The world in a mug
Stored in DNA, all the world’s data could fit in a coffee cup. The trick is finding the file you need.
Humans generate millions of gigabytes of data each day, and one promising way to preserve it is to encode it in the nucleotides of DNA. After all, DNA evolved to store massive quantities of information at very high density, and it’s remarkably stable, too.
But once the files are stored—and scientists have already demonstrated that it’s possible—retrieving the one you’re looking for is a tall order. Now MIT researchers led by Mark Bathe, a professor of biological engineering, have demonstrated an easy way to do it.
The team encoded different images into DNA and encapsulated each file in a small silica particle labeled with single-stranded DNA “barcodes” corresponding to its contents. To pull out a specific image, they add primers to the DNA database that correspond to the labels they’re looking for—for example, “cat,” “orange,” and “wild” for an image of a tiger.
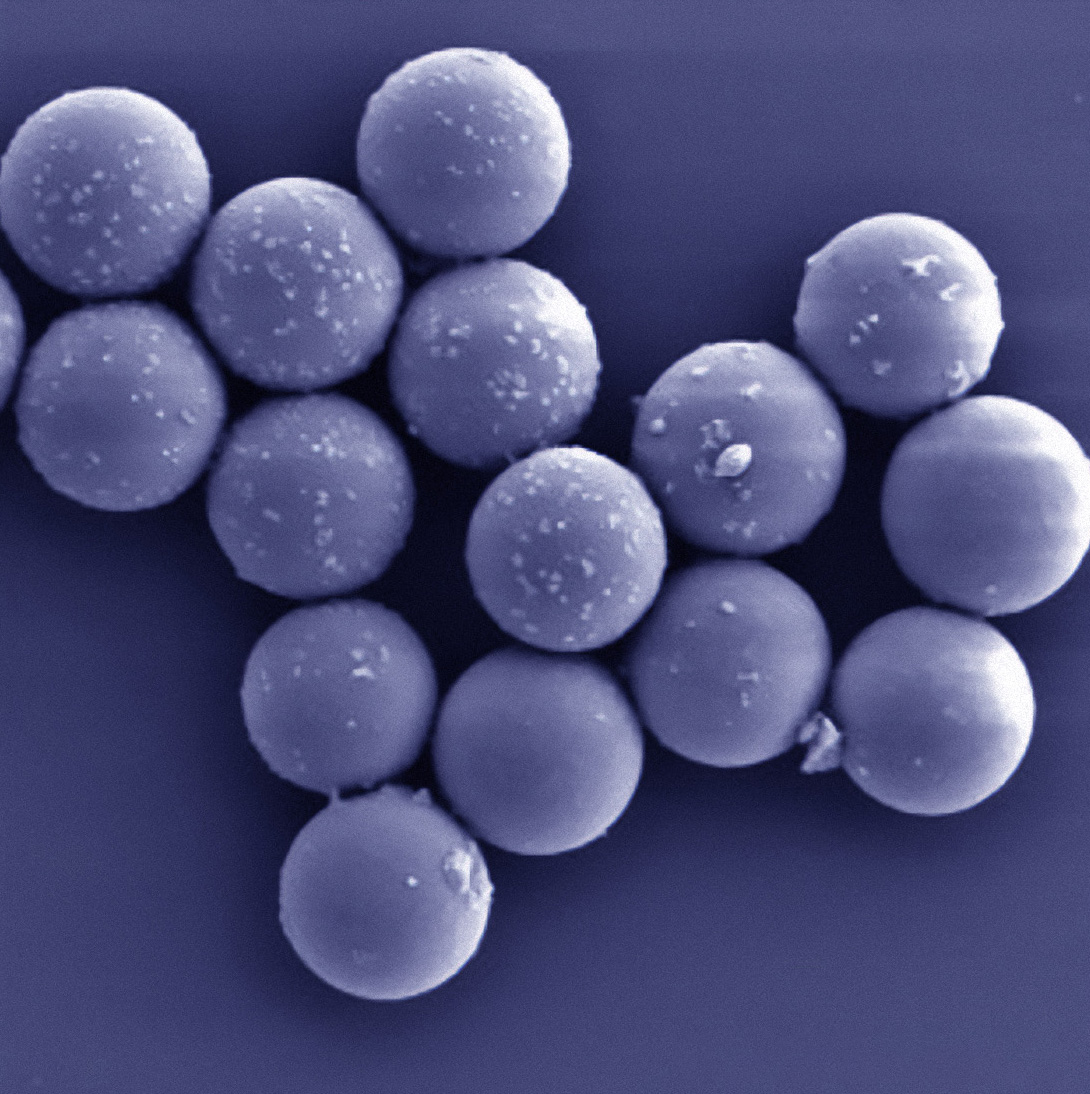
The primers are labeled with fluorescent or magnetic particles, making it easy to pull out any matches while leaving the rest of the DNA files intact. The process even allows Boolean logic statements, similar to what’s possible in a Google search.
Bathe envisions this as a way to deal with data that is not accessed very often. His lab is spinning out a startup, Cache DNA, that is developing technology for long-term storage of DNA.
“DNA is a thousandfold denser than even flash memory,” he says: all the data in the world could theoretically fit in a coffee mug. And, he adds, “once you make the DNA polymer, it doesn’t consume any energy. You can write the DNA and then store it forever.”
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.