Marc Sciamanna
Controlling chaos in telecom lasers.
Problem: Vertical-cavity surface-emitting lasers, or VCSELs, are commonly used in telecommunications networks, but they behave in ways scientists don’t completely understand. Specifically, the polarization of the light they emit–the orientation of its magnetic field–fluctuates unpredictably. Moreover, a little optical feedback, such as light reflected from network equipment, may result in chaotic changes in the power or wavelength of the light emitted by the lasers. Engineers would like to harness all of these fluctuations to increase the data-carrying capacity of light.
Solution: Marc Sciamanna, a professor at the École Supérieure d’Électricité in Paris, has developed a theoretical explanation of the lasers’ chaotic behavior. He has also suggested different techniques for controlling VCSEL polarization and chaotic laser dynamics in general; in particular, he demonstrated that optical feedback can be used to regularize polarization. More recently, he showed that increasing the amount of noise, or random fluctuation, in the electrical current that powers the lasers would make the variations in polarization more predictable and also stabilize the chaotic output. If light polarization and chaotic dynamics were subject to engineers’ control, they could be used to encode digital information–significantly expanding Internet bandwidth.
Sanjit Biswas
Cheap, easy Internet access.
Sanjit Biswas worked on a system for connecting local residents to the Internet wirelessly. In 2006, a nonprofit group asked if the technology could help provide Internet service to the poor. Intrigued, Biswas took a leave of absence to cofound Meraki Networks in Mountain View, CA, and create wireless mesh networks that would link people to the Internet cheaply.
In most mesh networks, all the nodes that receive a particular data packet forward it on; but in Biswas’s version, the nodes “talk” to each other and decide, on the basis of the packet’s destination and their own signal strengths, which one of them should forward it. The protocol also takes into account changing network conditions, as users sign on or off, or, say, a passing truck blocks a node’s radio signal. Biswas’s protocol, combined with commonly available hardware components, allows Meraki to produce Wi-Fi routers that cost as little as $50. (The routers Biswas used at MIT initially cost $1,500.)
Here’s how a Meraki network works: a user plugs a router into a broadband Internet connection; that person’s neighbors stick routers to their windows, and a mesh network of up to hundreds of people forms automatically. Users can give away or sell Internet access to their neighbors. There are already Meraki-based networks in 25 countries, from Slovakia to Venezuela, serving more than 15,000 users.
Josh Bongard
Adaptive robots
Josh Bongard’s robot walks with a limp. But it’s impressive that it walks at all.
As a postdoc at Cornell, Bongard collaborated with roboticist Hod Lipson and PhD student Victor Zykov to develop a robot that can adapt to changes in its body or in the environment–a key advance for robots designed to work outside a controlled laboratory setting. Bongard, now an assistant professor of computer science, begins by programming his robot with basic information about its design, such as the mass and shape of each of its parts. In his standard demonstration, he then disconnects one of its four legs. To get a sense of its handicap, the robot rocks back and forth, activating two tilt sensors. It then builds a virtual model of itself, using simulation software, and uses that model to test new ways of walking despite its handicap. Once the robot has developed a successful simulation, it attempts to walk using the same technique.
Rodney Brooks, professor of robotics at MIT, says that Bongard’s work is interesting because it’s inspired by the way biological systems adapt. To meet roboticists’ future goals of creating self-configuring robots, Brooks says, “these sorts of ideas are going to be essential.”

Garrett Camp
Discovering more of the Web.
In 2001, Garrett Camp and two friends began working–“out of our bedrooms,” he says–on a tool to help people serendipitously discover interesting Web content. Camp, who was then a grad student in software engineering, has guided the research behind the site and the design of its architecture ever since. In May, eBay acquired the Web 2.0 “discovery engine” for approximately $75 million. As of July, more than three million users had downloaded the StumbleUpon toolbar; the simple interface consists of a row of about 15 buttons at the top of a Web browser. Clicking “I like it” when viewing a site amounts to a recommendation; clicking the thumbs-down button submits a negative review. Clicking “Stumble” takes a user to one of more than 10 million sites recommended by friends or other users with similar interests. The system refines individual recommendations on the basis of the user’s previous reviews and the preferences of users whom the site judges to have similar tastes. So what kinds of sites has Camp stumbled upon? Take a sneak peek here.
