A Roomba recorded a woman on the toilet. How did screenshots end up on Facebook?
Robot vacuum companies say your images are safe, but a sprawling global supply chain for data from our devices creates risk.

In the fall of 2020, gig workers in Venezuela posted a series of images to online forums where they gathered to talk shop. The photos were mundane, if sometimes intimate, household scenes captured from low angles—including some you really wouldn’t want shared on the Internet.
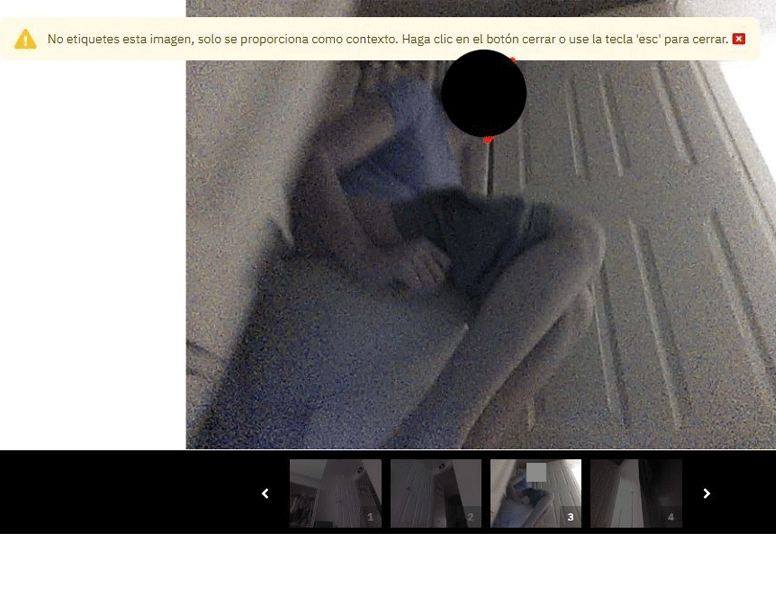
In one particularly revealing shot, a young woman in a lavender T-shirt sits on the toilet, her shorts pulled down to mid-thigh.
The images were not taken by a person, but by development versions of iRobot’s Roomba J7 series robot vacuum. They were then sent to Scale AI, a startup that contracts workers around the world to label audio, photo, and video data used to train artificial intelligence.
They were the sorts of scenes that internet-connected devices regularly capture and send back to the cloud—though usually with stricter storage and access controls. Yet earlier this year, MIT Technology Review obtained 15 screenshots of these private photos, which had been posted to closed social media groups.
The photos vary in type and in sensitivity. The most intimate image we saw was the series of video stills featuring the young woman on the toilet, her face blocked in the lead image but unobscured in the grainy scroll of shots below. In another image, a boy who appears to be eight or nine years old, and whose face is clearly visible, is sprawled on his stomach across a hallway floor. A triangular flop of hair spills across his forehead as he stares, with apparent amusement, at the object recording him from just below eye level.
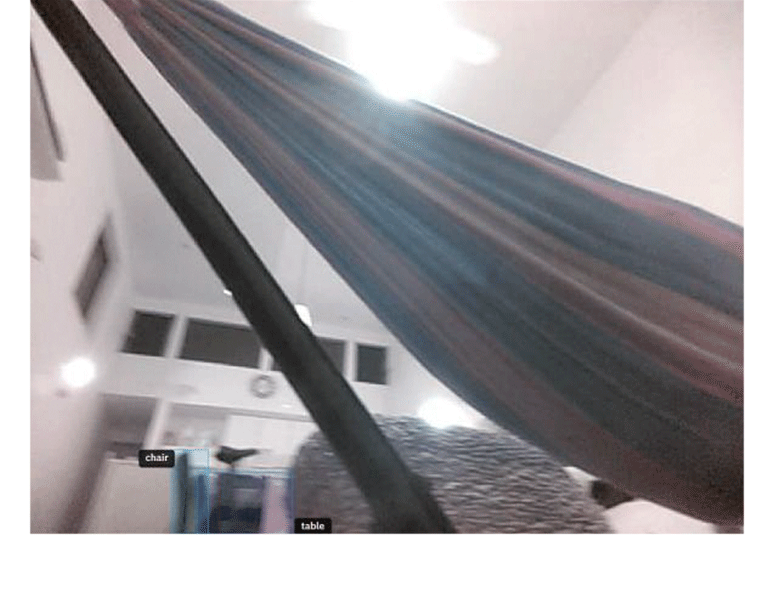
The other shots show rooms from homes around the world, some occupied by humans, one by a dog. Furniture, décor, and objects located high on the walls and ceilings are outlined by rectangular boxes and accompanied by labels like “tv,” “plant_or_flower,” and “ceiling light.”










