Machine vision can create Harry Potter–style photos for muggles

In J.K. Rowling’s Harry Potter novels, magical photographs are similar to ordinary ones except that the characters in them are animated; they wave, smile, or sometimes disappear altogether to attend to other business.
Magical photos are the creation of Rowling’s extraordinary imagination. But something like them may soon be available to ordinary muggles thanks to the work of Chung-Yi Weng at the University of Washington in Seattle and a couple of pals. These folks have created a piece of software called Photo Wake-Up that can animate the central character in a photograph while leaving the rest of the image untouched.
This task is easier said than done because of an important unsolved problem in computer science. This is the problem of body pose estimation. Given a two-dimensional image of a human, the question that machine vision struggles to answer is: what three-dimensional pose is the person taking?
That’s difficult because bodies can be partially occluded, often by other body parts, as when someone stands with arms folded. That makes it hard for a machine to determine the three-dimensional structure from a 2D image.
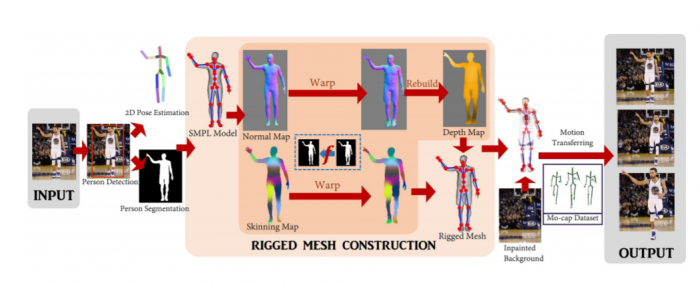
A wide range of computer science teams have attempted to tackle this problem. In this work, Weng and co use a program called SMPL, developed by a team at Microsoft and the Max Planck Institute for Intelligent Systems in Germany.
This begins with a 2D cutout of a human body and superimposes a 3D skeleton onto the shape. The skeleton can then be animated to create the sense of movement. That solves the problem of pose estimation, albeit for a limited set of circumstances.
The code needs to see a head-to-toe cutout of a body seem from the front. It can handle some types of occlusion, such as an arm in front of the body, but cannot handle more complex occlusions, such as somebody sitting with legs crossed. Even still, mapping the cutout from a photograph onto a 3D skeleton does not produce realistic animations.
That’s where Weng and co come in. Their main achievement is to develop a way to warp the 2D cutout in a way that creates a realistic 3D model of the body. “Our key technical contribution, then, is a method for constructing an animatable 3D model that matches the silhouette in a single photo,” they say.
In the past, computer scientists have tried to solve this problem by deforming a three-dimensional body-shaped mesh to reflect the 2D cutout. That does not always work well, so Weng and co try a different approach.
Their idea is to map the body-shaped mesh into 2D space and then align it with the 2D cutout using a warping algorithm. This identifies specific parts of the body—head, right arm, right leg, left arm, left leg, and torso—and warps each one in a way that matches the cutout.
Having performed the alignment in 2D, they transform it back into 3D. “This 2D warping approach works well for handling complex silhouettes,” they say.
The team pay special attention to the head, which human viewers tend to focus on. “Accuracy in head pose is important for good animation,” they say. So their algorithm also identifies features such as gaze direction and head angle, and then use this to get a precise angle for the body-mesh head pose.
These automated techniques are good, but they are not perfect. So the team have also developed a user interface that allows anybody to change the skeleton’s orientation relative to the body. That allows users to correct any errors and to fine-tune the animation.
The end result is an impressive kind of animated photo. The algorithm isolates a human body in the photograph, cuts it out of the image, and fills in gap with a patch-filling algorithm. It then animates this body in three dimensions to make it walk out of the photo, to run, jump, or wave, rather like the magical photos imagined by Rowling. The algorithm even works in augmented-reality settings.
“Our method works with large variety of whole-body, fairly frontal photos, ranging from sports photos, to art, and posters,” they say. The team have produce a video showing their method and results here. It’s worth watching!
That’s interesting work with potential to entertain and inform. As Weng and co put it: “We believe the method not only enables new ways for people to enjoy and interact with photos, but also suggests a pathway to reconstructing a virtual avatar from a single image while providing insight into the state of the art of human modelling from a single photo.”
Even Rowling would surely be impressed.
Ref: arxiv.org/abs/1812.02246 : Photo Wake-Up: 3D Character Animation from a Single Photo
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.