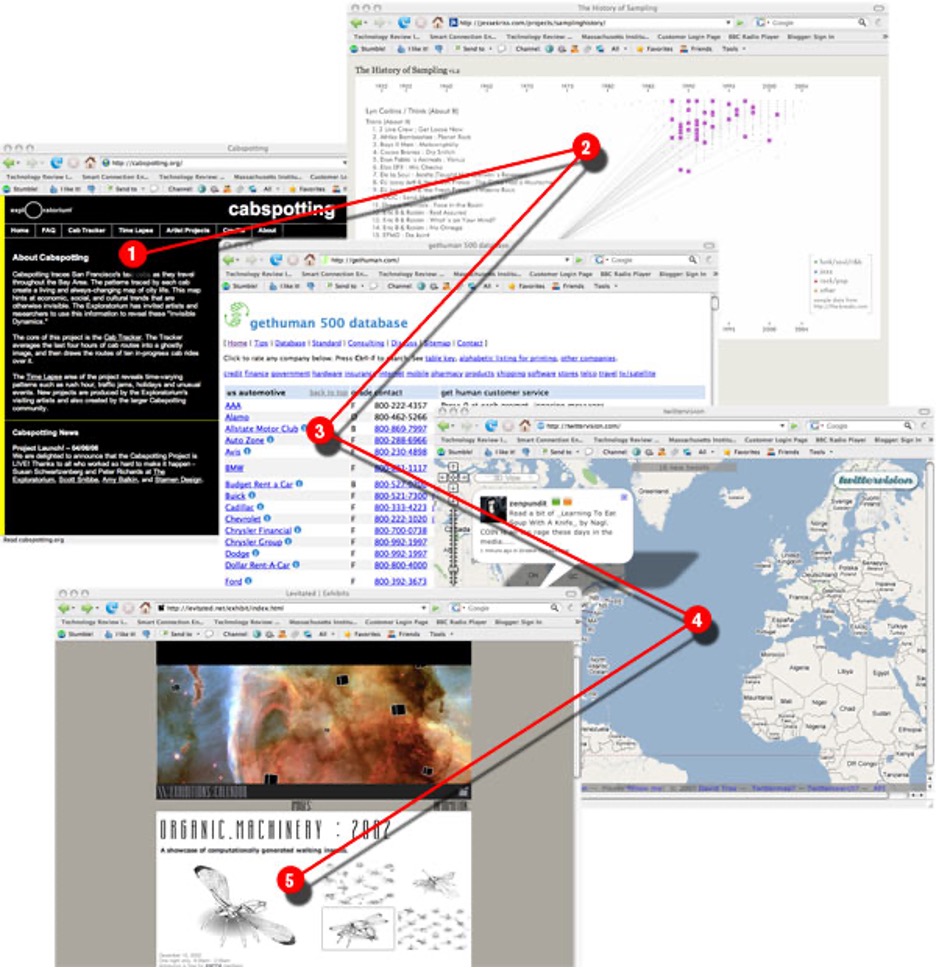
2. jessekriss.com/projects/samplinghistory/ A visual history of audio sampling. A great depiction of how hip-hop and electronic music have sampled from earlier musical forms since the mid-1980s.
3. gethuman.com How to get to a human operator when calling for support. Definitely an example of a site you probably wouldn't search for, but a great find once you stumble upon it.
4. twittervision.com Twittervision is a mashup between the text-message blogging service Twitter and Google Maps. It shows you what people across the globe are blogging from their phones at this moment.
5. levitated.net/exhibit/index.html A visual exploration of computation using Flash. StumbleUpon is great for discovering graphical content such as art, photos, and videos, and this is a perfect example of a graphics-rich site that doesn't contain a lot of keywords you might search for yet is an interesting discovery when you're stumbling through graphics or design sites.
Mung Chiang
Optimizing networks.
Mung Chiang likes to say that there’s nothing more practical than a good theory. An assistant professor of electrical engineering, he improves the design of telecommunications networks by applying the mathematics of optimization theory. Through industry collaborations, his algorithms are revolutionizing the backbone of the Internet, the broadband connections that bring data and video to homes and offices, and wireless networks of every stripe.
In one project, Chiang and coworkers found a way around the limits of the current Internet routing protocol, which sends packets along the shortest available paths on the network. It’s a seemingly straightforward strategy that ends up causing complex network-management problems. The researchers realized there were advantages to sending the occasional packet along a longer path; the new algorithm achieves the lowest computational cost possible for a routing protocol and increases network capacity by 15 percent–without adding equipment to the network.
Though the real-world impact of his work matters to Chiang, he says another important motivation is the beauty of an airtight mathematical proof. “I’m an engineer at heart,” he says, “and a mathematician in my brain.”
Tadayoshi Kohno
Securing systems cryptographically.
Our reliance on the Internet is increasing all the time. Tadayoshi Kohno, an assistant professor of computer science and engineering, worries that even if our data is encrypted, hackers can still glean information about us by working around the codes. For instance, someone tapping into your system might not be able to view the movie you’re watching but could guess its title from properties such as the file size and the compression algorithm used.
So Kohno invented the concept of systems-oriented provable security. Traditionally, cryptologists have assumed that a security protocol is unbreakable if no one they show it to can crack it. But with provable security, they use sophisticated math to show that cracking a given code would require someone to decipher a cryptographic “building block” that’s known to be secure.
Kohno extended this technique to the system level, examining everything from the software that compresses a file to the Internet protocols used to send it. He searches for weak points that might leak identifying information and writes provably secure algorithms to protect them. One of his schemes can handle data transmitted at 10 gigabits per second, the new Internet standard–a rate that overwhelmed previous security protocols. The U.S. government is incorporating a derivative of the scheme into an official encryption standard; Kohno anticipates that banks and corporate networks will use it as well.
Tariq Krim
Building a personal, dynamic Web page.