iRobot—the world’s largest vendor of robotic vacuums, which Amazon recently acquired for $1.7 billion in a pending deal—confirmed that these images were captured by its Roombas in 2020. All of them came from “special development robots with hardware and software modifications that are not and never were present on iRobot consumer products for purchase,” the company said in a statement. They were given to “paid collectors and employees” who signed written agreements acknowledging that they were sending data streams, including video, back to the company for training purposes. According to iRobot, the devices were labeled with a bright green sticker that read “video recording in progress,” and it was up to those paid data collectors to “remove anything they deem sensitive from any space the robot operates in, including children.”
Did you participate in iRobot's data collection efforts? We'd love to hear from you. Please reach out at tips@technologyreview.com.
In other words, by iRobot’s estimation, anyone whose photos or video appeared in the streams had agreed to let their Roombas monitor them. iRobot declined to let MIT Technology Review view the consent agreements and did not make any of its paid collectors or employees available to discuss their understanding of the terms.
While the images shared with us did not come from iRobot customers, consumers regularly consent to having our data monitored to varying degrees on devices ranging from iPhones to washing machines. It’s a practice that has only grown more common over the past decade, as data-hungry artificial intelligence has been increasingly integrated into a whole new array of products and services. Much of this technology is based on machine learning, a technique that uses large troves of data—including our voices, faces, homes, and other personal information—to train algorithms to recognize patterns. The most useful data sets are the most realistic, making data sourced from real environments, like homes, especially valuable. Often, we opt in simply by using the product, as noted in privacy policies with vague language that gives companies broad discretion in how they disseminate and analyze consumer information.
The data collected by robot vacuums can be particularly invasive. They have “powerful hardware, powerful sensors,” says Dennis Giese, a PhD candidate at Northeastern University who studies the security vulnerabilities of Internet of Things devices, including robot vacuums. “And they can drive around in your home—and you have no way to control that.” This is especially true, he adds, of devices with advanced cameras and artificial intelligence—like iRobot’s Roomba J7 series.
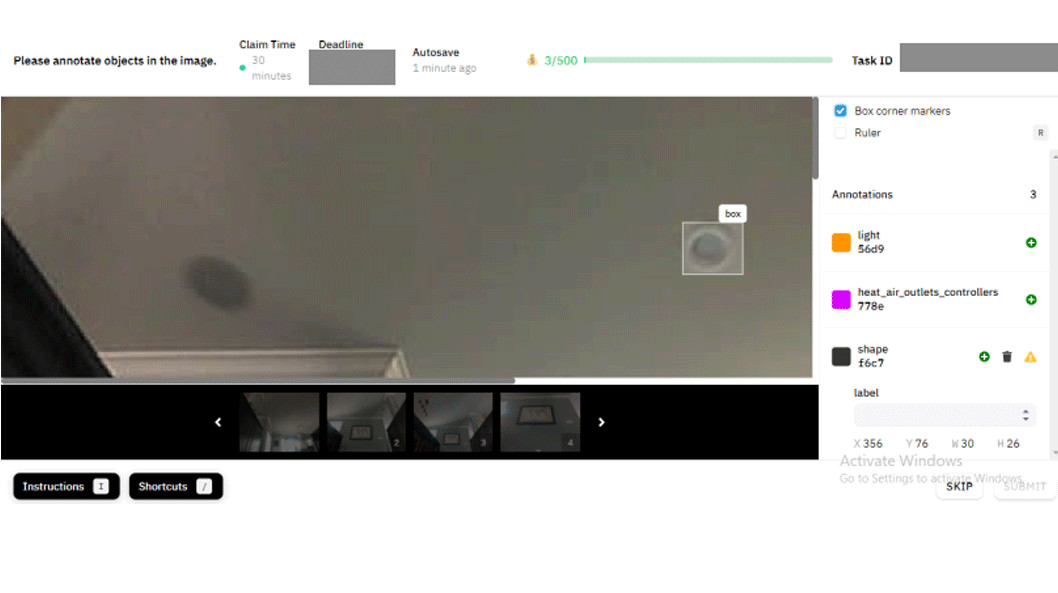
This data is then used to build smarter robots whose purpose may one day go far beyond vacuuming. But to make these data sets useful for machine learning, individual humans must first view, categorize, label, and otherwise add context to each bit of data. This process is called data annotation.
