon’s Mechanical Turk website, paying 4 cents for each set of properly answered questions.
The result is a comprehensive word-emotion lexicon for over 10,000 words or two-word phrases which they call EmoLex.
One important factor in this research is the quality of the answers that crowdsourcing gives. For example, some Turkers might answer at random or even deliberately enter wrong answers.
Mohammad and Turney have tackled this by inserting test questions that they use to judge whether or not the Turker is answering well. If not, all the data from that person is ignored.
They tested the quality of their database by comparing it to earlier ones created by experts and say it compares well. “We compared a subset of our lexicon with existing gold standard data to show that the annotations obtained are indeed of high quality,” they say.
This approach has significant potential for the future. Mohammad and Turney say it should be straightforward to increase the size of the date database and at the same technique can be easily adapted to create similar lexicons in other languages. And all this can be done very cheaply—they spent $2100 on Mechanical Turk in this work.
The bottom line is that sentiment analysis can only ever be as good as the database on which it relies. With EmoLex, analysts have a new tool for their box of tricks.
Ref: arxiv.org/abs/1308.6297: Crowdsourcing a Word-Emotion Association Lexicon
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.