The rare form of machine learning that can spot hackers who have already broken in
In 2013, a group of British intelligence agents noticed something odd. While most efforts to secure digital infrastructure were fixated on blocking bad guys from getting in, few focused on the reverse: stopping them from leaking information out. Based on that idea, the group founded a new cybersecurity company called Darktrace.
The firm partnered with mathematicians at the University of Cambridge to develop a tool that would use machine learning to catch internal breaches. Rather than train the algorithms on historical examples of attacks, however, they needed a way for the system to recognize new instances of anomalous behavior. They turned to unsupervised learning, a technique based on a rare type of machine-learning algorithm that doesn’t require humans to specify what to look for.
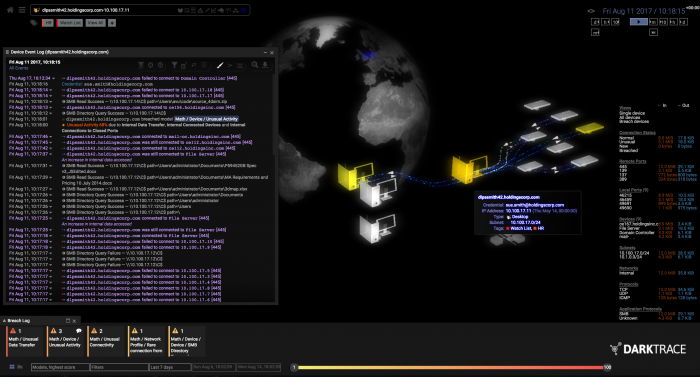
"It’s very much like the human body’s own immune system," says the company’s co-CEO Nicole Eagan. "As complex as it is, it has this innate sense of what’s self and not self. And when it finds something that doesn’t belong—that’s not self—it has an extremely precise and rapid response."
The vast majority of machine-learning applications rely on supervised learning. This involves feeding a machine massive amounts of carefully labeled data to train it to recognize a narrowly defined pattern. Say you want your machine to recognize golden retrievers. You feed it hundreds or thousands of images of golden retrievers and of things that are not, all the while telling it explicitly which ones are which. Eventually, you end up with a pretty decent golden-retriever-spotting machine.
In cybersecurity, supervised learning works pretty well. You train a machine on the different kinds of threats your system has faced before, and it chases after them relentlessly.
But there are two main problems. For one, it only works with known threats; unknown threats still sneak in under the radar. For another, supervised-learning algorithms work best with balanced data sets—in other words, ones that have an equal number of examples of what it’s looking for and what it can ignore. Cybersecurity data is highly unbalanced: there are very few examples of threatening behavior buried in an overwhelming amount of normal behavior.
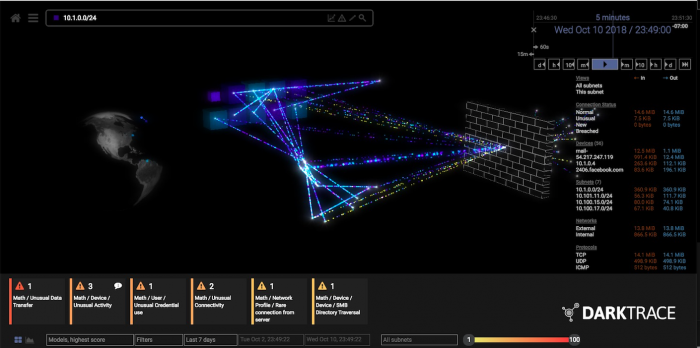
Fortunately, where supervised learning falters, unsupervised learning excels. The latter can look at massive amounts of unlabeled data and find the pieces that don’t follow the typical pattern. As a result, it can surface threats that a system has never seen before and needs few anomalous data points to do so.