“There’s always a group of humans sitting somewhere—usually in a windowless room, just doing a bunch of point-and-click: ‘Yes, that is an object or not an object,’” explains Matt Beane, an assistant professor in the technology management program at the University of California, Santa Barbara, who studies the human work behind robotics.
The 15 images shared with MIT Technology Review are just a tiny slice of a sweeping data ecosystem. iRobot has said that it has shared over 2 million images with Scale AI and an unknown quantity more with other data annotation platforms; the company has confirmed that Scale is just one of the data annotators it has used.
James Baussmann, iRobot’s spokesperson, said in an email the company had “taken every precaution to ensure that personal data is processed securely and in accordance with applicable law,” and that the images shared with MIT Technology Review were “shared in violation of a written non-disclosure agreement between iRobot and an image annotation service provider.” In an emailed statement a few weeks after we shared the images with the company, iRobot CEO Colin Angle said that “iRobot is terminating its relationship with the service provider who leaked the images, is actively investigating the matter, and [is] taking measures to help prevent a similar leak by any service provider in the future.” The company did not respond to additional questions about what those measures were.
Ultimately, though, this set of images represents something bigger than any one individual company’s actions. They speak to the widespread, and growing, practice of sharing potentially sensitive data to train algorithms, as well as the surprising, globe-spanning journey that a single image can take—in this case, from homes in North America, Europe, and Asia to the servers of Massachusetts-based iRobot, from there to San Francisco–based Scale AI, and finally to Scale’s contracted data workers around the world (including, in this instance, Venezuelan gig workers who posted the images to private groups on Facebook, Discord, and elsewhere).
Together, the images reveal a whole data supply chain—and new points where personal information could leak out—that few consumers are even aware of.
“It’s not expected that human beings are going to be reviewing the raw footage,” emphasizes Justin Brookman, director of tech policy at Consumer Reports and former policy director of the Federal Trade Commission’s Office of Technology Research and Investigation. iRobot would not say whether data collectors were aware that humans, in particular, would be viewing these images, though the company said the consent form made clear that “service providers” would be.
“It’s not expected that human beings are going to be reviewing the raw footage.”
“We literally treat machines differently than we treat humans,” adds Jessica Vitak, an information scientist and professor at the University of Maryland’s communication department and its College of Information Studies. “It’s much easier for me to accept a cute little vacuum, you know, moving around my space [than] somebody walking around my house with a camera.”
And yet, that’s essentially what is happening. It’s not just a robot vacuum watching you on the toilet—a person may be looking too.
The robot vacuum revolution
Robot vacuums weren’t always so smart.
The earliest model, the Swedish-made Electrolux Trilobite, came to market in 2001. It used ultrasonic sensors to locate walls and plot cleaning patterns; additional bump sensors on its sides and cliff sensors at the bottom helped it avoid running into objects or falling off stairs. But these sensors were glitchy, leading the robot to miss certain areas or repeat others. The result was unfinished and unsatisfactory cleaning jobs.
The next year, iRobot released the first-generation Roomba, which relied on similar basic bump sensors and turn sensors. Much cheaper than its competitor, it became the first commercially successful robot vacuum.
The most basic models today still operate similarly, while midrange cleaners incorporate better sensors and other navigational techniques like simultaneous localization and mapping to find their place in a room and chart out better cleaning paths.
Higher-end devices have moved on to computer vision, a subset of artificial intelligence that approximates human sight by training algorithms to extract information from images and videos, and/or lidar, a laser-based sensing technique used by NASA and widely considered the most accurate—but most expensive—navigational technology on the market today.
