Face of a Robot, Voice of an Angel?
The last time you heard a computer convert a line of text to speech, it probably jarred. Google’s machine-learning division, DeepMind, has developed a new voice synthesis system using artificial intelligence that it thinks will improve the situation.
Having a computer generate the sound of a voice isn’t a new idea. Perhaps the most common approach is simply to use an incredibly large selection of pre-recorded speech fragments from a single person. In a technique called concatenative synthesis, these are pieced together to create larger sounds, words, and sentences. That’s why a lot of computer-generated speech often suffers from glitches, quirky changes in intonation, and pronunciation stumbles.
The other competing approach uses mathematical models to re-create known sounds that are then assembled into words and sentences. While less prone to glitches, this so-called parametric approach does end up sounding robotic. What unites the two approaches, though, is that they both stitch together chunks of sound, rather than creating the whole audio waveform from scratch.
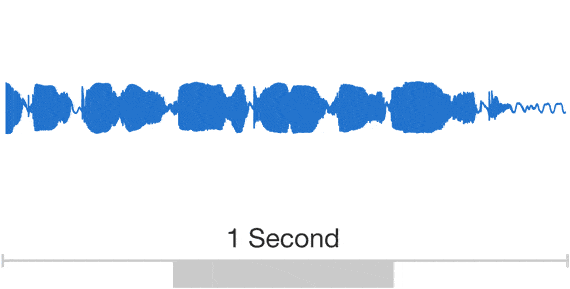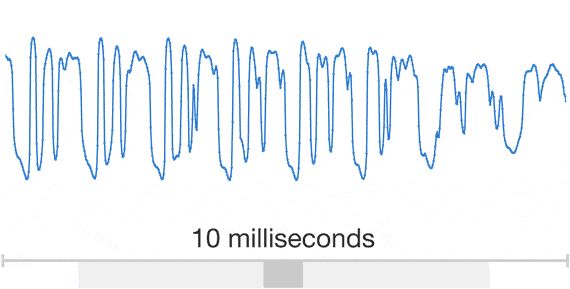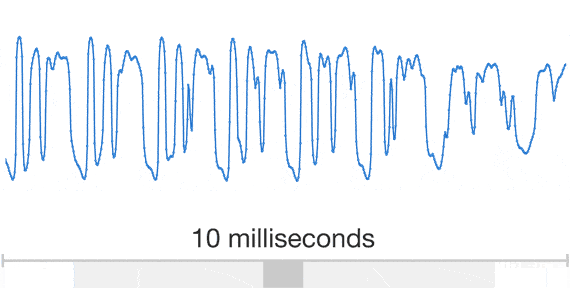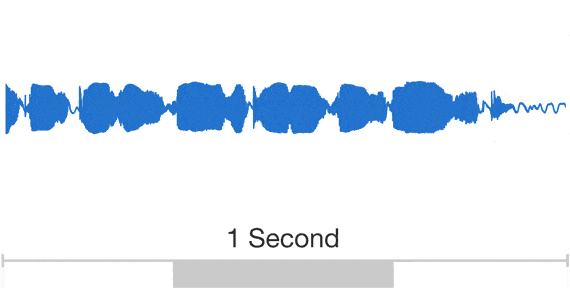
That, though, is exactly what DeepMind’s approach does. WaveNet’s convolutional neural networks are taught by feeding them clips of real human voices and the corresponding linguistic and phonetic features so that they can identify patterns relating the two. In use, the system is supplied with a new string of sound features generated from a line of text; then it attempts to create the raw sound wave to represent it from scratch. It does this stepwise, first generating one sample of the sound wave, then the next, and the next—at each point using information about the samples that it’s already created to help inform a new one.
The results do sound compelling—you can listen to them yourself here. Compared with the concatenative and parametric approaches, it’s noticeably more humanlike.
There is, however, a catch: the technique requires a ton of computational horsepower. Because WaveNet has to create the entire waveform, it must use its neural network processes to generate 16,000 samples for every second of audio it produces (and even then, the sound is only equivalent to the quality of sound sent via telephone or VoIP calls). According a DeepMind source who spoke to the Financial Times (paywall), that means it won’t be used in any of Google’s products for now.
Still, it’s not the only language problem that computers face. Interpreting speech and the written word is notoriously difficult for artificial-intelligence systems, too. At least at this rate when computers can muster the wherewithal to generate truly intelligent musings, they’ll also be able to communicate them to us with a flourish.
(Read more: DeepMind, Financial Times, “AI’s Language Problem”)
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.