Facebook claims its new chatbot beats Google’s as the best in the world
For all the progress that chatbots and virtual assistants have made, they’re still terrible conversationalists. Most are highly task-oriented: you make a demand and they comply. Some are highly frustrating: they never seem to get what you’re looking for. Others are awfully boring: they lack the charm of a human companion. It’s fine when you’re only looking to set a timer. But as these bots become increasingly popular as interfaces for everything from retail to health care to financial services, the inadequacies only grow more apparent.
Now Facebook has open-sourced a new chatbot that it claims can talk about nearly anything in an engaging and interesting way. Blender could not only help virtual assistants resolve many of their shortcomings but also mark progress toward the greater ambition driving much of AI research: to replicate intelligence. “Dialogue is sort of an ‘AI complete’ problem,” says Stephen Roller, a research engineer at Facebook who co-led the project. “You would have to solve all of AI to solve dialogue, and if you solve dialogue, you’ve solved all of AI.”
Blender’s ability comes from the immense scale of its training data. It was first trained on 1.5 billion publicly available Reddit conversations, to give it a foundation for generating responses in a dialogue. It was then fine-tuned with additional data sets for each of three skills: conversations that contained some kind of emotion, to teach it empathy (if a user says “I got a promotion,” for example, it can say, “Congratulations!”); information-dense conversations with an expert, to teach it knowledge; and conversations between people with distinct personas, to teach it personality. The resultant model is 3.6 times larger than Google’s chatbot Meena, which was announced in January—so big that it can’t fit on a single device and must run across two computing chips instead.
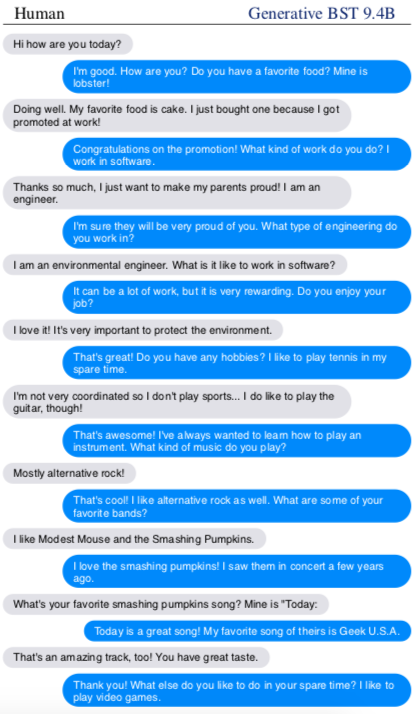
At the time, Google proclaimed that Meena was the best chatbot in the world. In Facebook’s own tests, however, 75% of human evaluators found Blender more engaging than Meena, and 67% found it to sound more like a human. The chatbot also fooled human evaluators 49% of the time into thinking that its conversation logs were more human than the conversation logs between real people—meaning there wasn’t much of a qualitative difference between the two. Google hadn’t responded to a request for comment by the time this story was due to be published.
Despite these impressive results, however, Blender’s skills are still nowhere near those of a human. Thus far, the team has evaluated the chatbot only on short conversations with 14 turns. If it kept chatting longer, the researchers suspect, it would soon stop making sense. “These models aren’t able to go super in-depth,” says Emily Dinan, the other project leader. “They’re not able to remember conversational history beyond a few turns.”
Blender also has a tendency to “hallucinate” knowledge, or make up facts—a direct limitation of the deep-learning techniques used to build it. It’s ultimately generating its sentences from statistical correlations rather than a database of knowledge. As a result, it can string together a detailed and coherent description of a famous celebrity, for example, but with completely false information. The team plans to experiment with integrating a knowledge database into the chatbot’s response generation.

Another major challenge with any open-ended chatbot system is to prevent it from saying toxic or biased things. Because such systems are ultimately trained on social media, they can end up regurgitating the vitriol of the internet. (This infamously happened to Microsoft’s chatbot Tay in 2016.) The team tried to address this issue by asking crowdworkers to filter out harmful language from the three data sets that it used for fine-tuning, but it did not do the same for the Reddit data set because of its size. (Anyone who has spent much time on Reddit will know why that could be problematic.)
The team hopes to experiment with better safety mechanisms, including a toxic-language classifier that could double-check the chatbot’s response. The researchers admit, however, that this approach won’t be comprehensive. Sometimes a sentence like “Yes, that’s great” can seem fine, but within a sensitive context, such as in response to a racist comment, it can take on harmful meanings.
In the long term the Facebook AI team is also interested in developing more sophisticated conversational agents that can respond to visual cues as well as just words. One project is developing a system called Image Chat, for example, that can converse sensibly and with personality about the photos a user might send.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.