How Machine Vision Is Reinventing the Study of Galaxies
Galaxy Zoo is one of the more remarkable crowd-sourced science projects on the Web. Since 2007, it is enlisted the help of more than half a million citizen scientists around the world to classify images of almost a million galaxies.
This effort is in the process of revolutionizing our understanding of galaxy formation. The shapes, the sizes and the colors of galaxies are the result of their age, the conditions under which they formed and the interactions they have had with other galaxies over many billions of years.
So a detailed classification of galaxy types is crucial for teasing apart the origins of these bodies. Indeed, Galaxy Zoo was conceived as a solution to the problem of classifying the 900,000 galaxies that have been photographed by a project known as the Sloan Digital Sky Survey.
That sounds ideally suited to machine intelligence. But although the task of classifying galaxies is relatively simple for humans, it has always been beyond the reach of machine vision technology. Until now.
In the last couple of years, major advances in a technique called deep convolutional neural networks has made machine vision the equal of human vision in many tasks. For example, in the last year or so deep convolutional neural networks have become as good as humans at face recognition, a problem that has stumped computer scientists for decades.
Compared to face recognition, galaxy classification ought to be child’s play. And so it is turning out to be. Today, Sander Dieleman at Ghent University in Belgium and a couple of pals say they have perfected a convolutional neural network that can accurately classify a wide range of galaxies, an achievement that promises to automate much of the work that Galaxy Zoo now does.
What’s more, the machine vision approach scales more effectively than crowdsourcing, meaning that computers should be able to analyze the many hundreds of millions of images of galaxies that observatories around the world and in space are set to produce in the coming years.
Machine vision has improved significantly in recent years because of two separate factors. The first includes improvements in technology, such as more effective convolutional neural networks and faster computers.
The second is the fact that large training datasets have suddenly become available thanks to the new phenomenon of crowdpower. For galaxy classification, this training dataset comes from the Galaxy Zoo process itself in which hundreds of thousands of humans have annotated images of galaxies.
This huge dataset is crucial. Computer scientists use these kinds of annotated datasets to train neural networks to recognize specific features—in this case whether a galaxy is smooth and rounded, whether it has a bar through the center, whether the center has a bulge or if there are any signs of spiral arm patterns and so on.
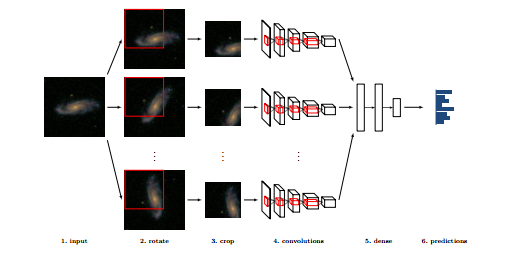
These are exactly the questions that the crowd has already answered in the Galaxy Zoo dataset. So it is relatively straightforward to take a sample of the data to train a convolutional neural network. Dieleman and co pick out some 60,000 annotated images for this task.
That is a relatively small training dataset by modern standards. So to increase its size, they altered each of the images by changing its centering, flipping it to create a mirror image and above all by rotating it so that the neural network would learn to exploit the rotational symmetry of galaxies.
That’s hugely important because a galaxy’s classification should not depend on the orientation in which it is viewed. Capturing that property of invariance is crucial.
Dieleman and co then use this dataset to train a convolutional neural net to recognize the shape and structure of galaxies, answering questions such as how many spiral arms there are, how tightly wound they are, is anything odd about the galaxy, and so on (the same questions that humans have already answered). Their network consists of seven layers that each effectively filter the data for higher-level features.
The team then uses the trained network to evaluate a further 80,000 images that are not annotated and then compare the results to the accuracy of human classification.
The results are impressive. Dieleman and co say that for most classifications, the accuracies achieved by humans and machines are comparable. “Our novel approach to exploiting rotational symmetry was essential to achieve state-of-the-art performance,” they point out.
However, they are careful not to say directly that their machine vision classification is better than human classification. That call will inevitably be left to other observers. What they do say is that machine vision will make the task of experts easier. “This approach greatly reduces the experts’ workload without affecting accuracy,” they conclude.
The most important advance is that this technique can be scaled much more effectively than crowd power. After all, convolutional neural networks can work 24/7 and never tire. “The application of these algorithms to larger sets of training data will be critical for analyzing results from future surveys,” say Dieleman and co.
Indeed, only a diehard sceptic would say that this technique will not change the way galaxies are classified in the near future.
That does not mean humans will be excluded from the process of galaxy classification. Far from it. This kind of automated work depends crucially on the quality of the training dataset. So if astronomers want to ask different questions about galaxies and use machine vision to answer them, they will first have to create a large training dataset that has been accurately annotated by humans.
So the role of crowdpower is set to change and, in a sense, become even more important. In future citizen scientists will produce the gold standard training datasets that machine vision algorithms will use to learn their tasks.
That will be important work and it looks set to continue for some time. At least, until a new generation of intelligent machines will do away even with that step.
Ref: arxiv.org/abs/1503.07077 : Rotation-Invariant Convolutional Neural Networks For Galaxy Morphology Prediction
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.