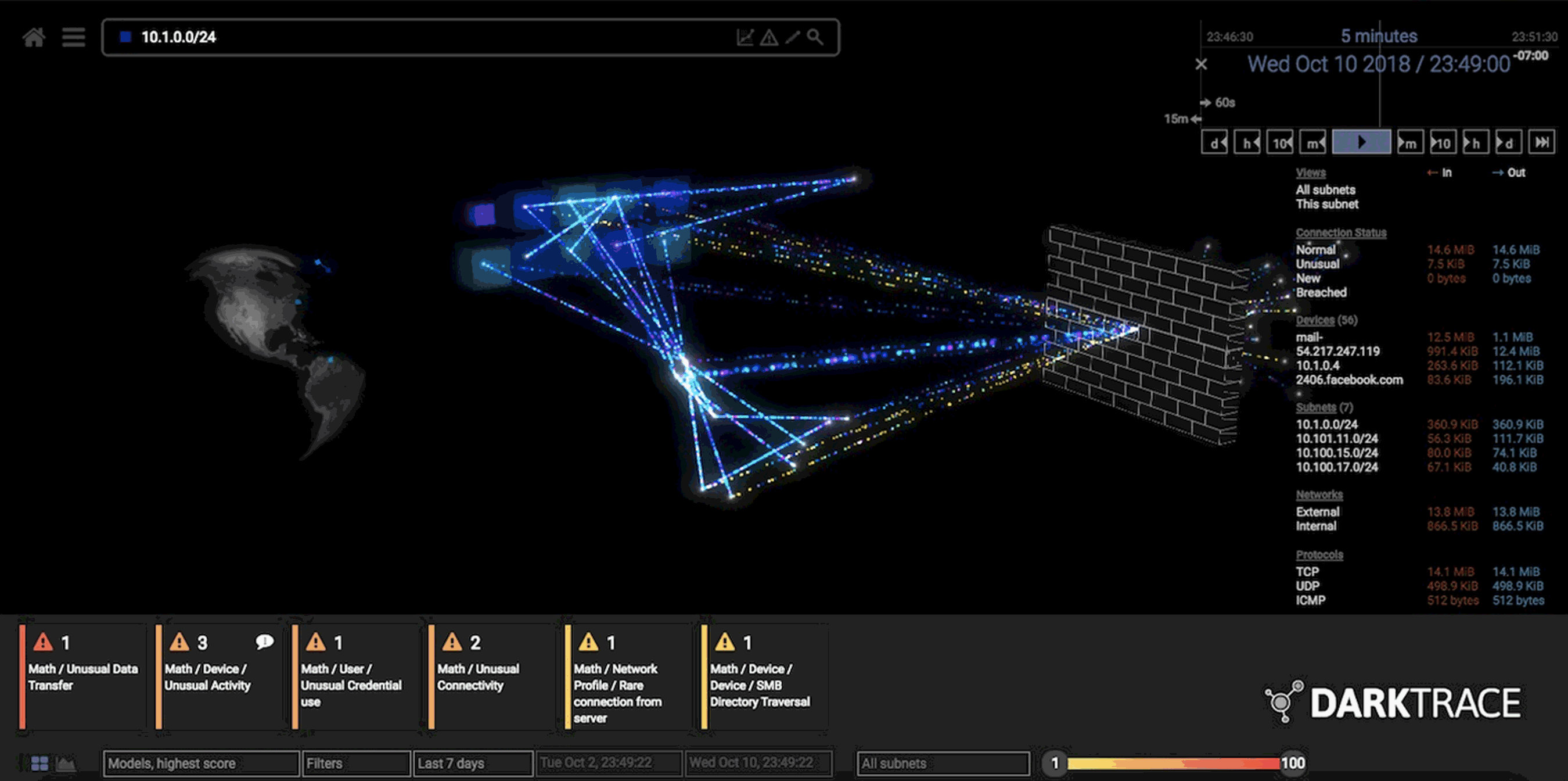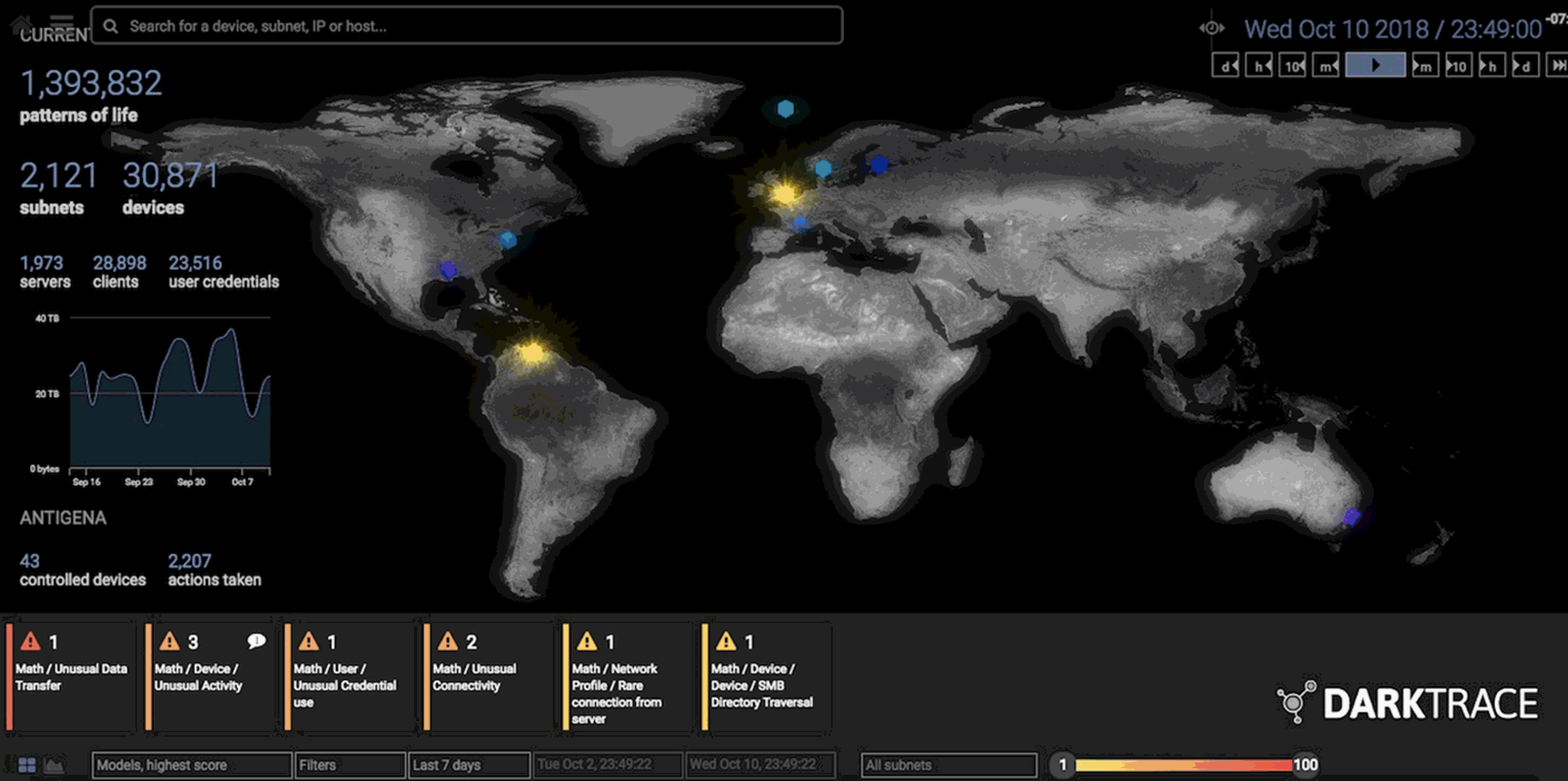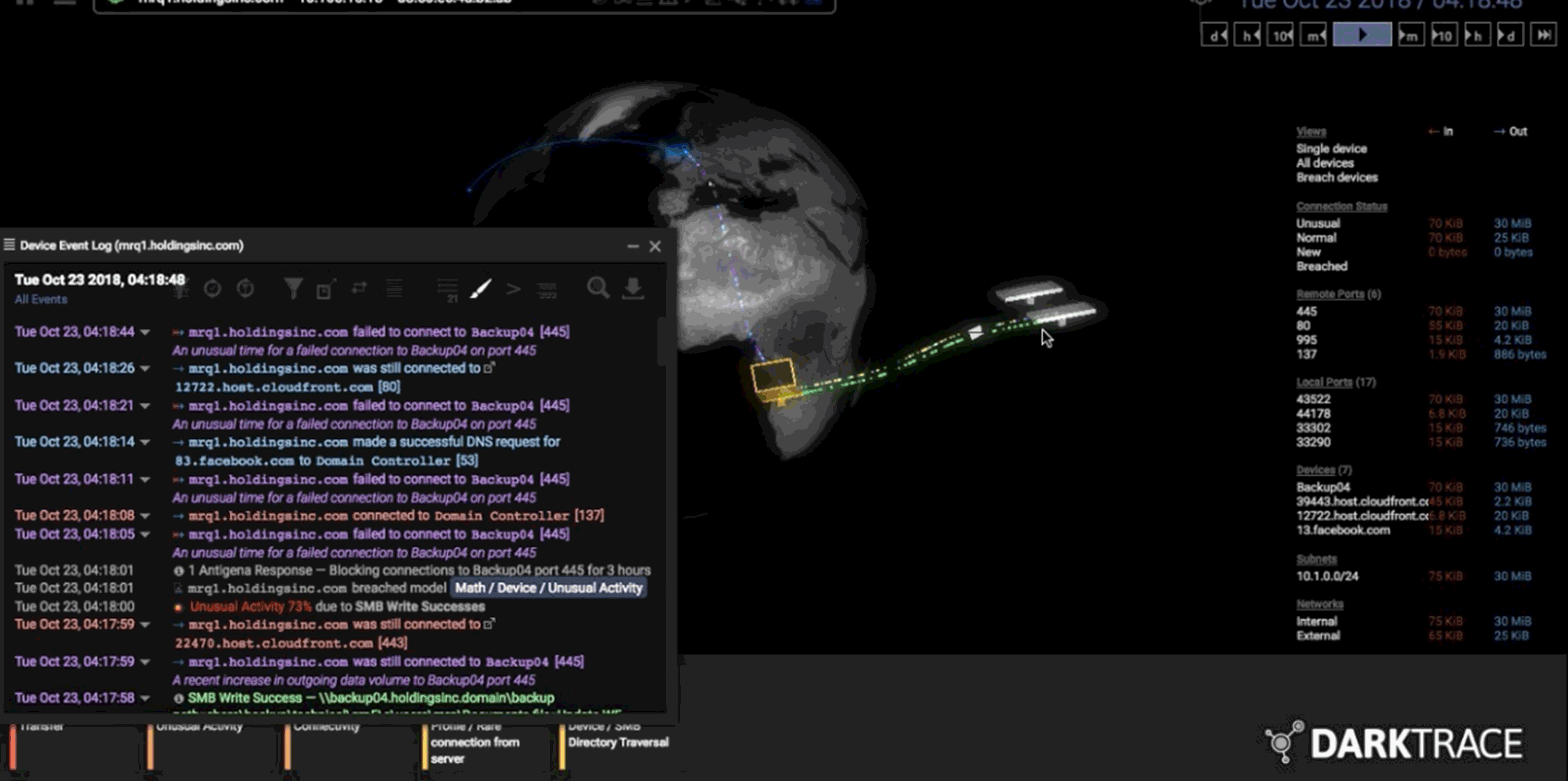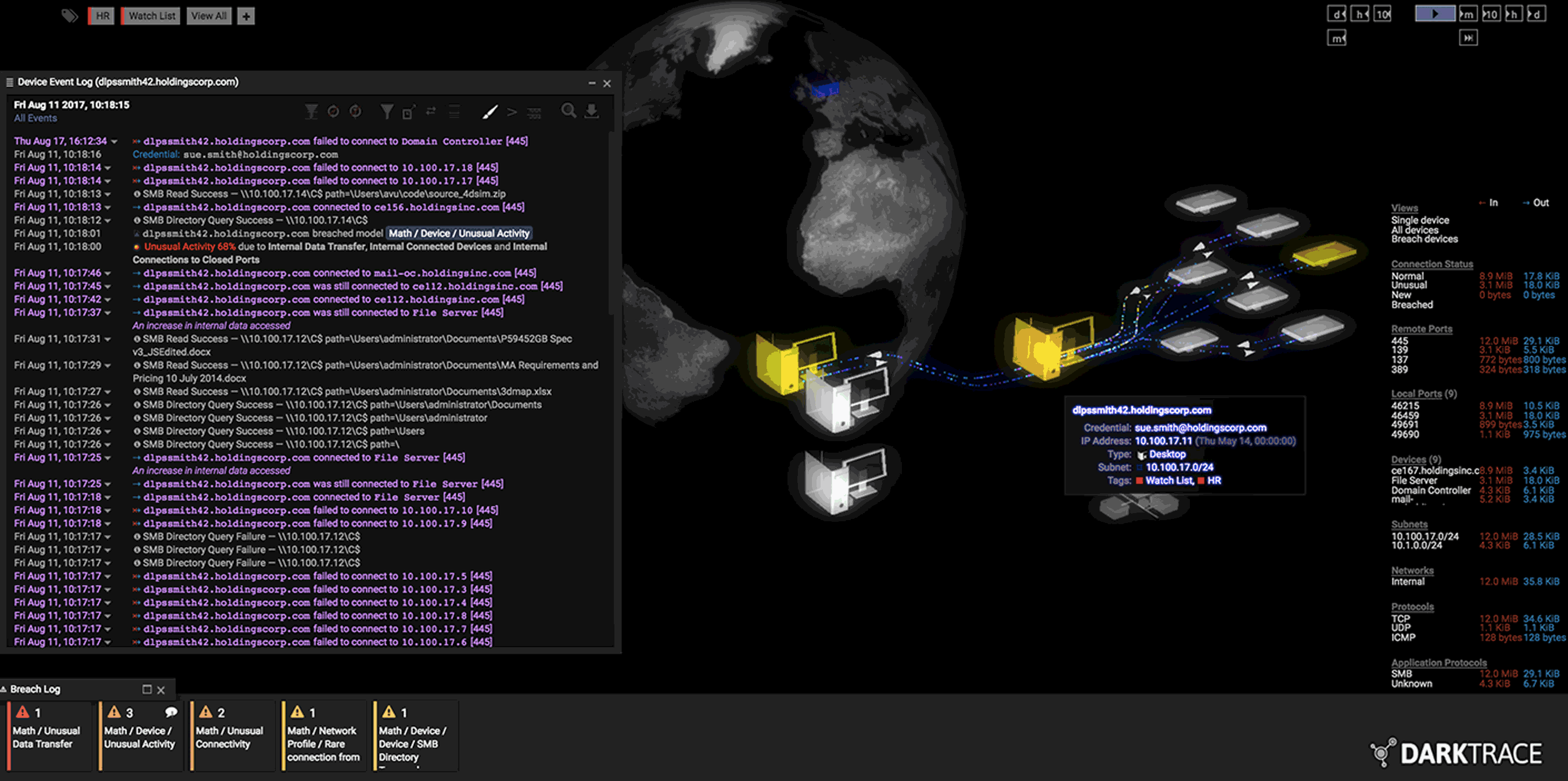
When Darktrace deploys its software, it sets up physical and digital sensors around the client’s network to map out its activity. That raw data is funneled to over 60 different unsupervised-learning algorithms that compete with one another to find anomalous behavior.
AN UNSUPERVISED SPACE
Several other companies have also converged on using unsupervised learning to heighten digital security systems.
Shape Security