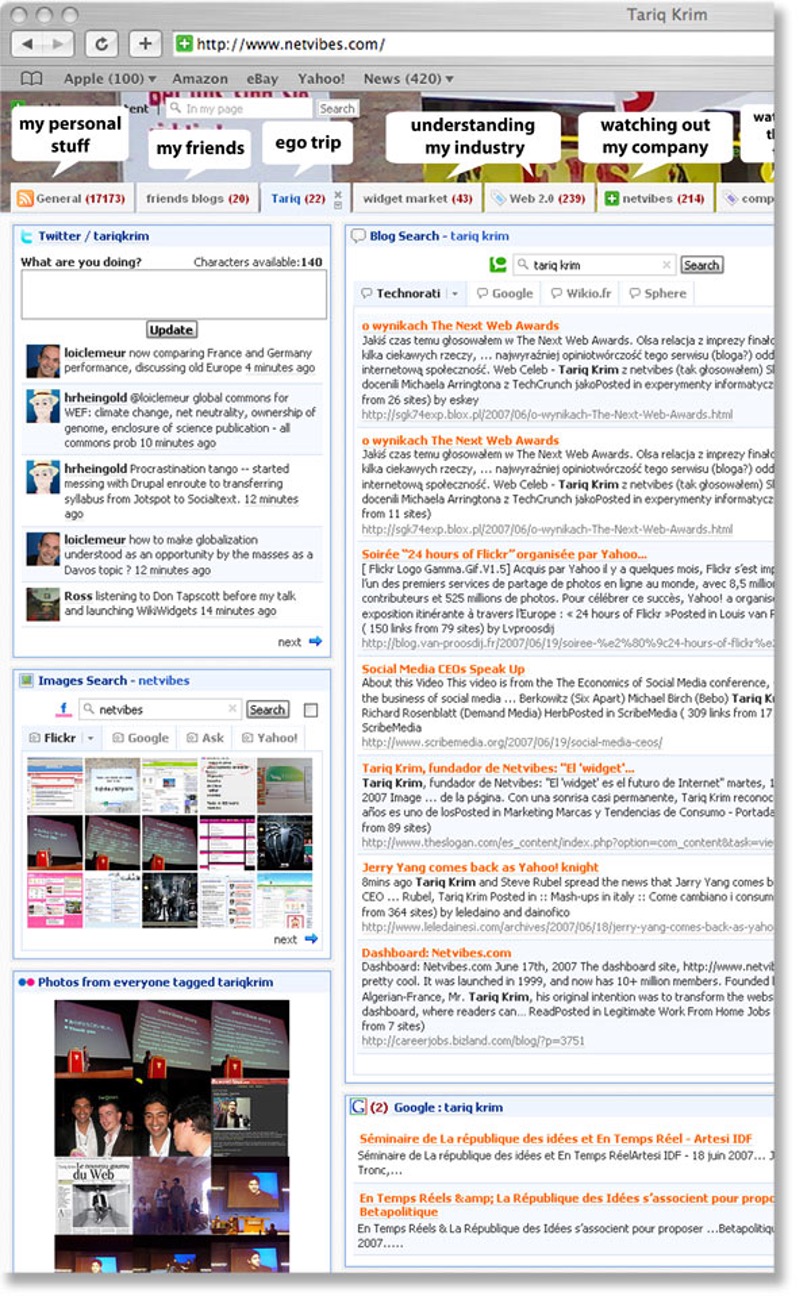
“When I open my Web browser, I want to get the latest stuff that’s really important to me,” says software engineer, Web entrepreneur, and former journalist Tariq Krim. That’s the idea behind Netvibes, a free and “agnostic” Web service Krim created to let netizens build customized pages from disparate modules such as RSS feeds from blogs, competing news sites such as Google and Yahoo, and even user-translated international sites. On the “Tariq” tab of his own Netvibes page, Krim uses search modules to track what bloggers are saying about him and his company. A portion of his page is shown below.
Ivan Krstic´
Making antivirus software obsolete
Ivan Krstic takes extracurricular activities to the extreme. Born in Croatia, he received a scholarship to attend a Michigan high school when he was 13. While there, he wrote software to interpret data for a neuroscientist at the University of Michigan. He also spent two summers in Croatia, building a patient-management computer system for Zagreb Children’s Hospital. He enrolled at Harvard in 2004 but then took a year’s leave to return to Croatia and reëngineer the Zagreb hospital’s IT system–after a month-long detour to Silicon Valley to help scale up Facebook’s software architecture.
Krstic returned to Harvard in 2005 to work on a degree in computer science and theoretical math, but he took another leave last spring to become director of security architecture for the One Laptop per Child (OLPC) program, which is building inexpensive laptops for Third World children. His mandate was to create a secure system that children could use, and that wouldn’t need the tech support and continual updates that current antivirus programs require.
So he set about making such software obsolete, building into OLPC’s Linux-based operating system a security platform called Bitfrost, named after Bifröst, a bridge in Norse mythology that reaches from Earth to heaven and that intruders can’t cross. Instead of blocking specific viruses, the system sequesters every program on the computer in a separate virtual operating system, preventing any program from damaging the computer, stealing files, or spying on the user. Viruses are left isolated and impotent, unable to execute their code. “This defeats the entire purpose of writing a virus,” says Krstic.
