Machine Learning Algorithm Mines 16 Billion E-Mails
Electronic mail plays a hugely important role in the lives of a large fraction of the world’s population. And yet, strangely, little is known about the way people use e-mail. How many e-mail conversations do people have? How long are these conversations and how do they end? And how does the volume of incoming mail affect people’s behavior?
Today, we get an answer to a range of questions like these thanks to the work of researchers at Yahoo Labs in Barcelona and California and at the University of Southern California. These guys have studied patterns of behavior in a database of 16 billion e-mails exchanged between two million people over several months. “We believe ours is the first large scale analysis of e-mail conversations,” they say.
It turns out that e-mail patterns are so reliable that a machine learning algorithm can predict in advance how long a reply is likely to be and when an e-mail conversation is likely to end. That’s information that could play an important role in the next generation of e-mail systems.
It’s easy to imagine that computational anthropologists must have been poring over vast e-mail databases to determine the impact of this relatively new form of messaging on ordinary lifestyles.
Not so. The relatively few completed studies have been done on small samples of e-mails and resulted in relatively simple discoveries. These include the fact that some people reply to e-mails in the sequence they arrive while others pick and choose the most important to reply to first.
To remedy this gap in in our knowledge, Farshad Kooti at the University of Southern California and pals study a database of 16 billion e-mails in Yahoo Mail from people who had agreed to allow their data to be used for research.
Because much of the e-mail people receive is spam or is generated automatically, the team chose only those e-mails that have been sent between two individuals in a conversation lasting at least five exchanges.
These 16 billion e-mails came from the e-mail accounts of two million unique users and included only e-mail from commercial domains and from other Yahoo users who had opted in to the research. Of these 16 billion, 187 million e-mails were exchanged between pairs of users in the dataset. These were essentially the ones of interest.
The researchers were then able to study the statistical nature of this form of pairwise communication using information such as sender ID, receiver ID, time sent, the e-mail subject, the body of the e-mail and the number of attachments.
To ensure privacy, the researchers anonymized the senders and receivers and no human analyzed the contents of the e-mail bodies. Instead, the researchers used algorithms to extract statistics from the e-mail bodies, such as their length, the number of e-mail ids in a thread, and so on.
The team grouped e-mails between individuals if they shared the same subject line, (all but one of which would start with “Re:”) and ordered the messages according to their timestamp.
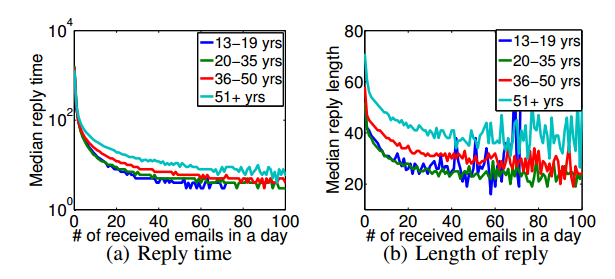
They then studied various features of these e-mail chains, such as the time it takes to reply to an e-mail, the length of the reply as well as how these factors vary according to the age and sex of the sender and so on.
The results make for interesting reading. It turns out that younger people send faster, shorter replies and that men send slightly faster and shorter replies than women.
The time of writing is also a factor. “We found that users reply faster to e-mails received during weekdays and working hours, and that replies tend to become shorter later in the day and on weekends,” say Kooti and co.
And mobile devices have an impact too. “Replies from mobile devices were faster and shorter than from desktops, and e-mails without attachments typically got faster replies,” they say.
An increasingly important phenomena is e-mail overload. Kooti and co found that as people receive more e-mails, they increase the rate at which they reply but not by enough to compensate for the higher load.
In other words, as people become more overloaded, they reply to a smaller fraction of incoming e-mails with shorter replies. “However, their responsiveness remained intact and may even be faster,” say the researchers.
The team also looked at the differences between an e-mail and its reply, such as the number of words used and the time between responses. Interestingly, during the first half of an e-mail conversation, replies become more similar, both in reply time and length. However, all that changes after the middle of the threat when the reply behavior becomes increasingly different.
These patterns allowed the team to build a machine learning algorithm to spot the various stages of e-mail conversations and predict when they are likely to end. They trained this algorithm to predict the time and length of replies and whether an e-mail was the last one in the thread.
And although these predictions are not perfect, they are good enough to have an impact on the way e-mail systems might be designed in future. “Ability to accurately predict what messages a user will reply to can be used by e-mail clients to rank e-mails in the users’ inbox by their replying priority, thus helping ease the burden of information overload,” say the team.
That’s interesting work that could help determine the way algorithms handle our e-mails in future. Anything that usefully helps to ease the burden of e-mail overload could become an important part of the hidden bureaucracy of communication.
Yahoo has a clear interest in this kind of work so it is surprising this kind of study has been done for the first time now. With any luck, the process of incorporating these findings into future e-mail systems will not take quite so long.
Ref: arxiv.org/abs/1504.00704 : Evolution of Conversations in the Age of E-mail Overload
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.