A radical new technique lets AI learn with practically no data

Machine learning typically requires tons of examples. To get an AI model to recognize a horse, you need to show it thousands of images of horses. This is what makes the technology computationally expensive—and very different from human learning. A child often needs to see just a few examples of an object, or even only one, before being able to recognize it for life.
In fact, children sometimes don’t need any examples to identify something. Shown photos of a horse and a rhino, and told a unicorn is something in between, they can recognize the mythical creature in a picture book the first time they see it.

Now a new paper from the University of Waterloo in Ontario suggests that AI models should also be able to do this—a process the researchers call “less than one”-shot, or LO-shot, learning. In other words, an AI model should be able to accurately recognize more objects than the number of examples it was trained on. That could be a big deal for a field that has grown increasingly expensive and inaccessible as the data sets used become ever larger.
How “less than one”-shot learning works
The researchers first demonstrated this idea while experimenting with the popular computer-vision data set known as MNIST. MNIST, which contains 60,000 training images of handwritten digits from 0 to 9, is often used to test out new ideas in the field.
In a previous paper, MIT researchers had introduced a technique to “distill” giant data sets into tiny ones, and as a proof of concept, they had compressed MNIST down to only 10 images. The images weren’t selected from the original data set but carefully engineered and optimized to contain an equivalent amount of information to the full set. As a result, when trained exclusively on the 10 images, an AI model could achieve nearly the same accuracy as one trained on all MNIST’s images.