Founded in 2011 by ex-Pentagon defense experts, it focuses on preventing fake account generation or credit application fraud, among other nefarious activities. Shape Security combines the complementary strengths of both supervised and unsupervised techniques.
DataVisor
Founded in 2013 by Microsoft alums, it partners with banks, social-media, and e-commerce companies to fight transaction fraud, money laundering, and other large-scale abuse. DataVisor says it primarily uses unsupervised techniques.
Those algorithms then spit their output into yet another master algorithm that uses various statistical methods to determine which of the 60 to listen to and which of them to ignore. All that complexity is packaged into a final visualization that allows human operators to quickly see and respond to likely breaches. As the humans work out what to do next, the system works to quarantine the breach until it’s resolved—by cutting off all external communication from the infected device, for example.
Unsupervised learning is no silver bullet, however. As attackers get more and more sophisticated, they get better at fooling machines, whatever type of machine learning they are using. "There is this cat-and-mouse game where attackers can try to change their behavior," says Dawn Song, a cybersecurity and machine-learning expert at the University of California, Berkeley.
In response, the cybersecurity community has turned to proactive approaches—"better security architectures and principles so that the system is more secure by construction," she says. But there’s still a long way to completely eradicating all breaches and fraudulent practices. After all, she adds, "the whole system is as secure as its weakest link."
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.