Some in the Linux community are so impressed with this novel approach to fighting malicious code that they have proposed making it part of the Linux standard. But since Bitfrost will allow only programs that are aware of it to run, it would make Linux incompatible with existing applications. The solution is for programmers to create “wrappers,” small programs tacked onto existing applications to enable them to communicate with Bitfrost. After OLPC’s computer ships late this year, Krstic plans to return to Harvard–and to help write those wrappers. It’s just one more extracurricular activity to take on.
Jeff LaPorte
Internet-based calling from mobile phones.
Problem: If you’re at your computer, you can use Skype and similar programs to make zero-cost domestic and international phone calls. But if you’re forced to use your mobile phone for an international call, you pay exorbitant rates. Sending mobile calls over the Internet, as Skype does with PC calls, would be cheaper–but the big carriers don’t offer such a service, and their clout with handset manufacturers makes it hard for third-party developers to create easy-to-use Internet calling software.
Solution: Jeff LaPorte conceived a clever end run around the wireless carriers and cofounded Eqo Communications of Vancouver, British Columbia, to market the idea. When an Eqo (pronounced “echo”) user dials an international number, software downloaded to the phone actually connects the call to a local Eqo number. From there, an Eqo server converts the user’s voice into data packets and sends them over the Internet to an Eqo server in the destination country, which puts the call back onto the wireless voice network. There are no complicated settings to configure or 800 numbers to dial, and calls sound as good as they do with standard wireless technology. Calls from one Eqo member to another are free, and other international calls can cost as little as 5 percent of what the major carriers charge. Eqo members must still have domestic wireless calling plans–but in LaPorte’s words, Eqo effectively “turns your local minutes into international minutes.”
Karen Liu
Bringing body language to computer-animated characters.
A crowded sidewalk is a cacophony of unspoken yet unmistakable messages. A young woman’s “I feel sexy” walk, for instance, is instantly distinguishable from a biker dude’s “Don’t mess with me” stride. But getting computer-generated (CG) characters to reproduce physical attitudes like these is still an arcane craft. Animators must either eyeball characters’ movements in hundreds of hand-drawn “key frames,” with software interpolating the in-between moments, or cheat by using expensive motion-capture systems to digitize the behavior of real actors.
As a computer science graduate student at the University of Washington in the early 2000s, Karen Liu set out to find an easier method. Her article of faith: “There [had] to be some way, from our knowledge of physics and biomechanics, to distill the properties that create motion styles.”
Biomechanics researchers had long been analyzing the mechanical factors that affect the way people move. Simulating those factors, Liu thought, would yield CG characters that move more naturally. But the human body contains hundreds of interacting parts, and it was impractical to measure or even stipulate the values of parameters such as tension and elasticity for every muscle, tendon, and ligament. Working with advisor Zoran Popovic, Liu eventually showed that feeding just a handful of these values into animation software is enough to reproduce a distinctive motion such as a “happy walk” in a range of CG models, from people to penguins.
To establish her style parameters, Liu developed algorithms based on a single, simplifying assumption: that people naturally try to waste as little energy as possible when they move. Into these algorithms she feeds short segments of motion-capture data from subjects instructed to move in a certain way–to walk happily, for example. The software then reasons backward to guess the values of certain parameters, choosing those values that would have made the movements energy efficient.
Liu, who just joined the computer science faculty at Georgia Tech, is talking with major game makers and film studios about applying her algorithms to video games and animated films. She hopes the algorithms will help animators create CG humans that move more naturally than the robotically stiff characters in films like The Polar Express. “I think we’re really close,” she says.
Anna Lysyanskaya
Securing online privacy.
Problem: People want to use the Internet without having their habits documented or their personal data stolen. But they need to prove they’re authorized to access bank accounts or subscription sites, processes that usually involve revealing their identities.
Solution: Anna Lysyanskaya, an assistant professor of computer science, has developed a practical way for people to securely log in to websites without providing any identifying information. Her approach relies on “zero-knowledge proofs.” Say you want to browse a newspaper’s archives in total privacy. With zero-knowledge proofs, you subscribe using a pseudonym and receive digitally signed credentials. When you access the paper’s site, your computer sends encrypted versions of the pseudonym and credentials. The archive can’t decrypt this information; instead, it tests it for characteristics that valid data must have. (A certain field has to contain a specific number of digits, for example.) If the credentials are fake, some attribute will be wrong, and the site will be able to tell.
Zero-knowledge proofs have been around for a while, but they’ve required too much computing power to be practical. Collaborating with Jan Camenisch of the IBM Zürich Research Laboratory, Lysyanskaya developed algorithms that make both generating and testing credentials much more efficient. IBM is incorporating these algorithms into its Idemix anonymous-credential systems.
Tapan Parikh
Simple, powerful mobile tools for developing economies.
When fishermen from the Indian state of Kerala are done fishing each day, they have to decide which of an array of ports they should sail for in order to sell their catch. Traditionally, the fishermen have made the decision at random–or, to put it more charitably, by instinct. Then they got mobile phones. That allowed them to call each port and discover where different fishes were poorly stocked, and therefore where they would be likely to get the best price for their goods. That helped the fishermen reap a profit, but it also meant that instead of one port’s being stuck with more fish than could be sold while other ports ran short, there was a better chance that supply would be closer to demand at all the ports. The fishermen became more productive, markets became more efficient, and the Keralan economy as a whole got stronger.