The Waterloo researchers wanted to take the distillation process further. If it’s possible to shrink 60,000 images down to 10, why not squeeze them into five? The trick, they realized, was to create images that blend multiple digits together and then feed them into an AI model with hybrid, or “soft,” labels. (Think back to a horse and rhino having partial features of a unicorn.)
“If you think about the digit 3, it kind of also looks like the digit 8 but nothing like the digit 7,” says Ilia Sucholutsky, a PhD student at Waterloo and lead author of the paper. “Soft labels try to capture these shared features. So instead of telling the machine, ‘This image is the digit 3,’ we say, ‘This image is 60% the digit 3, 30% the digit 8, and 10% the digit 0.’”
The limits of LO-shot learning
Once the researchers successfully used soft labels to achieve LO-shot learning on MNIST, they began to wonder how far this idea could actually go. Is there a limit to the number of categories you can teach an AI model to identify from a tiny number of examples?
Surprisingly, the answer seems to be no. With carefully engineered soft labels, even two examples could theoretically encode any number of categories. “With two points, you can separate a thousand classes or 10,000 classes or a million classes,” Sucholutsky says.
This is what the researchers demonstrate in their latest paper, through a purely mathematical exploration. They play out the concept with one of the simplest machine-learning algorithms, known as k-nearest neighbors (kNN), which classifies objects using a graphical approach.
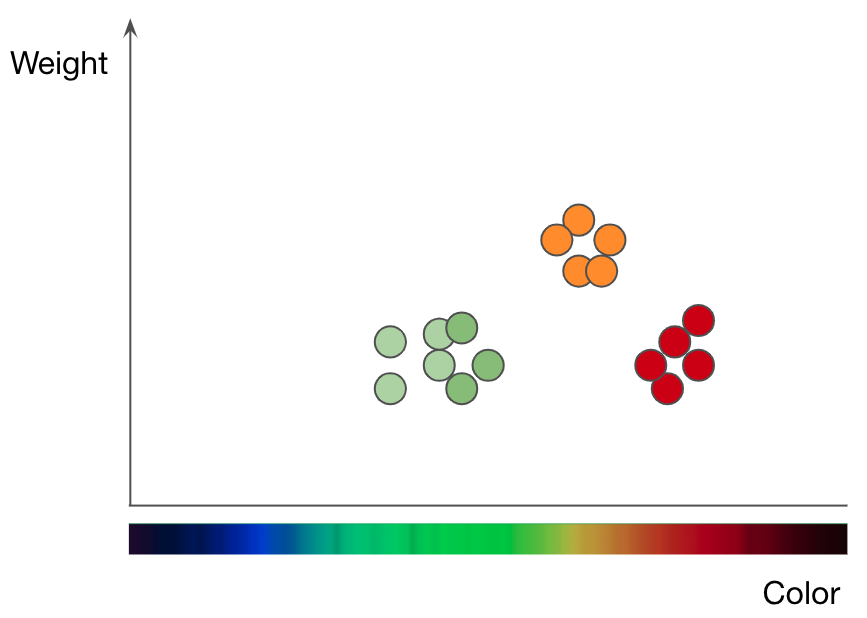
To understand how kNN works, take the task of classifying fruits as an example. If you want to train a kNN model to understand the difference between apples and oranges, you must first select the features you want to use to represent each fruit. Perhaps you choose color and weight, so for each apple and orange, you feed the kNN one data point with the fruit’s color as its x-value and weight as its y-value. The kNN algorithm then plots all the data points on a 2D chart and draws a boundary line straight down the middle between the apples and the oranges. At this point the plot is split neatly into two classes, and the algorithm can now decide whether new data points represent one or the other based on which side of the line they fall on.
To explore LO-shot learning with the kNN algorithm, the researchers created a series of tiny synthetic data sets and carefully engineered their soft labels. Then they let the kNN plot the boundary lines it was seeing and found it successfully split the plot up into more classes than data points. The researchers also had a high degree of control over where the boundary lines fell. Using various tweaks to the soft labels, they could get the kNN algorithm to draw precise patterns in the shape of flowers.
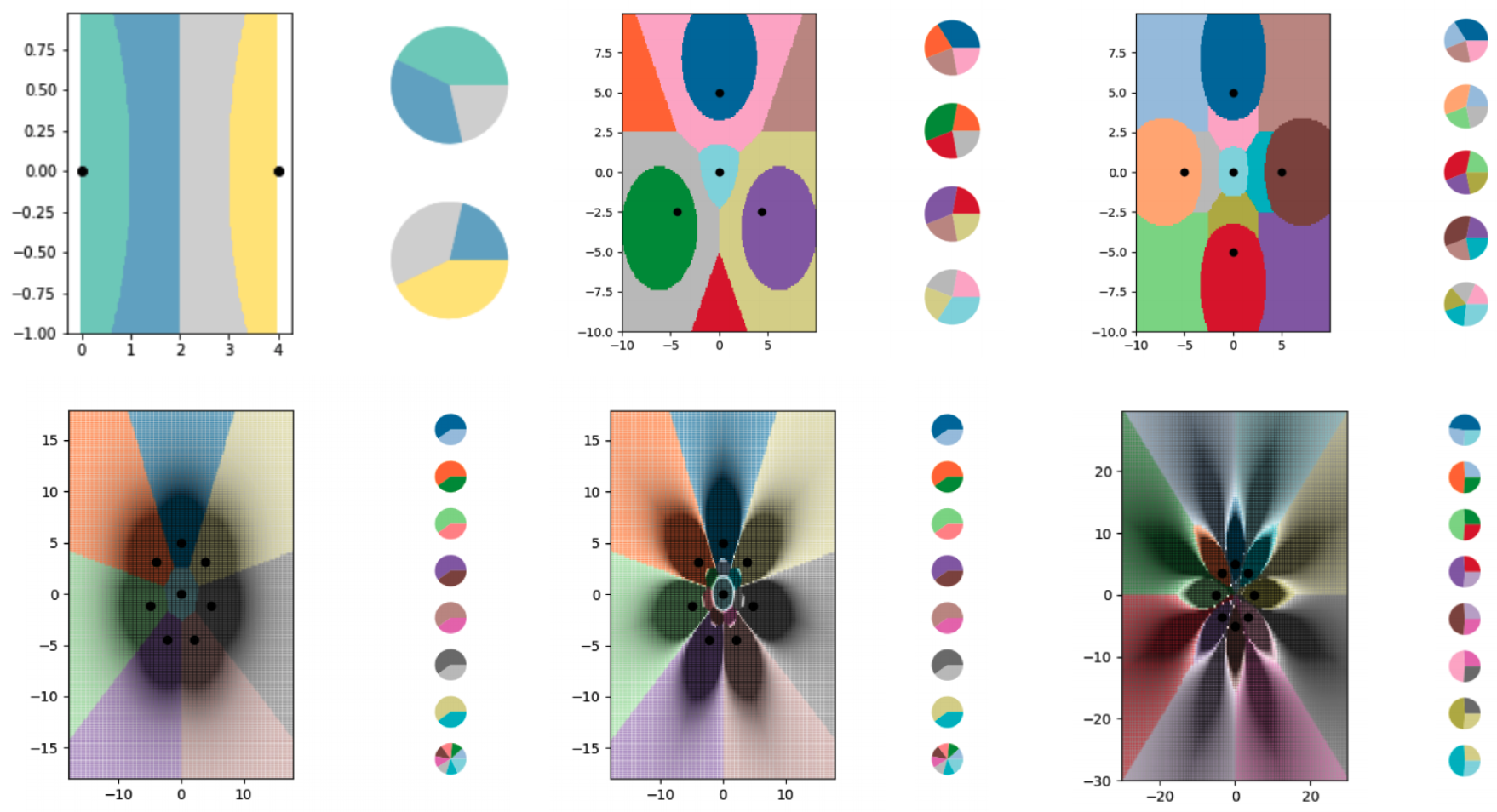
Of course, these theoretical explorations have some limits. While the idea of LO-shot learning should transfer to more complex algorithms, the task of engineering the soft-labeled examples grows substantially harder. The kNN algorithm is interpretable and visual, making it possible for humans to design the labels; neural networks are complicated and impenetrable, meaning the same may not be true. Data distillation, which works for designing soft-labeled examples for neural networks, also has a major disadvantage: it requires you to start with a giant data set in order to shrink it down to something more efficient.
Sucholutsky says he’s now working on figuring out other ways to engineer these tiny synthetic data sets—whether that means designing them by hand or with another algorithm. Despite these additional research challenges, however, the paper provides the theoretical foundations for LO-shot learning. “The conclusion is depending on what kind of data sets you have, you can probably get massive efficiency gains,” he says.
This is what most interests Tongzhou Wang, an MIT PhD student who led the earlier research on data distillation. “The paper builds upon a really novel and important goal: learning powerful models from small data sets,” he says of Sucholutsky’s contribution.
Ryan Khurana, a researcher at the Montreal AI Ethics Institute, echoes this sentiment: “Most significantly, ‘less than one’-shot learning would radically reduce data requirements for getting a functioning model built.” This could make AI more accessible to companies and industries that have thus far been hampered by the field’s data requirements. It could also improve data privacy, because less information would have to be extracted from individuals to train useful models.
Sucholutsky emphasizes that the research is still early, but he is excited. Every time he begins presenting his paper to fellow researchers, their initial reaction is to say that the idea is impossible, he says. When they suddenly realize it isn’t, it opens up a whole new world.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.