Is This the First Computational Imagination?
Imagine an oak tree in a field of wheat, silhouetted against a cloudless blue sky on a dreamy sunny afternoon. The chances are that most people reading this sentence can easily picture a bucolic scene in their mind’s eye. This ability to read a description of a scene and then imagine it has always been uniquely human. But this precious skill may no longer be ours alone.
Anyone thinking that these kinds of imaginings are far beyond the ability of today’s computing machines will be surprised by the work of Hiroharu Kato and Tatsuya Harada at the University of Tokyo in Japan.
Today, these guys unveil a machine that can translate a description of an object into an image. In other words, their computer can conjure an image of an external object not otherwise present. That’s a pretty good definition of imagination—in this case of the computational variety.
For sure, these computer imaginings are simple, sometimes confusing and often nonsensical. But the fact they are possible at all represents a significant step forward for computational creativity.
Computer scientists have long struggled to handle images with the ease and power that they manage with words. It is straightforward, for instance, to enter a word or sequence of words into a search engine and find matches that are highly relevant.
This is not because of some special computing ability to understand words. It comes about merely by treating the words statistically, like counting them out of the bag. Indeed, bag-of-words techniques like this have become hugely powerful. By contrast, there is no equivalent ability for images.
So a few years ago, computer scientists began to treat images in the same way. They began by thinking of an image as a series of pixels which they divide into short sequences that correspond to a specific part of an image. For example, a short sequence might correspond to the edge of a cup or an area of skin or part of the sky and so on.
These short sequences mean little to humans but to a computer they can be treated like words. So a computer could analyze a picture by counting the number of sequences and how often they occur, just as it might treat a document by counting how often words appear. A picture of the sky would have lots of sequences that correspond to parts of the sky. And a picture of a tea cup would have many sequences that correspond to the edge of a cup and so on.
That immediately allows pictures to be compared. A computer can search through a database of images analyzed in this way looking for similar patterns of sequences in other pictures. The idea is that two pictures with similar distributions of sequences should look similar and researchers have indeed had some success with this technique for finding matches.
By analogy with text, computer scientists call these sequences “visual words.” And this new approach to image analysis is known as the bag-of-visual-words technique. It analyzes an image by counting the statistical distribution of the visual words it contains.
The question that Kato and Harada address is the opposite of this. Given a distribution of visual words, what was the original image? That is a much harder problem because, although a visual word describes part of an image, it does not explain where in the image it came from or what other visual words it was close to.
“This problem is similar to solving a jigsaw puzzle,” they say. The visual words are the pieces and the problem is to decide how to fit them all together to make a picture.
Kato and Harada tackle this problem in two different ways. The first is to assess how individual visual words fit together smoothly next to other visual words. For example, all the visual words that describe the edge of a cup can be fitted together to show continuous edge.
This is not straightforward because visual words have no apparent shape and so do not fit together like jigsaw pieces. Instead, Kato and Harada measure the relation between visual words in a large database of images by counting all the pairs that occur next to each other. That produces a likelihood that a pair of visual words should be next to each other
The second method is to assess the likelihood that a given visual word should appear in a certain part of the picture. For example, a visual word showing an area of sky is more likely to be at the top of an image.
Since the visual words themselves do not contain this information, Kato and Harada again measure it in a large database of images. “Each visual word is presumed to have a preference of the absolute position to be placed at,” they say. This preference is the measured value taken from the entire database.
Of course, these calculations are computationally expensive, depending on the size of the database and the size of the visual words.
