This algorithm can tell which number sequences a human will find interesting
One of the curious properties of mathematics is its beauty. But exactly what mathematicians mean by beauty is hard to capture.
Perhaps the most famous example is Euler’s relation, eiπ + 1 = 0, which reveals a deep link between seemingly unrelated areas of mathematics. For example, π comes from geometry, e and i come from algebra, and the primitives 0 and 1 along with the operations + and = come from number theory. That they are related in such a simple and unexpected way is one of the great wonders of the mathematical world.
And that points to another component of mathematical beauty: Mathematical patterns must be interesting in some way. Recognizing these interesting patterns has always been a uniquely human capability.
But in recent years, machines have become hugely capable pattern-recognition tools. Indeed, they have begun to outperform humans in face recognition, object recognition, and a variety of game-playing roles as well.
And that raises an interesting possibility: Can machine-learning algorithms identify interesting or elegant patterns in mathematics? Could they even be arbiters of mathematical beauty?
Today we get an answer of sorts thanks to the work of Chai Wah Wu at IBM’s TJ Watson Research Center in New York state. Wu has built a machine-learning algorithm that has learned to identify certain types of elegance in mathematical structures and used it to filter interesting sequences from entirely random ones.
The technique uses an unusual database called the Online Encyclopedia of Integer Sequences, originally created in the 1960s by the mathematician Neil Sloane and placed on the web in 1996.
An integer sequence is a series of numbers that are ordered according to a rule. Famous examples include the prime numbers—numbers that can be divided only by themselves and 1 (A000040); the Fibonacci sequence, in which each term is the sum of the previous two terms (A000045); and even trivial examples such as the sequence of odd numbers or the primes that start with a 7.
Indeed, the mathematicians who run the OEIS cast the net widely in search of “interesting” sequences and so have included a wide range of examples with purely cultural significance. These include prime numbers that contain the sequence 666, the so-called number of the beast.
The database even includes the sequence of prime numbers that contain the number 667 (A138563). This number was deemed significant because when fax machines were common, people would often have a fax number that was their telephone number plus 1. In other words, if their telephone number were 123-4567, their fax number would be 123-4568. By this way of thinking, 667 is the fax number of the beast, and so of cultural significance (the editors are human, after all).
Today, the Integer Sequence database contains some 300,000 sequences, and new ones are submitted every day by amateurs and professionals alike, many of them hinting at new and interesting problems in mathematics.
The task that Wu took on was to find a way to distinguish these “interesting” sequences from randomly generated ones. And his idea was to find empirical laws that can act as measures of “interestingness” that could distinguish them from uninteresting ones.
“Empirical laws are not mathematical theorems per se but are empirical observations of relationships that seem to apply to many natural and man-made data sets,” says Wu. Examples include Moore’s Law in electrical engineering and the 80/20 Pareto principle in economics. Just why these “laws” hold isn’t fully understood, but they hold nonetheless.
One empirical principle that applies to many data sets is Benford’s Law. This was discovered by the Canadian mathematician and astronomer Simon Newcomb in 1881. Newcomb noted that the earlier pages in books of logarithm tables were more heavily thumbed than later pages, suggesting that logarithms starting with the digit 1 were more common.
This led him to formulate the principle that in any set of data, more numbers would begin with 1 than any other number. The same idea was rediscovered and popularized by Frank Benford in the 1930s.
Benford’s Law applies to a wide range of data sets, such as electricity bills, street addresses, stock prices, and so on. It is so predictable that it can be used to spot fraud in financial accounts. But it does not apply to random sequences. Exactly why is not clearly understood.
Indeed, it is something of a puzzle that mathematicians have discovered that Benford’s Law applies to some integer sequences. But how widely does it apply in these sequences?
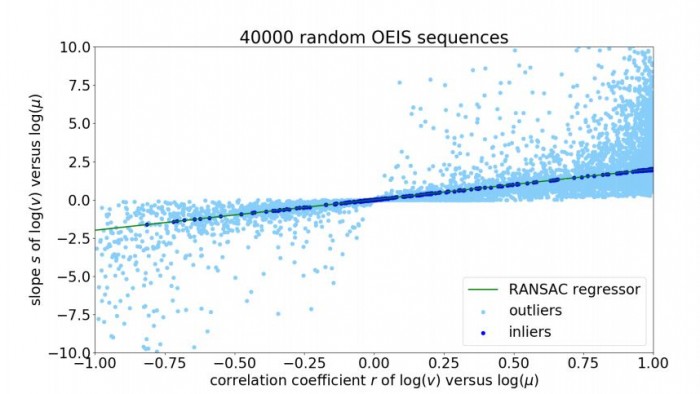
To find out, Wu measured how well the law predicts the distribution of first digits in 40,000 sequences randomly chosen from the OEIS database.
It turns out that Benford’s Law crops up much more often than expected. “The results show that many, but not all, sequences satisfy to some degree Benford’s Law,” says Wu, who found that another empirical principle called Taylor's Law was also widely present.
The next question was a simple step further: Could Benford’s Law and Taylor’s Law be used to distinguish random sequences from those in the OEIS?
To find out, Wu generated 40,000 sequences of random integers and added these to the 40,000 sequences selected from the OEIS. He then trained a machine-learning algorithm to spot OEIS sequences using Benford’s Law and Taylor’s Law and to distinguish them from random sequences.
The results are impressive. The algorithm worked with an accuracy of 0.999 and a precision of 0.9984. That’s significant because it sets up the possibility of an automated process for spotting “interesting” sequences.
One application is immediately apparent. The mathematicians who run the OEIS currently have to process some 10,000 submissions a year. So a way of automatically spotting the most interesting could be useful.
However, the approach has some significant limitations. Mathematicians have defined many interesting and important sequences that have an infinite number of terms but are hard to calculate. Consequently, the database contains only a handful of these terms. These are obviously not suitable for this kind of machine-based analysis.
The broader question is whether this approach can identify elegance or beauty in mathematics. As Wu asks: “Can machine learning identify qualitative attributes of scientific knowledge; i.e., can we tell whether a scientific result is elegant, simple, or interesting?”
This goal may not be entirely futile. If empirical laws such as Benford’s and Taylor’s are an indicator of “interestingness,” as this work suggests, then perhaps this algorithm can be thought of as an arbiter of elegance, at least at some level.
Euler, of the eponymous relation and one of the greatest mathematicians in history, would surely be fascinated.
Ref: https://arxiv.org/abs/1805.07431 Can Machine Learning Identify Interesting Mathematics? An Exploration Using Empirically Observed Laws
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.