Computer vision depends on high-definition cameras, and by our count, around a dozen companies have incorporated front-facing cameras into their robot vacuums for navigation and object recognition—as well as, increasingly, home monitoring. This includes the top three robot vacuum makers by market share: iRobot, which has 30% of the market and has sold over 40 million devices since 2002; Ecovacs, with about 15%; and Roborock, which has about another 15%, according to the market intelligence firm Strategy Analytics. It also includes familiar household appliance makers like Samsung, LG, and Dyson, among others. In all, some 23.4 million robot vacuums were sold in Europe and the Americas in 2021 alone, according to Strategy Analytics.
From the start, iRobot went all in on computer vision, and its first device with such capabilities, the Roomba 980, debuted in 2015. It was also the first of iRobot’s Wi-Fi-enabled devices, as well as its first that could map a home, adjust its cleaning strategy on the basis of room size, and identify basic obstacles to avoid.
Computer vision “allows the robot to … see the full richness of the world around it,” says Chris Jones, iRobot’s chief technology officer. It allows iRobot’s devices to “avoid cords on the floor or understand that that’s a couch.”
But for computer vision in robot vacuums to truly work as intended, manufacturers need to train it on high-quality, diverse data sets that reflect the huge range of what they might see. “The variety of the home environment is a very difficult task,” says Wu Erqi, the senior R&D director of Beijing-based Roborock. Road systems “are quite standard,” he says, so for makers of self-driving cars, “you’ll know how the lane looks … [and] how the traffic sign looks.” But each home interior is vastly different.
“The furniture is not standardized,” he adds. “You cannot expect what will be on your ground. Sometimes there’s a sock there, maybe some cables”—and the cables may look different in the US and China.

MIT Technology Review spoke with or sent questions to 12 companies selling robot vacuums and found that they respond to the challenge of gathering training data differently.
In iRobot’s case, over 95% of its image data set comes from real homes, whose residents are either iRobot employees or volunteers recruited by third-party data vendors (which iRobot declined to identify). People using development devices agree to allow iRobot to collect data, including video streams, as the devices are running, often in exchange for “incentives for participation,” according to a statement from iRobot. The company declined to specify what these incentives were, saying only that they varied “based on the length and complexity of the data collection.”
The remaining training data comes from what iRobot calls “staged data collection,” in which the company builds models that it then records.
iRobot has also begun offering regular consumers the opportunity to opt in to contributing training data through its app, where people can choose to send specific images of obstacles to company servers to improve its algorithms. iRobot says that if a customer participates in this “user-in-the-loop” training, as it is known, the company receives only these specific images, and no others. Baussmann, the company representative, said in an email that such images have not yet been used to train any algorithms.
In contrast to iRobot, Roborock said that it either “produce[s] [its] own images in [its] labs” or “work[s] with third-party vendors in China who are specifically asked to capture & provide images of objects on floors for our training purposes.” Meanwhile, Dyson, which sells two high-end robot vacuum models, said that it gathers data from two main sources: “home trialists within Dyson’s research & development department with a security clearance” and, increasingly, synthetic, or AI-generated, training data.
Most robot vacuum companies MIT Technology Review spoke with explicitly said they don’t use customer data to train their machine-learning algorithms. Samsung did not respond to questions about how it sources its data (though it wrote that it does not use Scale AI for data annotation), while Ecovacs calls the source of its training data “confidential.” LG and Bosch did not respond to requests for comment.
“You have to assume that people … ask each other for help. The policy always says that you’re not supposed to, but it’s very hard to control.”
Some clues about other methods of data collection come from Giese, the IoT hacker, whose office at Northeastern is piled high with robot vacuums that he has reverse-engineered, giving him access to their machine-learning models. Some are produced by Dreame, a relatively new Chinese company based in Shenzhen that sells affordable, feature-rich devices.
Giese found that Dreame vacuums have a folder labeled “AI server,” as well as image upload functions. Companies often say that “camera data is never sent to the cloud and whatever,” Giese says, but “when I had access to the device, I was basically able to prove that it's not true.” Even if they didn’t actually upload any photos, he adds, “[the function] is always there.”
Dreame manufactures robot vacuums that are also rebranded and sold by other companies—an indication that this practice could be employed by other brands as well, says Giese.
Dreame did not respond to emailed questions about the data collected from customer devices, but in the days following MIT Technology Review’s initial outreach, the company began changing its privacy policies, including those related to how it collects personal information, and pushing out multiple firmware updates.
