Has Big Data Made Anonymity Impossible?
In 1995, the European Union introduced privacy legislation that defined “personal data” as any information that could identify a person, directly or indirectly. The legislators were apparently thinking of things like documents with an identification number, and they wanted them protected just as if they carried your name.
Today, that definition encompasses far more information than those European legislators could ever have imagined—easily more than all the bits and bytes in the entire world when they wrote their law 18 years ago.
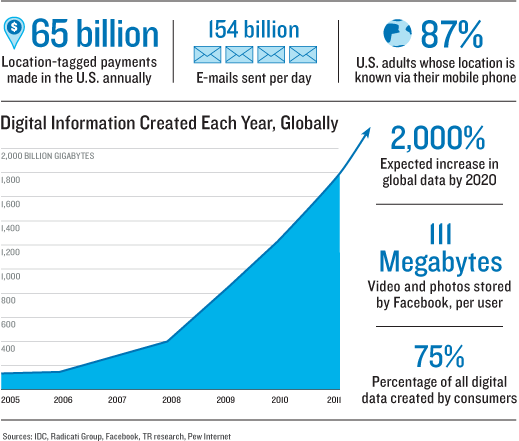
Here’s what happened. First, the amount of data created each year has grown exponentially: it reached 2.8 zettabytes in 2012, a number that’s as gigantic as it sounds, and will double again by 2015, according to the consultancy IDC. Of that, about three-quarters is generated by individuals as they create and move digital files. A typical American office worker produces 1.8 million megabytes of data each year. That is about 5,000 megabytes a day, including downloaded movies, Word files, e-mail, and the bits generated by computers as that information is moved along mobile networks or across the Internet.
Much of this data is invisible to people and seems impersonal. But it’s not. What modern data science is finding is that nearly any type of data can be used, much like a fingerprint, to identify the person who created it: your choice of movies on Netflix, the location signals emitted by your cell phone, even your pattern of walking as recorded by a surveillance camera. In effect, the more data there is, the less any of it can be said to be private, since the richness of that data makes pinpointing people “algorithmically possible,” says Princeton University computer scientist Arvind Narayanan.
We’re well down this path already. The types of information we’ve thought of as personal data in the past—our name, address, or credit card records—are already bought and sold by data brokers like Acxiom, a company that holds an average of 1,500 pieces of information on more than 500 million consumers around the world. This was data that people put into the public domain on a survey form or when they signed up for services such as TiVo.
Acxiom uses information about the make and year of your car, your income and investments, and your age, education, and zip code to place you into one of 70 different “PersonicX” clusters, which are “summarized indicators of lifestyle, interests and activities.” Did you just finalize a divorce or become an empty nester? Such “life events,” which move people from one consumer class to another, are of key interest to Acxiom and its advertising clients. The company says it can analyze its data to predict 3,000 different propensities, such as how a person may respond to one brand over another.
Yet these data brokers today are considered somewhat old-fashioned compared with Internet companies like Facebook, which have automated the collection of personal information so it can be done in real time. According to its financial filings at the time of its IPO, Facebook stores around 111 megabytes of photos and videos for each of its users, who now number more than a billion. That’s 100 petabytes of personal information right there. In some European legal cases, plaintiffs have learned that Facebook’s records of their interactions with the site—including text messages, things they “liked,” and addresses of computers they used—run to 800 printed pages, adding up to another few megabytes per user.
In a step that’s worrisome to digital-privacy advocates, offline and online data sets are now being connected to help marketers target advertisements more precisely. In February, Facebook announced a deal with Acxiom and other data brokers to merge their data, linking real-world activities to those on the Web. At a March investor meeting, Acxiom’s chief science officer claimed that its data could now be linked to 90 percent of U.S. social profiles.
Such data sets are often portrayed as having been “anonymized” in some way, but the more data they involve, the less likely that is to be actually true. Mobile-phone companies, for instance, record users’ locations, strip out the phone numbers, and sell aggregate data sets to merchants or others interested in people’s movements (see “How Wireless Carriers Are Monetizing Your Movements”). MIT researchers Yves-Alexandre de Montjoye and César A. Hidalgo have shown that even when such location data is anonymous, just four different data points about a phone’s position can usually link the phone to a unique person.
The greater the amount of personal data that becomes available, the more informative the data gets. In fact, with enough data, it’s even possible to discover information about a person’s future. Last year Adam Sadilek, a University of Rochester researcher, and John Krumm, an engineer at Microsoft’s research lab, showed they could predict a person’s approximate location up to 80 weeks into the future, at an accuracy of above 80 percent. To get there, the pair mined what they described as a “massive data set” collecting 32,000 days of GPS readings taken from 307 people and 396 vehicles.
They then imagined the commercial applications, like ads that say “Need a haircut? In four days, you will be within 100 meters of a salon that will have a $5 special at that time.”
Sadilek and Krumm called their system “Far Out.” That’s a pretty good description of where personal data is taking us.
Jessica Leber contributed reporting to this item.
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.