Drowning in Data
The personalized-medicine industry aims to convert information about an individual’s genome into useful diagnostic tests and targeted drug treatments. Companies that deal with gathering the information–sequencing genomes and identifying genetic variations–have made impressive technical advances that have dramatically reduced the cost of analyzing DNA (see “Faster Tools to Scrutinize the Genome”). Now the biggest challenge lies in interpreting the huge volume of genetic data being generated. Studies have identified thousands of candidates for genes underlying common diseases, for example, but it’s not clear how to make that information medically useful.
The problem is going to get worse before it gets better. Most genetic variation discovered to date accounts for a fairly small percentage of the overall risk of disease. Countless genetic variations are still hidden in our genomes. As scientists begin to uncover the remaining genetic culprits, they will need to develop ways to interpret what those variations mean for individual health. “The field urgently needs a breakthrough in the way we analyze such data, or we will end up with a collection of data … unable to predict anything,” wrote Serge Koscielny, a researcher at the National Institute of Health and Medical Research in Villejuif, France, in the journal Science Translational Medicine in January.
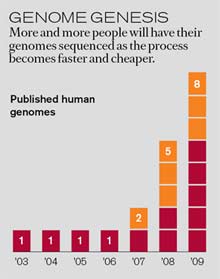
Efforts to find solutions are just beginning. Personal-genomics companies such as 23andMe and Navigenics have developed their own algorithms for combining different genetic risk factors into a predictive risk score. And Knome, a personal-sequencing startup based in Cambridge, MA, is taking this strategy one step further by developing software to analyze entire genome sequences. But it will be impossible to develop effective analysis methods–or weigh their predictive power–without large databases that pair individuals’ genome sequences with their medical records.
Genetic tests and therapeutics also face an economic challenge: who will pay for them? Insurance companies will not cover these diagnostics unless they are proved to be both effective–accurately spotting whether a person will respond to a drug, for example–and cost-effective. Insurers would be motivated to pay for tests that could rule out an expensive cancer treatment as unlikely to work. But with drugs that are inexpensive in the first place, the financial case for such testing is less obvious.
If scientists succeed in developing tests that can accurately predict an individual’s risk of disease years or decades in advance of symptoms, the problem of who pays will become even trickier–especially in the United States, where people change insurance plans every three to four years on average. Pharmacy benefits managers such as Medco and CVS Caremark, which provide prescription-drug coverage to many Americans on behalf of employers and insurers, are starting to take the lead in judging the economic value of personalized medicine (see “Sequencing Companies Dominate Investment”).
To explore how specific parts of the genome have been linked to different diseases, click on one of the diseases above. The map will point to spots on certain chromosomes that raise the risk of that disease. This map includes only a handful of the disease-linked genes that have been uncovered to date. For a more complete listing, visit the U.S. National Center for Biotechnology Information morbidity map.
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.