This story demonstrates an easily forgotten idea: relatively simple improvements in information and communication technologies can have a dramatic effect on the way businesses and markets work. That idea is central to the work of Tapan Parikh, a doctoral student in computer science and the founder of a company called Ekgaon Technologies. Parikh has created information systems tailored for small-business people in the developing world–systems with the mobile phone, rather than the PC, at their core. His goal is to make it easier for these business owners to manage their own operations in an efficient and transparent way, and to build connections both with established financial institutions and with consumers in the developed world. This will help them–they’ll be able to get money to expand their operations and, ideally, find better prices for what they sell–and it should be a boon to development as well.

In the developing world, working with mobile phones has obvious advantages: they’re ubiquitous even in poorer countries (there are 185 million cell-phone subscribers in India and more than 200 million in Africa); they’re relatively affordable; and with the right software, they’re easy to use. So Parikh developed Cam (so called because the phone’s camera plays a key role in the user interface), a toolkit that makes it simple to use phones to capture images and scan documents, enter and process data, and run interactive audio and video. The Keralan fishermen had been able to improve their business simply by making phone calls. Cam would carry the process a step further, by taking advantage of modern phones’ computing capabilities.
Parikh’s most important project with Cam has focused on perhaps the trendiest field in economic development: microfinance, in which lending groups grant tiny loans–on the order of $25–to people in the developing world, usually to fund small-business ventures. (Muhammad Yunus, the founder of the best-known microfinance institution, the Grameen Bank, won the Nobel Peace Prize last year for his work in establishing the field.) The best-publicized version of microfinance involves a solo entrepreneur getting a small loan from a well-financed bank. But Parikh is collaborating with organizations that are more representative of the way it usually works. A big chunk of the microfinance business in India, for example, is conducted by self-help groups, in which 15 to 20 people (usually women) pool their capital and then meet weekly or monthly to make collective decisions about loans to members of the group. They also use their collective borrowing power to obtain loans from nongovernmental aid organizations or from financial institutions, and then lend that money to their members.
Parikh built a software system on top of Cam to assist self-help groups in managing their information and their operations. Unglamorously called SHG MIS (for “self-help group management and information system”), it includes a Cam-based application for entering and processing data, a text-messaging tool for uploading data to online databases, and a package of Web-based software for managing data and reporting it to any institution that has lent money to the self-help group. Such groups have traditionally relied on paper documentation, however, and because their members still trust paper, the software also includes a bar-code-based system. Loan applications, grants, receipts, and other documents are printed with identifying bar codes; the software enables the phone to scan the code, identify the document, photograph it, process the data it contains, and associate that data with the code. The result is a system that facilitates a quick and accurate flow of data from small villages to bigger cities, and vice versa.
In addition to providing a more efficient way for self-help groups to manage their finances, SHG MIS allows such groups to overcome two major challenges. First, it enables them to run their internal operations in a fair and transparent way, while ensuring that their loans make economic sense. “In these groups, things are often done in a somewhat ad hoc manner, using informal documentation,” Parikh says, “which can lead to instability and impermanence and contribute to the kinds of tensions that lead small groups to fall apart.” His software gives groups a more systematic method of documenting decisions, tracking financial performance over time, and collecting information on which kinds of loans work and which don’t. These advantages should help groups make better decisions and reduce internal political tensions.
The software could also improve the flow of information between self-help groups and the formal financial sector, which should enable them to get capital at better rates. As things stand right now, Parikh says, bankers’ interest in microfinance is so high that the supply of capital more than meets demand. But because it’s difficult to track so many small, scattered loans, banks tend to offer the same deal to every business, regardless of performance, ability to repay, and so on. If self-help groups could document their performance in a formal, auditable system that banks could access quickly and reliably, the groups would be more likely to get fair prices. They would have access to more capital, too.
Two things are striking about Parikh’s invention. The first is how unremarkable it seems, and yet how consequential it is in practice. Parikh did not radically reimagine computing, nor did he make a major break with the way financial data is managed in the developed world. Instead, he focused on something whose benefits we take for granted–reliable, instant access to financial data–and figured out an easy, affordable way to bring it to people who need it. The second thing is that instead of forcing small-business people to discard all their old ways and embrace an entirely new paradigm, Parikh’s work attempts to meet them, as it were, where they live, in order to enhance their existing abilities and resources. Other engineers might insist that the self-help groups need to do away with paper, since it’s less efficient than simply using digital entry devices, or develop PC-centered systems, since mobile phones (whatever their virtues) are limited in their power and capacity. Cam, though, relies on a different strategy, one that emerges from the bottom rather than being imposed from the top.
This strategy runs counter to the way computer science has traditionally been done. Many computer scientists tend to think more about making machines faster and more powerful than they do about making sure they meet people’s needs. What’s distinctive about Parikh’s approach is that he’s spent so much of the past seven years working not in front of a computer but in the field, talking with the people he hopes will eventually be his customers. It’s a way of life that seems more characteristic of an anthropologist than a coder, but it’s responsible for much of what Cam has become. In fact, Parikh says, “all of my ideas are really just rehashes of ideas that local people have come up with.”
