Jaime Teevan
Using personal information to improve search results.
In 1997, when search engines were relatively new, Jaime Teevan took an internship at Infoseek the summer before her senior year at Yale. William Chang, the chief technology officer, put her in a room with some research and told her to “find something fun to do.” She came up with some ideas for judging link quality and helping people navigate the company’s search engine, and she wrote the code to implement the changes. “Once, I brought the search engine down for a couple of hours,” she says with a laugh.
But she also discovered a career path. Today, the Microsoft researcher is a leader in using data about people’s knowledge, preferences, and habits to help them manage information. She studies the ways people navigate the flood of information available in the digital age and builds tools to help them handle it.
By now, personal information management has become an Internet buzzword. But Teevan pioneered the field as a graduate student working with David Karger, a professor in MIT’s Computer Science and Artificial Intelligence Laboratory. “She literally almost single-handedly created this whole area,” says Eric Horvitz, a principal researcher who manages teams pursuing advances in search and retrieval at Microsoft Research.
She began by studying how people search the Internet. They use such different strategies, she found, that a one-size-fits-all search engine can never satisfy everyone. So Teevan started building tools that sort Internet search results according to a user’s personal data, previous searches, and browsing history.
One of her first tools was a search engine called Re:Search. Early on, Teevan discovered that people are often looking for information they’ve already found before; more than half of all Web-page visits and a third of all search queries are repeats. But since the Web is always changing, people often have a hard time finding a site again. Re:Search relies on information from a user’s past searches to determine which items are more relevant to him or her. Teevan found that people tend to remember the first item in a list of previous search results, as well as items they clicked on; they also tend to get confused if the results they clicked on have changed position in the list. So she designed Re:Search to keep clicked links in their previous positions and insert new links in positions where they will be noticed without being confusing or distracting.
One of Teevan’s key ideas is that search engines can employ information about users to help them zero in on the results they need. Since she joined Microsoft Research in 2006, she’s developed a number of experimental browser plug-ins that work with Internet Explorer and that will refine search results for each user. One, called PSearch, uses an index of documents, e-mails, and other material on the user’s hard drive to customize the results delivered by an Internet search engine. For instance, if she types her husband’s last name into a typical search engine, the top hits are for a financial-services firm that shares his name. When she turns PSearch on, the first sites listed relate to her husband.
Horvitz says that Psearch has been piloted internally at Microsoft for a number of years and has proven very promising. “What I like best is that all the personalization is going on on your desktop,” he says. In fact, PSearch never shares a user’s personal information with the search engine–the results are re-sorted after they’re delivered to the user’s computer.
Teevan’s programs have yet to be released commercially, and because search is such a competitive area for Microsoft, both she and Horvitz declined to discuss any such plans. But both eagerly talk about her contributions to Microsoft’s new search engine, Bing. Teevan says she met regularly with Bing’s developers to help them understand how people search and how that knowledge might be used to improve search results. Horvitz points more directly to the left-hand column of the Bing search results page, where a short list titled “Search History” appears. “You see just the tip of the iceberg right now in the current Bing search.” Teevan’s work is actually more advanced, Horvitz says. Hinting at things to come, he adds, “You might watch that corner of Bing over time.”
Michael Backes
Proving that Internet security protocols can really be trusted.
Problem: To help protect Internet users’ privacy, cryptographers have developed zero-knowledge proofs, which allow users to demonstrate that they know, say, a password or bank-account number without actually revealing what it is. IBM, Intel, and Hewlett-Packard have used these proofs as the basis for a new Internet security protocol, similar to the Secure Sockets Layer that protects e-commerce transactions. But while the proofs themselves are secure, it’s hard to be sure that the protocols based on them are free of glitches that could allow them to be hacked.
Solution: Software designed by Michael Backes, a professor in the information security and cryptography group at Saarland University in Saarbrücken, Germany, can prove in less than a second whether an Internet protocol is truly secure. The program, the first one that’s been able to test protocols based on zero-knowledge proofs, creates simplified mathematical representations of the proofs and evaluates how they work within the protocol. The result is that it can efficiently check to see whether individual instructions in a protocol might let an interloper into the system.
Jeffrey Bigham
Free service to help blind people navigate the Web.
Problem: More than 38 million people worldwide have low or no vision. To use the Web, many use screen readers, which speak on-screen text aloud. But this software is expensive and is rarely installed on public computers in libraries or cybercafés; in such places, simple tasks such as confirming flight information or checking e-mail can be impossible for blind users.
