A Startup Hopes to Help Computers Understand Web Pages
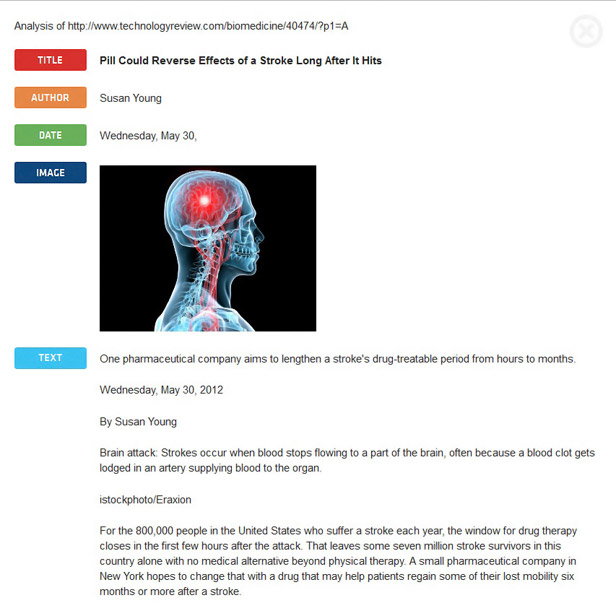
No matter what language you speak, when you look at a Web page, you can get a good idea of the purpose of the different elements on it—whether they’re images, videos, text, music, or ads. It’s not so easy for machines to do the same, though.
That’s where Diffbot hopes to make a difference. The startup, based in Palo Alto, California, offers application programming interfaces that make it possible for machines to “read” the various objects that make up Web pages. This could enable a publisher to repurpose the contents of pages for a mobile app, or help a startup build a price-comparison site.
The company’s efforts come at a time when some tech titans are also working to add more structure to the vast amount of data on the Web. Google, for example, recently unveiled the Knowledge Graph, an effort to identify the meaning of search queries and return relevant results, rather than simply matching the text of a query with Web pages that include the same words. But these efforts usually rely on people to help by tagging Web content to infer meaning.
John Davi, Diffbot’s vice president of product, says that at its heart, the company is about taking the visual learning technology that propels self-driving cars forward on a road and applying it to Web pages.
The idea, which CEO and founder Mike Tung hatched several years ago while he was a graduate student at Stanford, has hummed along since last year. That’s when Diffbot rolled out an API capable of analyzing two types of Web pages on the basis of the URL. On article pages, Diffbot can pick out headlines, the text of articles, pictures, and tags; and on home pages, it can determine basic layout elements like headlines pictures, links to articles, and ads. By now, several thousand programmers are using it to analyze over 100 million URLs each month, Tung says.
There are many more types of Web pages out there, though. The company believes there are roughly 18 main types, ranging from product and job pages to photo galleries. With a $2 million round of funding announced Thursday—its first following an earlier round of seed funding—the company plans to get moving on the 16 other types. This will involve determining what makes up pages of these types—photos, prices, and so on—and using that information to build algorithms that can process unfamiliar pages.
While Diffbot offers its API to customers for free, it charges for high levels of usage. Brad Garlinghouse, the CEO of file-sharing site YouSendIt and an investor in and advisor to Diffbot, says that while the company isn’t currently profitable, it could be without too much trouble.
“They’re solving some here-and-now problems that customers are willing to pay for,” says Garlinghouse.
Currently, a number of Diffbot users are media companies, including Garlinghouse’s previous employer, AOL (Diffbot powers the content aggregation behind AOL’s tablet magazine, Editions). As Davi, of Diffbot, points out, media companies often purchase publications whose online content has been created with a different content-management system. Diffbot’s API can ease the process of consolidating content, he says.
As the company makes it possible to analyze pages of additional types, its founders hope to see Diffbot used for things like product price comparison, photo and recipe aggregation, and more. Tung says, “It’s going to be really exciting to see what people build.”
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.