But without either an explanation from companies themselves or a way, besides hacking, to test their assertions, it’s hard to know for sure what they’re collecting from customers for training purposes.
How and why our data ends up halfway around the world
With the raw data required for machine-learning algorithms comes the need for labor, and lots of it. That’s where data annotation comes in. A young but growing industry, data annotation is projected to reach $13.3 billion in market value by 2030.
The field took off largely to meet the huge need for labeled data to train the algorithms used in self-driving vehicles. Today, data labelers, who are often low-paid contract workers in the developing world, help power much of what we take for granted as “automated” online. They keep the worst of the Internet out of our social media feeds by manually categorizing and flagging posts, improve voice recognition software by transcribing low-quality audio, and help robot vacuums recognize objects in their environments by tagging photos and videos.
Among the myriad companies that have popped up over the past decade, Scale AI has become the market leader. Founded in 2016, it built a business model around contracting with remote workers in less-wealthy nations at cheap project- or task-based rates on Remotasks, its proprietary crowdsourcing platform.
In 2020, Scale posted a new assignment there: Project IO. It featured images captured from the ground and angled upwards at roughly 45 degrees, and showed the walls, ceilings, and floors of homes around the world, as well as whatever happened to be in or on them—including people, whose faces were clearly visible to the labelers.
Labelers discussed Project IO in Facebook, Discord, and other groups that they had set up to share advice on handling delayed payments, talk about the best-paying assignments, or request assistance in labeling tricky objects.
iRobot confirmed that the 15 images posted in these groups and subsequently sent to MIT Technology Review came from its devices, sharing a spreadsheet listing the specific dates they were made (between June and November 2020), the countries they came from (the United States, Japan, France, Germany, and Spain), and the serial numbers of the devices that produced the images, as well as a column indicating that a consent form had been signed by each device’s user. (Scale AI confirmed that 13 of the 15 images came from “an R&D project [it] worked on with iRobot over two years ago,” though it declined to clarify the origins of or offer additional information on the other two images.)
iRobot says that sharing images in social media groups violates Scale’s agreements with it, and Scale says that contract workers sharing these images breached their own agreements.
“The underlying problem is that your face is like a password you can’t change. Once somebody has recorded the ‘signature’ of your face, they can use it forever to find you in photos or video.”
But such actions are nearly impossible to police on crowdsourcing platforms.
When I ask Kevin Guo, the CEO of Hive, a Scale competitor that also depends on contract workers, if he is aware of data labelers sharing content on social media, he is blunt. “These are distributed workers,” he says. “You have to assume that people … ask each other for help. The policy always says that you’re not supposed to, but it’s very hard to control.”
That means that it’s up to the service provider to decide whether or not to take on certain work. For Hive, Guo says, “we don’t think we have the right controls in place given our workforce” to effectively protect sensitive data. Hive does not work with any robot vacuum companies, he adds.
“It’s sort of surprising to me that [the images] got shared on a crowdsourcing platform,” says Olga Russakovsky, the principal investigator at Princeton University’s Visual AI Lab and a cofounder of the group AI4All. Keeping the labeling in house, where “folks are under strict NDAs” and “on company computers,” would keep the data far more secure, she points out.
In other words, relying on far-flung data annotators is simply not a secure way to protect data. “When you have data that you’ve gotten from customers, it would normally reside in a database with access protection,” says Pete Warden, a leading computer vision researcher and a PhD student at Stanford University. But with machine-learning training, customer data is all combined “in a big batch,” widening the “circle of people” who get access to it.
