Algorithm Predicts Circles of Friends Using Contacts Data
One important feature of social networks is the ability to group friends and contacts into lists or circles. Typical circle classifications include members of the same family, friends from university, colleagues from work and so on.
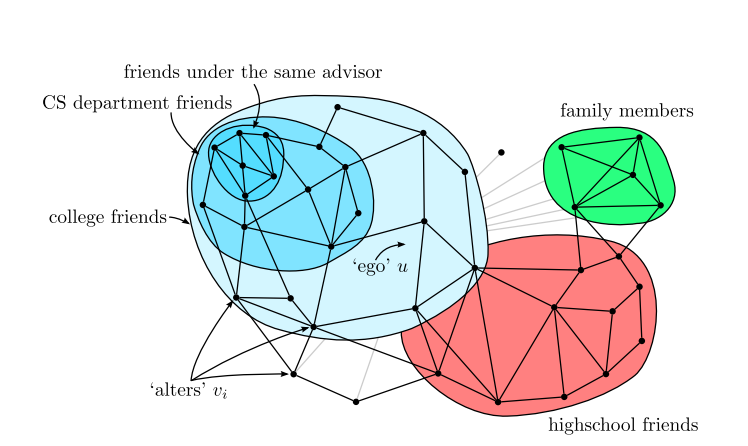
One problem, however, is that creating and maintaining these circles is a time consuming business. So a useful tool would be an algorithm that analyses a user’s entire list of contacts and automatically divides them up into useful circles.
Today, Julian McAuley and Jure Leskovec from Stanford University say they’ve developed an algorithm that does just that. The algorithm can predict a user’s set of circles from scratch without any user input at all and then predicts which circles new users should be added to.
The algorithm works by analysing the profile information associated with each person in a user’s set of contacts. On Facebook, for example, this would include name, sex, age, location, company, company location, education and so on.
It then looks for links between these contacts. So a circle might consist of all the people who went to the same university or who work at the same company or who share the same surname and so on.
It then looks for links with the user, whether it be those who work at the same company, went to the same high school and so on. Having learnt the set of parameters that link contacts in the same circle, it then hunts for others with a similar profile.
McAuley and Leskovec say a crucial feature of this algorithm is that contacts can appear in more than one circle and that these circles can overlap or be nested within each other. For example, one circle might consist of all the people at the same university and another might consist of all the people who took the same class, a circle that is clearly nested within the first.
Finally, McAuley and Leskovec asked ten Facebook users to draw up and fully annotate all the circles in their social network using 26 different variables to categorise their contacts. This dataset consisted of 4039 contacts which formed into 193 circles for these ten users. On average each user identified 19 circles with 22 contacts in each circle.
Finally they set their algorithm to work on the raw data to see if it could find the circles that the users themselves had identified.
The results are decent but far from perfect. For example, the algorithm never identifies more than 10 circles per user. However, McAuley and Leskovec say their algorithm outperforms all others that aim to do a similar job.
They carry out a similar analysis on publicly available data from 133 Google+ users, consisting of 479 circles and over 100,000 contacts. They do a similar analysis of 1000 Twitter users with over 80,000 contacts organised into more than 4,800 circles.
These data sets are much less rich than the Facebook set. Google+ offers 6 categories of information per contact and Twitter only 2. What’s more the links between users are directed in these datasets. For example, one circle on Google+ contains candidates from the 2012 republican primaries who presumably do not follow this user or each other.
Nevertheless, McAuley and Leskovec say their algorithm outperforms the competition. Howeve, it is unable to reconstruct circles as accurately as with the richer Facebook data.
This algorithm is certainly an interesting approach. The ability to automatically create circles from a user’s contacts list is certainly valuable, The algorithm also has the ability to add new contacts to appropriate circles.
An important limitation, however, is the scalability of the approach. McAuley and Leskovec admit their algorithm is not particularly efficient, taking about an hour to identify ten circles from a list of 1000 Facebook contacts. That’s a lot of hours of processing for Facebook’s 1 billion users.
However, they say that the technique should be quicker as broader patterns become clear once all users contacts have been taken into account. For example, it may be possible to identify the set of all people on Facebook who went to a particular university. Then one person’s circle might consist of the intersection between this set and their contact list.
Just how much of a speed up this would allow isn’t clear though.
Another important question for the future is how well in principle automatically-generated circles can be made to match ground truth circles, using only the information available in contact profiles and so on. It may be that many circles are created using information that users do not explicitly make available on social networks, such as a circle of ‘best friends’.
If that’s the case, then these algorithms will never be able to reconstruct the ground truth circles perfectly. But perhaps this doesn’t matter if they provide a reasonable approximation to ground truth circles that users can tinker with at their leisure.
Another interesting approach is to look for patterns of links between contacts that users do not turn into circles–in other words connections between people that users have not recognised or want to keep hidden. Such a pattern might be linked with criminal activity, for example, or point to marketing information that could be sold.
This opens up various ethical minefields. Who should have access to the results of this kind of data processing, for example?
One thing’s for sure, the potential is huge, as the owners of social networks have long recognised. Which means we’re bound to see more of these kinds of applications in the not too distant future.
Ref: arxiv.org/abs/1210.8182: Discovering Social Circles in Ego Networks
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.