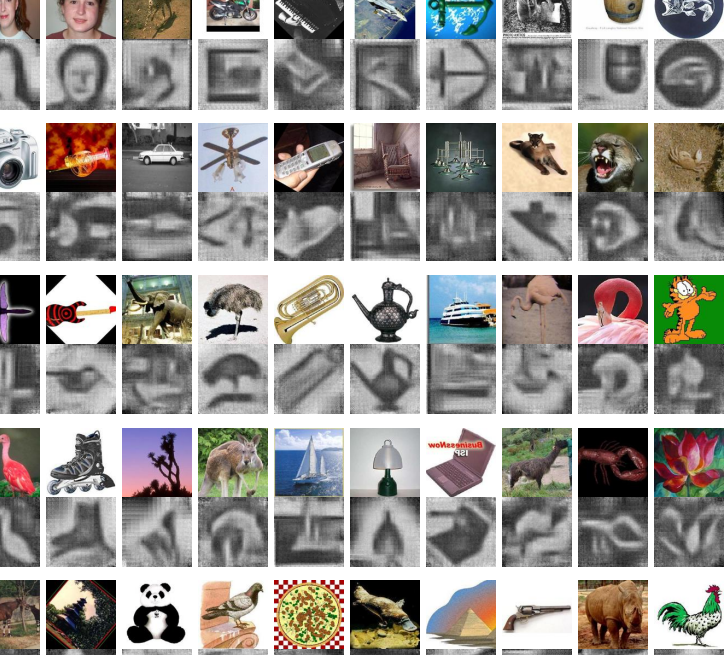
Nevertheless, Kato and Harada have demonstrated considerable success with their approach. They create a database of 101 images each showing a different kind of objects. They resize each image to 128 x 128 pixels and assumed that each picture is made up of visual words 13 x 13 pixels in size and that three quarters of each visual word overlaps the next visual word.
Having created the database showing the statistical distribution of the visual words, they then use this information to attempt to reconstruct an image using only the visual words that appear it.
The results are generally impressive. While some of the generated images are nonsensical others successfully recreate a wide range of images, for example, of an umbrella, a spanner, a barrel, a fish, and even a face (see the images and their reconstructions above).
That’s impressive and it leads to a number of interesting applications. Kato and Harada use it to morph one image into another, for instance. They take the bag of visual words that represents two images and then generate intermediate bags of visual words to create the intermediate pictures in the morphing sequence.
More interesting is their work on computer vision. Computer scientists have recently developed powerful automated object recognition algorithms that identify specific objects.
These algorithms are known as classifiers. They work with high accuracy but can sometimes be fooled by objects that appear straightforward to identify to the human eye. So exactly what they look for is not always clear.
Kato and Harada’s work changes this. They have used their bag of visual words approach to visualize these object classifiers. “This reveals differences between human vision and computer vision,” they say.
They do this by using the classifiers to study 10,000 randomly chosen images and simply count the visual words that trigger each classifier most often. They then assemble these visual words into an image using their bag of visual words technique.
And the results are fascinating. Some of the visualized classifiers are remarkably similar to the objects themselves, at least as far as human recognition goes. Others are strangely warped, like works of modern art. And others show how additional elements can be important, for example, how the horizon is important for identifying trees.
Finally, Kato and Harada use their approach to generate images from ordinary sentences. They do this by converting each word in the sentence into a bag of visual words and then convert this into an image.
Converting ordinary words into a bag of visual words is a tricky task. The researchers do this by searching through a dataset of images with captions. Each time a word appears in a caption, they add the visual words in the picture to a bag. This creates a large bag of visual words from which it is possible to generate an image.
The results are fascinating. “Several sentences are translated to completely nonsense images,” admit Kato and Harada. That is probably because the method of converting a word into a bag of visual words is too simple. But others sentences produce dreamlike images that are loosely connected with the original idea (see pictures below).

Kato and Harada say this is a promising beginning and opens the way to a new generation of image creation systems.
That’s truly fascinating work that is a significant step forward in computational creativity. Ask Google to define “imagination” and it says this: the faculty or action of forming new ideas, or images or concepts of external objects not present to the senses. So it’s by no means a stretch to say that Kato and Harada have created the world’s first computational imagination.
Ref: http://arxiv.org/abs/1505.05190 : Image Reconstruction from Bag-of-Visual-Words
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.