Simpler Programming for Multicore Computers
The number of cores–or number-crunching units–in microprocessors is doubling with each generation, providing enormous computing potential for desktops, laptops, and, eventually, handheld gadgets. Current quadcore machines, for example, are particularly useful for such computation-hungry applications as video processing and gaming. However, the new multicore machines are basically small-scale supercomputers, and in order to take full advantage of the computing power they offer, software must be written with multiple cores in mind–a time-consuming and difficult task known as parallel programming. And many experts believe that unless parallel programming can be made easier, computing progress will come to a grinding halt.
Researchers at MIT are looking for a way to ease the pain of parallel programming. They have designed a computer language and a compiler–a specialized tool that converts the language into computer instructions–that essentially hides the parallel-programming challenges, yet takes advantage of the power of multiple cores. The language and compiler, called StreamIt, were developed by Saman Amarasinghe, a professor of electrical engineering and computer science at MIT. StreamIt currently runs on a specialized multicore machine built at MIT, but by this summer, Amarasinghe expects to have the software ready to run on commercial chips made by IBM, Sony, and Toshiba found in Sony’s PlayStation 3 machines.
“Creating software is still something a lot of people can do, but if they had to deal with parallelism, it becomes much more difficult,” says Amarasinghe.
In single-core machines, software code runs, for the most part, sequentially. This means that tasks–such as accessing certain chunks of memory to open a program–occur one after another, in a predictable way. In a multicore system, tasks get split up among cores. And when different tasks need to access the same chunk of memory, the tasks have to work together to carefully orchestrate–or synchronize–the accesses. If multiple tasks inadvertently access the same data without proper synchronization, the data will get corrupted, producing incorrect results or crashing the program.
In single-core machines, it’s fairly easy to debug programming errors or unintended problems because the cause can be traced back to a particular instruction. But Amarasinghe says that some bugs in parallel systems are more difficult to fix because they are probabilistic–meaning that they only arise occasionally; each time the program runs, the multiple cores execute their tasks independently, leading to billions of possible execution orders for the program.
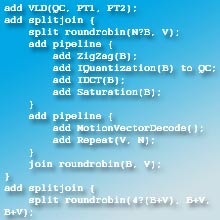
Amarasinghe’s solution is based on a well-known concept called data flow, in which data is streamed sequentially through a sort of pipeline of functions. As the data flows the compiler sees which functions are independent. Thus, the compiler can place separate tasks on different cores, not worrying that they will interfere with one another or touch the same piece of memory.
A programmer only needs to write software that operates in a sequential way. The compiler sees all the interactions that need to occur, based on the code written by the programmer, and allocates the instructions appropriately to keep bugs from arising.
It is a sound idea based on well-known concepts, says Ras Bodik, a professor of computer science at the University of California, Berkeley. “If you want programmers who are not experts in parallelism to be productive, if you want them to effectively write programs, you want to give them a language like StreamIt,” he says. However, Bodik suspects that software engineers will need to rely on a hierarchy of tools that operate at different levels. For instance, transactional memory, which allows numerous tasks to share the same memory at the same time, could operate behind the scenes, helping maximize StreamIt’s potential. (See “The Trouble with Multi-Core Computers.”)
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.