Parikh has adopted the same approach in his work with fair-trade coffee farmers in Guatemala. In recent years, the “fair trade” and “organic” designations have come to have real economic value: fair-trade farmers are guaranteed a minimum price for their crop, and organic farmers can often charge higher prices. But these labels also cause problems. Because they’re one-size-fits-all, they reduce the incentive for farmers to improve their growing methods or the quality of their crops above the general minimum. And they create incentives for cheating, which in turn reduces the value of the label to consumers: are you really sure how that organic coffee you bought at Starbucks or Peet’s was grown? So Parikh devised a Cam system called Randi, for “representation and inspection tool.” It allows farm inspectors to use mobile phones to systematically photograph and document farms in order to ensure their compliance with quality and production standards, and to put that data online so that it’s easily found by certifying agencies, wholesalers, and consumers.
In other words, if you wanted to know how that organic coffee was grown and whether a fair price was paid for it, Randi would let you find out. In the long run, the system would allow today’s simple labels to become more nuanced, and in the process it would allow prices to more accurately reflect what consumers really value. “At the moment, prices are good at transmitting the value of goods in strict economic terms,” Parikh says. “But they’re not so good at transmitting other kinds of information, like what the production of a good has taken away from the environment, or the experience of the workers producing that good. One of the things technologies allow us to do is actually convey more of that information.”
It would be a mistake to see Cam and technologies like it as a panacea for the problem of underdevelopment. While it’s easy to become infatuated with the promise of microfinance and small-scale entrepreneurship, it’s also easy to overestimate how much influence these things can exert on developing economies, which often face structural problems that won’t be solved by making local markets more efficient. And it’s also the case that, in the short run at least, the arrival of new technologies can widen the gap between the prosperous and the struggling: if you’re buying more from the Cam-equipped farmers, you’ll probably buy less from the non-Cam-equipped ones. In other words, not everyone will win.
Parikh seems well aware of the limits of technology in general and Cam in particular. But he is also convinced that mobile phones have the capability to become far more powerful tools, which is why he has other applications in mind for Cam–such as tracking disease outbreaks and improving the coördination of relief after disasters. In each case, one can observe Parikh’s respect for the virtues of decentralized organization and the conviction that bringing more information and more transparency to social systems is better. Parikh is focused more on solving real problems than on developing complex technologies. “I think oftentimes with formal and well-established disciplines like computer science, you run into the problem of inertia, a kind of hesitancy to accept new ideas about what should count as important,” he says. “But I’m cautiously optimistic that within academia as a whole, there’s a broad sense that the real-world impact of someone’s work is an important criterion by which to judge it. Ultimately, I think that’s what counts: how can the work we do have a practical impact? How can it make a difference in the way people live?”
Babak Parviz
Self-assembling micromachines.
Problem: Relatively simple microelectromechanical systems are already used in air bags and other devices, but MEMS of greater complexity hold promise in applications ranging from medical implants to advanced navigation devices. Such machines might include components like tiny sensors, motors, and power sources. The methods for manufacturing these diverse parts, however, are largely incompatible, which makes assembling complex MEMS on a large scale and at a reasonable cost impossible.
Solution: Babak Parviz, an assistant professor of electrical engineering, has developed a method of coaxing individual components to assemble themselves into MEMS devices. Recently, he used it to build a working single-crystal silicon circuit on a flexible plastic substrate; the two materials are difficult to combine using conventional manufacturing methods.
Parviz began by manufacturing micrometer-size silicon parts in bulk. He also designed a plastic substrate with binding sites whose shapes complemented those of the silicon components. Parviz immersed the substrate in a fluid containing the silicon parts, which quickly attached to their binding sites. Metal interconnects embedded in the plastic completed the circuitry.
Such silicon-on-plastic devices could form the basis for flexible displays, biosensors, and low-cost solar panels. Parviz says that self-assembly offers the ability to efficiently and cheaply manufacture multifunctional devices of all sizes from nanoscale components.

Partha Ranganathan
Power-aware computing systems.
Every year, computing devices–from cell phones to servers–consume at least 125 terawatt-hours of electricity, roughly the amount produced by burning 350 million tons of coal. Partha Ranganathan, principal research scientist at Hewlett-Packard Labs, is developing strategies to bring that figure down (see below). “All the ideas are very intuitive,” he says. “But we needed to solve some hard problems to get there.” Technologies he helped develop, which could save money and lower greenhouse-gas emissions, are already starting to appear in consumer and business products.
Kevin Rose
Online social bookmarking.
In 2004, Kevin Rose set out to transform the way people read news. The result, Digg, mixes blogging, online syndication, social networking, and “crowdsourcing”–which combines the knowledge and opinions of many individuals–to create an online newspaper of stories selected by the masses. The principles behind Digg are simple. Users can submit stories; if other users like a story, they can “digg,” or praise, it; if not, they can “bury,” or condemn, it. A new visitor sees a ceaseless scroll of stories accompanied by a flurry of comments. Digg’s straightforward rules have made it hugely popular: less than three years after its launch, more than 17 million users visit the site each month. But with success, Digg has also attracted controversy. Some observers decry the inanity of the site’s top stories, and even habitual users admit that the comments are mostly puerile. Rose, who acts as the site’s chief architect, must increasingly weigh the anarchic free speech that characterized Digg’s early days against a more responsible approach to publishing that protects intellectual property and other institutional interests.
