Neural Networks Face Unexpected Problems in Analyzing Financial Data
One area where machine learning and neural networks are set to make a huge impact is in financial markets. This field is rich in the two key factors that make machine-learning techniques successful: the computing resources necessary to run powerful neural networks; and the existence of huge annotated data sets that neural networks can learn from.
For those who pioneer this approach, there is likely to be much low-hanging fruit. And yet the details about how this fruit is being harvested in real markets are hard to come by. If financial organizations are experimenting with neural networks (and they surely are), they’re playing their cards close to their chests.
So insights into the challenges that analysts face in applying neural networks to trading data are eagerly anticipated.
Enter Swetava Ganguli and Jared Dunnmon at Stanford University in Palo Alto, California. They ask how good different machine-learning techniques can be at predicting the future price of bonds. For this they compare fairly standard “shallow learning” techniques with more exotic neural-network techniques. And their results highlight the clear advantages that some techniques have over others.
First, some background. Bonds are a form of debt, a kind of IOU, that can be traded in an open market. They are different from stocks in various important ways.
Stocks are a claim on the future profits of a company, so their value is intimately linked to the profitability of a company for the foreseeable future. For this reason, stocks can rocket in price if a company’s profitability increases. They can also collapse if a company runs into trouble.
Bonds are generally much less volatile. They are a loan which the issuer promises to repay on a specific date while paying interest along the way. Their value is determined by the amount of cash they are likely to pay during their lifetime. This is generally just a few years, and this fixed time limit means they do not generally soar in price or collapse catastrophically.
And yet their price does vary according to factors such as interest rates, potential changes in interest rates, company performance, and the likelihood the debt will be repaid, the time until the bond must be repaid, and so on. Predicting this future price is an important task for bond traders, and it is not easy.
One significant problem is a lack of easily available pricing information. Stock traders can generally see offers, bids, and trades within 15 minutes of them being made. But bond traders are much less well served, say Ganguli and Dunnmon, because “the analogous information on bonds is only available for a fee and even then only in relatively small subsets compared to the overall volume of bond trades.”
And that leads to the curious situation. “Many bond prices are days old and do not accurately represent recent market developments,” say the researchers.
So Ganguli and Dunnmon ask an obvious question: is it possible to do better by mining the information that is available?
Their approach uses a data set of bond prices and other information that was posted to the online predictive modeling and dataset host, Kaggle.com, by Breakthrough Securities in 2014.
This data set consists of the last 10 trades in each of 750,000 different bonds, along with a wide range of other parameters for each bond, such as whether it can be called in early, whether a trade was a customer buy or sell or a deal between traders, a fair price estimate based on the hazard associated with the bond, and so on.
An important task in this kind of analysis is to work out which of the parameters are useful in predicting future prices and which are not. So at first glance, Ganguli and Dunnmon look for parameters that are highly correlated with each other and therefore reveal redundancy in the data set. Having removed this redundancy, they then test a number of data-mining techniques to see how well, and how quickly, they can predict future prices.
The techniques include principal component analysis, which removes redundant parameters and leaves those with true predictive power; generalized learning models, which is a shallow form of machine learning; and neural networks, which can find patterns in highly non-linear data sets and is thought of as a deeper form of machine learning.
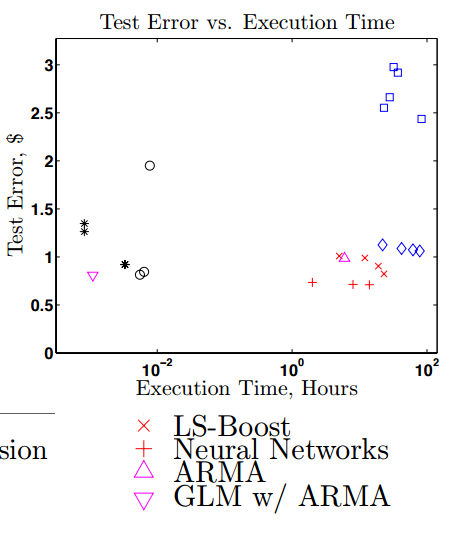
Perhaps unsurprisingly, the best predictions come from the neural networks, which forecast future prices with an error of around 70 cents. To put that in context, bonds are usually priced around the $1,000 mark. Interestingly, increasing the complexity of the networks has relatively little effect on their accuracy.
But the accuracy of a prediction is just one part of its utility. Just as important in the real world is how quickly the prediction can be made. And here, neural networks fall short, taking several hours to work their magic.
By contrast, the best shallow learning techniques make predictions with an error of around 80 cents, and they do it in just a few seconds. By combining some of these techniques into a hybrid system, Ganguli and Dunnmon say, they can make a prediction with an error of just 85 cents in just four seconds.
It’s not hard to imagine which prediction a bond trader would choose.
That’s interesting work that throws some light onto the dilemma that financial institutions must be facing in applying machine-learning techniques to financial data. Sure, there is plenty of scope for improving predictions, but can this be done on a time scale that is relevant?
That might give the lie to the reasons there are so few stories about the amazing gains that neural networks can make in the financial world. Perhaps those using these techniques are busy secretly hoovering up the low-hanging fruit before revealing their extraordinary successes to the world. That’s certainly happened in the past.
But there is another possibility. Perhaps they are struggling to find ways of doing this work efficiently on a time scale that makes a difference. If so, the low-hanging fruit is still there.
Ref: arxiv.org/abs/1705.01142: Machine Learning for Better Models for Predicting Bond Prices
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.