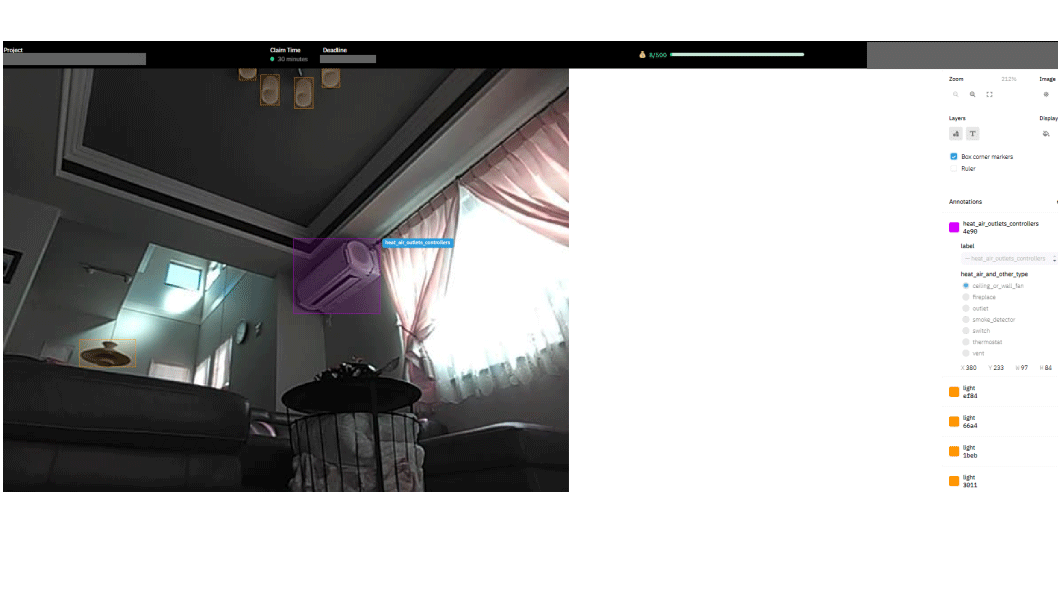
For its part, iRobot says that it shares only a subset of training images with data annotation partners, flags any image with sensitive information, and notifies the company’s chief privacy officer if sensitive information is detected. Baussmann calls this situation “rare,” and adds that when it does happen, “the entire video log, including the image, is deleted from iRobot servers.”
The company specified, “When an image is discovered where a user is in a compromising position, including nudity, partial nudity, or sexual interaction, it is deleted—in addition to ALL other images from that log.” It did not clarify whether this flagging would be done automatically by algorithm or manually by a person, or why that did not happen in the case of the woman on the toilet.
iRobot policy, however, does not deem faces sensitive, even if the people are minors.
“In order to teach the robots to avoid humans and images of humans”—a feature that it has promoted to privacy-wary customers—the company “first needs to teach the robot what a human is,” Baussmann explained. “In this sense, it is necessary to first collect data of humans to train a model.” The implication is that faces must be part of that data.
But facial images may not actually be necessary for algorithms to detect humans, according to William Beksi, a computer science professor who runs the Robotic Vision Laboratory at the University of Texas at Arlington: human detector models can recognize people based “just [on] the outline (silhouette) of a human.”
“If you were a big company, and you were concerned about privacy, you could preprocess these images,” Beksi says. For example, you could blur human faces before they even leave the device and “before giving them to someone to annotate.”
“It does seem to be a bit sloppy,” he concludes, “especially to have minors recorded in the videos.”
In the case of the woman on the toilet, a data labeler made an effort to preserve her privacy, by placing a black circle over her face. But in no other images featuring people were identities obscured, either by the data labelers themselves, by Scale AI, or by iRobot. That includes the image of the young boy sprawled on the floor.
Baussmann explained that iRobot protected “the identity of these humans” by “decoupling all identifying information from the images … so if an image is acquired by a bad actor, they cannot map backwards to identify the person in the image.”
But capturing faces is inherently privacy-violating, argues Warden. “The underlying problem is that your face is like a password you can’t change,” he says. “Once somebody has recorded the ‘signature’ of your face, they can use it forever to find you in photos or video.”

Additionally, “lawmakers and enforcers in privacy would view biometrics, including faces, as sensitive information,” says Jessica Rich, a privacy lawyer who served as director of the FTC’s Bureau of Consumer Protection between 2013 and 2017. This is especially the case if any minors are captured on camera, she adds: “Getting consent from the employee [or testers] isn’t the same as getting consent from the child. The employee doesn’t have the capacity to consent to data collection about other individuals—let alone the children that appear to be implicated.” Rich says she wasn’t referring to any specific company in these comments.
In the end, the real problem is arguably not that the data labelers shared the images on social media. Rather, it’s that this type of AI training set—specifically, one depicting faces—is far more common than most people understand, notes Milagros Miceli, a sociologist and computer scientist who has been interviewing distributed workers contracted by data annotation companies for years. Miceli was part of a research team that has spoken to multiple labelers who have seen similar images, taken from the same low vantage points and sometimes showing people in various stages of undress.