TR: Digg is a testament to collective wisdom–but I wonder if at any point you’ve felt embarrassed, either by the top stories or by the comments about the stories.
Kevin Rose: Not really. Every single day I find something that’s really interesting that I wouldn’t have found on a traditional news outlet, an interesting nugget of information that happens to surface on an unknown blog
or a website that I haven’t heard of before. I think if you go on
CNN.com or MSNBC.com, you’re going to find the news that you’re used to reading. When you come to Digg, you never know what you’re going to get.
TR: What about the common criticism of Digg, that what tends to be “dugg” is often superficial? Are the most popular stories on Digg really the best stories?
KR: As we speak, right now, the top three stories on Digg are do-it-yourself lucid dreaming, an update about the Apple iPhone, and why a former official of the Reagan administration thinks that President Bush should be tried as a war criminal. We get a mixture of all types of news on our front page.
TR: Stories appear and disappear on Digg’s main pages with tremendous speed. Does Digg move too quickly for most people to usefully understand what’s there?
KR: We try to make sure there isn’t too much information flowing through the system. We are constantly tweaking our promotion algorithm to make sure that it doesn’t become overwhelming. As we grow, we also have to continue to raise the bar required for stories to get promoted to the front page. One of the things that I’m really focused on is improving the experience that’s off the front page. Already you can get recommendations from friends; soon the system will start recommending stories that you might have missed or that you might find interesting, based on what you’ve dugg in the past.
TR: You had a small scandal recently, when you published the encryption key that protects high-definition video discs (HD-DVD). First, under industry pressure, you took down the post; then, under pressure from your users, you put it back. What is your policy on censorship?
KR: We sort of take everything on a case-by-case basis. Things that are very clear violations of our terms of service come off the site; we don’t allow pornography or pirated software, for instance. But when it’s in one of the gray areas, it gets tricky.
TR: I’m curious about your feelings about the power of the Digg community. Do you think it can be controlled or directed?
KR: It resists being directed, that’s for sure. It was very clear when the HD-DVD story broke, and then again, during the aftermath. I was watching the Digg community saying, “You can’t censor us; this is free speech.” The home page reflected those comments, and there was really nothing that we could do. We just built the platform. It’s really up to the users to determine what they want to see on the front page.
TR: You’re saying that even if you wanted to, you couldn’t control what appears on Digg–except by removing a story ex post facto.
KR: Yeah. Behind the scenes, what you don’t see is that we have these servers that are just going crazy. I mean, you have thousands and thousands of people digging stories and submitting stories and commenting and posting–and we can’t write code that would keep up with that. The HD-DVD business was absolutely fascinating. I sat there, and I was kind of in shock and spellbound at the same time. It was quite the evening.
TR: Digg watchers say that 100 users are responsible for more than half the stories on the site’s home page, a phenomenon that creates the potential for abuse. How do you know when someone is gaming Digg? And what can the company do to stop them?
KR: The system knows. Our main job is to evolve the platform so that it promotes to the front page news and videos that have a diverse crowd of people digging them. We have to make sure that when a story does make the front page, it was actually chosen by individuals who wanted to see it on the front page–and not spammers trying to promote their own stories.
Have you heard that media companies are ambivalent about the traffic Digg sends them? It’s hard to sell it to advertisers, because it’s unpredictable, and the quality of the audience isn’t measurable.
I think that’s probably true. But I find it a little hard to think of Digg as a source of traffic; it was designed as just a way for people to share things with their friends. Also, this trend is much bigger than us. If a story is popular, it’s going to spread. We often see a chain reaction occur: a story will hit Del.icio.us, and then it’s on Digg, and then it’s on Boing Boing.
TR: To date, Digg has been a haven for science and technology geeks. Can you imagine a day when Digg will truly be a general-interest site?
KR: Definitely. Politics is one of our most popular sections and will soon overtake technology. We started off with a large tech base; we were 100 percent technology for the first year, so that’s our roots. But we’re quickly expanding beyond that.
Desney Tan
Teaching computers to read minds.
It’s not unusual to walk into Desney Tan’s Microsoft Research office and find him wearing a red and blue electroencephalography (EEG) cap, white wires cascading past his shoulders. Tan spends his days looking at a monitor, inspecting and modifying the mess of squiggles that approximate his brain’s electrical activity. He is using algorithms to sort through and make sense of EEG data in hopes of turning electrodes into meaningful input devices for computers, as common as the mouse and keyboard.
The payoff, he says, will be technology that improves productivity in the workplace, enhances video-game play, and simplifies interactions with computers. Ultimately, Tan hopes to develop a mass-market EEG system consisting of a small number of electrodes that, affixed to a person’s head, communicate wirelessly with software on a PC. The software could keep e-mail at bay if the user is concentrating, or select background music to suit different moods.
