How to Use Twitter for Personal Data Mining
Your Twitter stream (and, soon, your history of Facebook wall posts) constitutes a rich source of information about you, or, considering that most Tweets are public, just about anyone else. It includes everything from your speech patterns and the topics you obsess over to the identity of your “real” friends–at least in the tweet-o-sphere. The trick is unlocking it.
The first step to jacking into your subconscious is to download a representative sample of your tweets. Fortunately, Twitter stores the last 3,200 of them, which is probably more than you’ve ever spouted, unless you’re especially prolific.

One easy way to download all those tweets is to sign up for a service like BackupMy.Net, which will grab all available tweets (up to that 3,200 limit) and allow you to download them in a number of different formats.
Step two, get yourself a free copy of TextWrangler (if you’re on a Mac) or its Windows equivalent. If you’re on Linux, vi or emacs can do everything I’m about to describe.
Step three, start filtering your corpus of tweets. Think of it as a mound of wet clay. You can ask it any questions you like. Here’s what I asked mine; if you have other ideas, leave them in the comments.
i) Delete every other line in order to eliminate the noise of all those time and date stamps. TextWrangler has a powerful “Process Lines Containing…” feature under the “Text” menu. It allows you to, in this case, delete every line containing the string “+0000” which I’m guessing is the blank variable where geo-location data would normally go. If your Tweets are geo-located, just have it search for every year in which you tweeted, assuming you don’t often drop years into your tweets.
This:

Becomes this:

Now paste the resulting text into Wordle, the word cloud generator, because word clouds are just pretty ways to visualize word frequency.

For a first approximation, it’s not bad - some of your interests and friends can be seen trying to peek out around garbage words we all use on Twitter, like “RT”
ii) Using a simple find and replace command, get rid of RT, via and any other words that don’t tell you anything. Now you can see what you’re obsessed with. I happened to be obsessed with climate change, news buzzwords (“new,” “now”) and, apparently, signaling sarcasm and ironic distance by beginning sentence fragments with the word “apparently.”
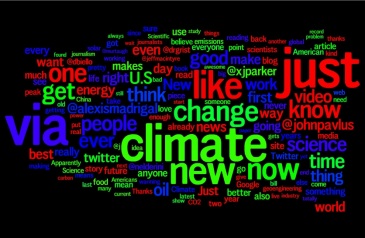
iii) For a purer distillate of your own speech patterns and neuroses, use the “Process Lines Containing…” command or its equivalent to remove all lines that are retweets.

iv) If you want to find out who your “real friends” are on Twitter (and, to a lesser extent, what you talk to them about) extract all the lines that have an @ in them.

If you want to know what you say when you’re talking to your friends, simply delete every word beginning with an @. Or sort the document so you can grab only every conversation you’ve ever had with a particular person, and turn *that* into a word cloud.

v) If you want to know you talk when you’re talking about yourself, simply extract every line with the (case-sensitive) string “I “

There are countless tools on the web for analyzing your twitter stream, from frequency analysis to emotional content, but so far as I know, downloading all your tweets and parsing them yourself is the only way to visualize their actual content with this level of specificity. I’m sure there are dozens of queries I haven’t even thought of that are possible with this method - feel free to leave your ideas in the comments.
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.