AI Machine Attempts to Understand Comic Books … and Fails
The list of activities in which artificial intelligence machines have bested humans is increasing at an alarming rate. Face recognition, object recognition, chess, Go, various video games, and numerous other tasks have all fallen in this battle.
So it’s natural to ask about the types of tasks that machines still have difficulty with. Where do humans still rule the roost?
Today, we get an answer of sorts thanks to the work of Mohit Iyyer at the University of Maryland in College Park and a few pals. These guys ask how well artificial intelligence can understand comic books and can hardly resist punching the air in revealing that the machines come a sorry second in comparison to humans.
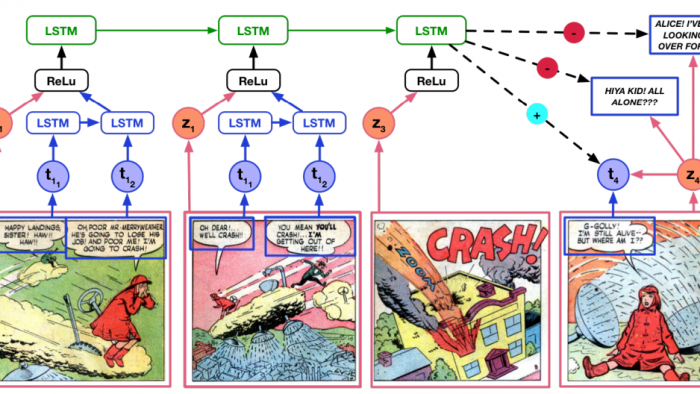
Comics tell stories using a sequence of panels consisting of hand drawn and often highly stylized pictures that are very different in character to photographs. These panels are also annotated with text in the form of thought bubbles, speech balloons, and narrative boxes.
The text and pictures work closely together; often so closely that the story cannot be followed using the pictures or text alone. Even then, the reader has to make significant inferences and extrapolations when jumping from panel to panel. Much detail has to be filled in by the reader.
“It is what the creator hides from their pages that makes comics truly interesting, the unspoken conversations and unseen actions that lurk in the spaces (or gutters) between adjacent panels,” say Iyyer and co. It is in deciphering these details that the story is forged in the readers’ imagination.
This complex process of viewing an individual panel and understanding how it connects to previous ones is called “closure.” And for the moment it is a uniquely human ability.
That’s why Iyyer and co devised an experiment to test how well machines can perform it as well.
These guys begin by creating a large database of comic stories that they can use to train deep learning machines. They create this using comics published between the 1930s and 1950s. This was the so-called golden age of comics, which ended in the late 1950s, when strict censorship regulations were introduced in the U.S. The copyright has since expired on these publications, and they are publicly available on a website called the Digital Comics Museum in the form of user-uploaded jpegs.
Iyyer and co used 4,000 of the highest-rated comic books on the site, creating a database of over 1.2 million panels. They use optical character recognition to digitize the text on each panel.
To test closure, Iyyer and co devise a set of experiments in which a machine is shown a sequence of panels and then has to predict what comes next from a set of possible answers. The task can be to predict the next picture or the next piece of text or to match the text to a specific character.
First, the machine has to learn how comics work. So the team fed a proportion of the panels and texts to various machine-learning algorithms so that they could learn how panels follow on from each other. These machines are pretrained to recognize objects but in natural images rather than cartoons.
Having trained the machines, the team then tests them on a set of panels they haven’t seen and ask them to predict the next image or piece of text in the series.
The results are eyebrow-raising. While humans can predict the next piece of text or the next image correctly more than 80 percent of the time, the machines never come close to this level of accuracy. “None of the architectures outperform human baselines, which speaks to the difficulty of understanding comics,” say Iyyer and co. “Image features obtained from models trained on natural images cannot capture the vast variation in artistic styles, and textual models struggle with the richness and ambiguity of colloquial dialogue highly dependent on visual contexts.”
That’s not surprising given the common sense needed to follow these stories and the cultural knowledge required to understand the logic of storytelling in comics.
So humans are still masters of this task, for the moment at least.
But the machines will surely get better as they learn the social and inference skills that we think make us human.
And that raises an interesting possibility. AI machines have beaten humans at chess, Jeopardy!, Go, and many other tasks. Perhaps their next challenge should be to understand comics better than humans, and perhaps even create narratives in this way. That would pit Google DeepMind or any of its competitors against the characters in Marvel or DC Comics. The perfect battle and certainly one that would be fun.
Ref: arxiv.org/abs/1611.05118: The Amazing Mysteries of the Gutter: Drawing Inferences Between Panels in Comic Book Narratives
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.