As early as 1929, researchers observed slight changes in EEG output that corresponded to mental exertion. But these results haven’t led to a mass-market computer-input device, for a number of reasons. Most EEG experiments are conducted in labs where electrical “noise” has been minimized, but outside the lab, EEG is susceptible to electrical interference. EEG equipment also tends to be expensive. And previous research has averaged data from many users over long periods of time; some studies have shown that individual results vary widely.
Tan believes he can solve these problems by training machine-learning algorithms–often used to understand speech and recognize photos–to account for variations between individuals’ EEG patterns and to distinguish interesting electrical signals from junk. Contrary to popular practice, Tan keeps his lab as electrically noisy as the average home or office. He is even using the least expensive EEG equipment he could find–a kit he bought for a couple of hundred dollars at a New Age store. (Some people use EEG for meditation.)
Tan’s EEG cap has 32 electrodes that are affixed to the scalp with a conductive gel or paste. When neurons fire, they produce an electrical signal of a few millivolts. Electronics within the device record the voltage at each electrode, relative to the others, and send that data to a computer.
A subject using Tan’s system spends 10 to 20 minutes performing a series of tasks that require either high or low concentration–such as remembering letters or images for various amounts of time. EEG readings taken during the activity are fed to a computer, which manipulates them mathematically to generate thousands of derivations called “features.” The machine-learning algorithm then sifts through the features, identifying patterns that reliably indicate the subject’s concentration level when the data was collected. Tan and his collaborators at the University of Washington, Seattle, and Carnegie Mellon University have shown that a winnowed set of about 30 features can predict a subject’s concentration level with 99 percent accuracy.
Tan expects the technology to be used initially as a controller for video games, since gamers are accustomed to “strapping on new devices,” he says. In fact, next year a company called Emotiv Systems, based in San Francisco, plans to offer an EEG product that controls certain aspects of video games. However, the company will not discuss the specifics of its technology, and there isn’t widespread consensus on the feasibility and accuracy of the approach.
The true challenge, Tan says, will be to make EEG interfaces simple enough for the masses. He and his team are working on minimizing the number of electrodes, finding a semisolid material as an alternative to the conductive gel, and developing wireless electrodes. A mass-market product could be many years away. But if Tan succeeds, getting a computer to read your thoughts could be as easy as putting on a Bluetooth headset.
Luis von Ahn
Using “captchas” to digitize books.
Luis von Ahn is a pioneer of “captchas”–those strings of distorted characters that websites force you to recognize and type in order to establish that you are a person and not a malevolent computer. But he finds the technology’s success a mixed blessing. “At first I was feeling quite proud of myself,” says von Ahn, a 2006 MacArthur “genius grant” recipient who created captchas (an acronym for “completely automated public Turing test to tell computers and humans apart”) for Yahoo in 2000 to thwart automated e-mail account registration, a tool of spammers. “But then I was feeling bad, because every time you solve a captcha, you waste 10 seconds.” People around the world solve an estimated 60 million captchas every day, adding up to more than 150,000 wasted hours.
Von Ahn, an assistant professor of computer science, is a leader in using human skills to make computers work better. For example, he created an online game in which players identify elements in photographs; their answers help improve image-search algorithms. He’s now trying to put captchas to work in one of the epic efforts of the information age: digitizing millions of old books and making them searchable online.
An estimated 8 percent of words in these old books can’t be read by the optical character recognition (OCR) software used to scan them. Von Ahn has teamed with the nonprofit Internet Archive to use captchas to help interpret those words. After all, he says, “while you are solving a captcha, you are solving a task that computers can’t perform.” So he created a tool, called ”recaptcha,” that pairs an unknown word with a known one. He distorts them both and puts a line through them–standard techniques for creating captchas. A user must decipher both captchas to access a site. The accurate typing of the known word serves the security purpose of captchas and adds a measure of confidence that the unknown word was identified correctly and can be used in place of the OCR’s gibberish. Volunteers have begun deploying recaptchas, and the technique has been used to decipher two million words for the Internet Archive’s book digitization effort. Recaptchas tap the joint power of people, networks, and computers in a way that should have a big impact, says Brewster Kahle, an Internet entrepreneur and cofounder of the archive: “It is like an army of ants building the Taj Mahal.”

Mark Zuckerberg
Circle of friends.
Three and a half years ago, Mark Zuckerberg (then a Harvard sophomore) and a couple of friends built a website to let them share photos and personal profiles with other Harvardians. Zuckerberg became CEO of the new enterprise, called Facebook. The social-networking site gradually opened its doors to students at other colleges and then high schools. Now that anyone with an e-mail address can register, the site has more than 30 million members, who use it to blog, share pictures, connect with old friends, and expand their networks.
In May, the company announced the Facebook Platform, which lets users build and share tools for personalizing their profile pages and adding, say, videos or music from other websites. The idea, says Zuckerberg, is that the personal connections people have made within Facebook will lead them to content that’s interesting to them.
The company is embroiled in a long-standing legal dispute with ConnectU, another networking site that originated at Harvard, over ownership of the initial source code and even the basic business idea. Still, Bloomberg reported in December that the privately held company’s value may be more than $1 billion, thanks largely to the site’s appeal to advertisers. As Facebook grows, so does its potential to become a major content distributor. Not a bad prospect for a programming project hatched in a dorm room.