The data labelers found this work “really uncomfortable,” she adds.
Surprise: you may have agreed to this
Robot vacuum manufacturers themselves recognize the heightened privacy risks presented by on-device cameras. “When you’ve made the decision to invest in computer vision, you do have to be very careful with privacy and security,” says Jones, iRobot’s CTO. “You’re giving this benefit to the product and the consumer, but you also have to be treating privacy and security as a top-order priority.”
In fact, iRobot tells MIT Technology Review it has implemented many privacy- and security-protecting measures in its customer devices, including using encryption, regularly patching security vulnerabilities, limiting and monitoring internal employee access to information, and providing customers with detailed information on the data that it collects.
But there is a wide gap between the way companies talk about privacy and the way consumers understand it.
It’s easy, for instance, to conflate privacy with security, says Jen Caltrider, the lead researcher behind Mozilla’s “*Privacy Not Included” project, which reviews consumer devices for both privacy and security. Data security refers to a product’s physical and cyber security, or how vulnerable it is to a hack or intrusion, while data privacy is about transparency—knowing and being able to control the data that companies have, how it is used, why it is shared, whether and for how long it’s retained, and how much a company is collecting to start with.
Conflating the two is convenient, Caltrider adds, because “security has gotten better, while privacy has gotten way worse” since she began tracking products in 2017. “The devices and apps now collect so much more personal information,” she says.
Company representatives also sometimes use subtle differences, like the distinction between “sharing” data and selling it, that make how they handle privacy particularly hard for non-experts to parse. When a company says it will never sell your data, that doesn’t mean it won’t use it or share it with others for analysis.
These expansive definitions of data collection are often acceptable under companies’ vaguely worded privacy policies, virtually all of which contain some language permitting the use of data for the purposes of “improving products and services”—language that Rich calls so broad as to “permit basically anything.”
“Developers are not traditionally very good [at] security stuff.” Their attitude becomes “Try to get the functionality, and if the functionality is working, ship the product. And then the scandals come out.”
Indeed, MIT Technology Review reviewed 12 robot vacuum privacy policies, and all of them, including iRobot’s, contained similar language on “improving products and services.” Most of the companies to which MIT Technology Review reached out for comment did not respond to questions on whether “product improvement” would include machine-learning algorithms. But Roborock and iRobot say it would.
And because the United States lacks a comprehensive data privacy law—instead relying on a mishmash of state laws, most notably the California Consumer Privacy Act—these privacy policies are what shape companies’ legal responsibilities, says Brookman. “A lot of privacy policies will say, you know, we reserve the right to share your data with select partners or service providers,” he notes. That means consumers are likely agreeing to have their data shared with additional companies, whether they are familiar with them or not.
Brookman explains that the legal barriers companies must clear to collect data directly from consumers are fairly low. The FTC, or state attorneys general, may step in if there are either “unfair” or “deceptive” practices, he notes, but these are narrowly defined: unless a privacy policy specifically says “Hey, we’re not going to let contractors look at your data” and they share it anyway, Brookman says, companies are “probably okay on deception, which is the main way” for the FTC to “enforce privacy historically.” Proving that a practice is unfair, meanwhile, carries additional burdens—including proving harm. “The courts have never really ruled on it,” he adds.
Most companies’ privacy policies do not even mention the audiovisual data being captured, with a few exceptions. iRobot’s privacy policy notes that it collects audiovisual data only if an individual shares images via its mobile app. LG’s privacy policy for the camera- and AI-enabled Hom-Bot Turbo+ explains that its app collects audiovisual data, including “audio, electronic, visual, or similar information, such as profile photos, voice recordings, and video recordings.” And the privacy policy for Samsung’s Jet Bot AI+ Robot Vacuum with lidar and Powerbot R7070, both of which have cameras, will collect “information you store on your device, such as photos, contacts, text logs, touch interactions, settings, and calendar information” and “recordings of your voice when you use voice commands to control a Service or contact our Customer Service team.” Meanwhile, Roborock’s privacy policy makes no mention of audiovisual data, though company representatives tell MIT Technology Review that consumers in China have the option to share it.
iRobot cofounder Helen Greiner, who now runs a startup called Tertill that sells a garden-weeding robot, emphasizes that in collecting all this data, companies are not trying to violate their customers’ privacy. They’re just trying to build better products—or, in iRobot’s case, “make a better clean,” she says.