Solution: As a graduate student at the University of Washington, Jeffrey Bigham created WebAnywhere, a free screen reader that can be used with practically any Web browser on any operating system–no special software required. Users start at webanywhere.cs.washington.edu; from there, they can use keyboard commands to navigate to any Web page. While other screen readers synthesize speech from text locally, WebAnywhere fetches speech from a central server and sends the audio to the user’s computer. “The potential is there for big lag times between when the user presses a button and gets speech back,” says Bigham, now an assistant professor in computer science at the University of Rochester. “Pretty much everyone thought that this latency problem would kill us.” To speed things up, he created a model that predicts which parts of a page a user is most likely to interact with, such as links, and preëmptively fetches audio describing that content. The result is that WebAnywhere sends synthesized speech to users within a fraction of a second. –Stephen Cass
Jeffrey Heer
Easy-to-use tools allow people to present data in creative and interesting ways.
Lists of numbers often don’t mean as much as charts, graphs, and interactive graphics that can reveal unexpected trends. To help people make them, Jeff Heer, an assistant professor of computer science, led a project that created easy-to-use open-source visualization software called Protovis.
Programs like Microsoft’s Excel make it simple to turn data into charts, but they provide few options. Powerful analytical programming languages can do more but are complicated to use. Protovis lets people who have only token programming skills concentrate on the design of a visualization rather than worrying about how to structure complex computer code. The software provides chunks of code that correspond to different aspects of visual information display, such as shapes and colors; users string these chunks together to create a complete graphic. People can also easily integrate the visualizations into Web pages to facilitate sharing and discussion. Protovis currently runs in Web browsers such as Firefox, Chrome, and Safari. Heer is working on tools that make it easier to create interactive and animated graphics.
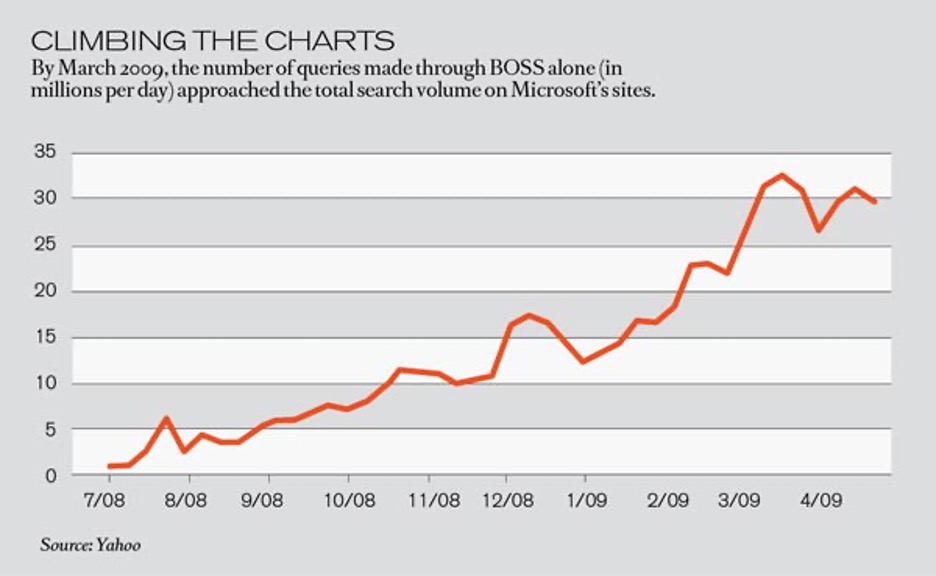
Vik Singh
Opening up search secrets to spur innovation.
Beginning in 2005, Web programmers were able to incorporate results from Yahoo’s search engine into their own services, but could do very little with those links: they were limited to 5,000 search queries per day, and they weren’t allowed to change how results were ranked or blend their own site’s content into the rankings. Then Vik Singh, only seven months out of college and five months into his first job, talked the company into giving away not just the search results but much of the data essential to its relevance formula, such as any tags that identify place names or people. His efforts led to the creation of BOSS (for “Build your Own Search Service”), an application programming interface that lets developers take Yahoo search results and manipulate them to provide services tailored to users’ needs, in some cases by considering personal data that a website has collected.
For instance, Singh says, typing jobs into Yahoo gives a user links to job-search websites such as Monster.com. But a social-networking site could use BOSS to design a search that considered a user’s hometown and current job, or even where his or her friends work.
More than 1,000 developers (of websites, e-mail clients, and mobile-phone applications) have begun using BOSS since its launch in July 2008. The Japanese company Spysee, for example, has built a search engine that finds connections between people, such as common interests or mutual friends, using data it gleans from Yahoo. Such new, smaller search services, Singh says, will create more competition for Yahoo’s main rivals, Google and Microsoft, in a market that’s otherwise hard to break into. With new services piggybacking on its platform, Yahoo figures it can glean a bigger share of search traffic. That, in turn, will yield data that will help it improve its core search engine. New sites may also mean new revenue for Yahoo, whether from small fees charged for every query or income shared from search-related advertising. Either way, Yahoo expects to improve its own standing by letting other software developers share its wealth of knowledge.