Still, even the best efforts of companies like iRobot clearly leave gaps in privacy protection. “It’s less like a maliciousness thing, but just incompetence,” says Giese, the IoT hacker. “Developers are not traditionally very good [at] security stuff.” Their attitude becomes “Try to get the functionality, and if the functionality is working, ship the product.”
“And then the scandals come out,” he adds.
Robot vacuums are just the beginning
The appetite for data will only increase in the years ahead. Vacuums are just a tiny subset of the connected devices that are proliferating across our lives, and the biggest names in robot vacuums—including iRobot, Samsung, Roborock, and Dyson—are vocal about ambitions much grander than automated floor cleaning. Robotics, including home robotics, has long been the real prize.
Consider how Mario Munich, then the senior vice president of technology at iRobot, explained the company’s goals back in 2018. In a presentation on the Roomba 980, the company’s first computer-vision vacuum, he showed images from the device’s vantage point—including one of a kitchen with a table, chairs, and stools—next to how they would be labeled and perceived by the robot’s algorithms. “The challenge is not with the vacuuming. The challenge is with the robot,” Munich explained. “We would like to know the environment so we can change the operation of the robot.”
This bigger mission is evident in what Scale’s data annotators were asked to label—not items on the floor that should be avoided (a feature that iRobot promotes), but items like “cabinet,” “kitchen countertop,” and “shelf,” which together help the Roomba J series device recognize the entire space in which it operates.
The companies making robot vacuums are already investing in other features and devices that will bring us closer to a robotics-enabled future. The latest Roombas can be voice controlled through Nest and Alexa, and they recognize over 80 different objects around the home. Meanwhile, Ecovacs’s Deebot X1 robot vacuum has integrated the company’s proprietary voice assistance, while Samsung is one of several companies developing “companion robots” to keep humans company. Miele, which sells the RX2 Scout Home Vision, has turned its focus toward other smart appliances, like its camera-enabled smart oven.
And if iRobot’s $1.7 billion acquisition by Amazon moves forward—pending approval by the FTC, which is considering the merger’s effect on competition in the smart-home marketplace—Roombas are likely to become even more integrated into Amazon’s vision for the always-on smart home of the future.
Perhaps unsurprisingly, public policy is starting to reflect the growing public concern with data privacy. From 2018 to 2022, there has been a marked increase in states considering and passing privacy protections, such as the California Consumer Privacy Act and the Illinois Biometric Information Privacy Act. At the federal level, the FTC is considering new rules to crack down on harmful commercial surveillance and lax data security practices—including those used in training data. In two cases, the FTC has taken action against the undisclosed use of customer data to train artificial intelligence, ultimately forcing the companies, Weight Watchers International and the photo app developer Everalbum, to delete both the data collected and the algorithms built from it.
Still, none of these piecemeal efforts address the growing data annotation market and its proliferation of companies based around the world or contracting with global gig workers, who operate with little oversight, often in countries with even fewer data protection laws.
When I spoke this summer to Greiner, she said that she personally was not worried about iRobot’s implications for privacy—though she understood why some people might feel differently. Ultimately, she framed privacy in terms of consumer choice: anyone with real concerns could simply not buy that device.
“Everybody needs to make their own privacy decisions,” she told me. “And I can tell you, overwhelmingly, people make the decision to have the features as long as they are delivered at a cost-effective price point.”
But not everyone agrees with this framework, in part because it is so challenging for consumers to make fully informed choices. Consent should be more than just “a piece of paper” to sign or a privacy policy to glance through, says Vitak, the University of Maryland information scientist.
True informed consent means “that the person fully understands the procedure, they fully understand the risks … how those risks will be mitigated, and … what their rights are,” she explains. But this rarely happens in a comprehensive way—especially when companies market adorable robot helpers promising clean floors at the click of a button.
Do you have more information about how companies collect data to train AI? Did you participate in data collection efforts by iRobot or other robot vacuum companies? We'd love to hear from you and will respect requests for anonymity. Please reach out at tips@technologyreview.com.
Additional research by Tammy Xu.
Correction: Electrolux is a Swedish company, not a Swiss company as originally written. Milagros Miceli was part of a research team that spoke to data labelers that had seen similar images from robot vacuums.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.