Sponsored
The global AI agenda: Promise, reality, and a future of data sharing
In association withGenesys, Philips
"The global AI agenda: Promise, reality, and a future of data sharing" is an MIT Technology Review Insights report produced in partnership with Genesys and Philips. It was developed through a global survey conducted in January and February 2020 of over 1,000 executives across 11 different sectors and a series of interviews with experts having specific responsibility for or knowledge of AI. The article below is an extract of the full report.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.

Few emerging fields of technology have generated as much excitement and debate in recent years as AI. Most of the excitement thus far has centered around the technology industry, which in the US, China, and, to some extent, Europe has been investing billions in developing its AI capabilities. Organizations in other sectors may not be spending on AI with the same abandon, but the survey suggests that most are at least testing the waters.
By the end of 2020, 97% of the large companies surveyed for this report will be deploying AI. The earliest adopters have been IT and telecoms firms, with 81% using AI by 2018—just ahead of financial services firms (78%) and consumer goods and retail (75%). The public sector is also finding numerous use cases for AI: by the end of 2019, 94% of government respondents said they had deployed AI.
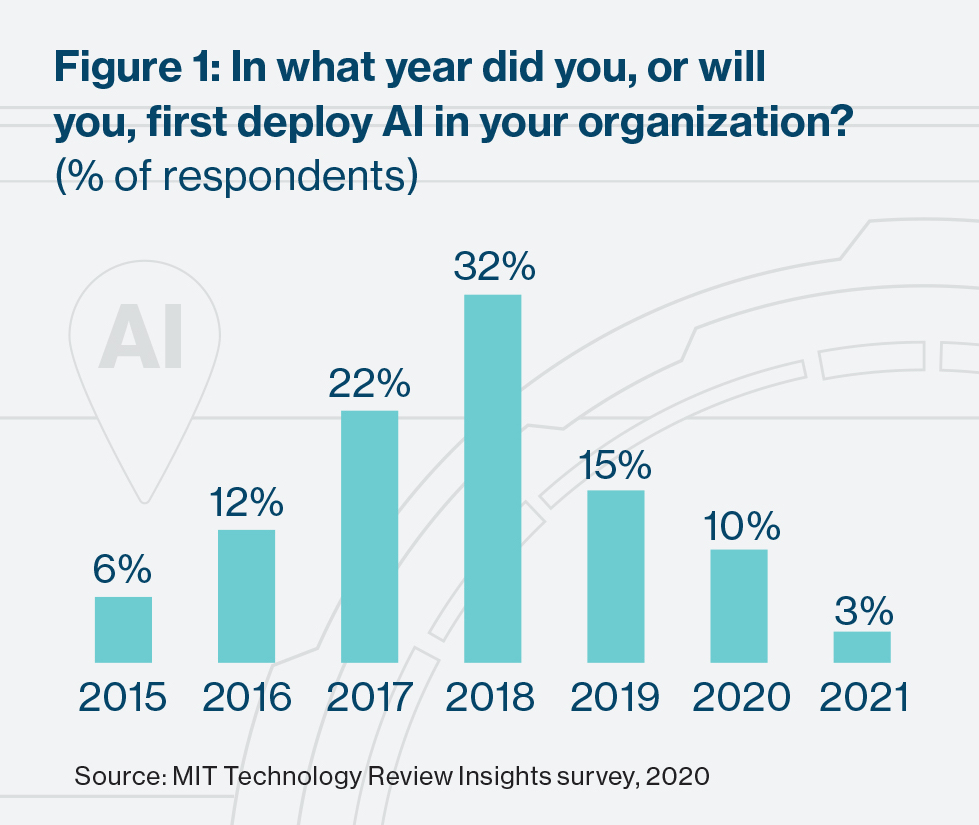
AI will naturally play different roles in different types of businesses. For some, its capabilities will help to improve aspects of operational efficiency. Others expect it to be game changing. “For us,” says Jeroen Tas, chief innovation and strategy officer at consumer and health-care equipment provider Philips, “AI is a foundational technology that in the next couple of years will be found in the vast majority of our propositions.” And for some companies born in the online environment, the success of the business model rests on it. One is Lemonade, a New York-based online provider of property and casualty insurance that is described as a “disrupter” of the established insurance industry. Its chief executive Daniel Schreiber believes AI-powered bots such as Lemonade’s are “the future of insurance.”
One step at a time
Deployed widely though it is, AI is not about to conquer the enterprise. Very few surveyed executives (4%) believe it will be used in more than half of their business processes in three years’ time. Less than one-third (30%) expect it to be used in between 31% and 50% of processes. The majority, 60% of respondents, believe AI will find a place in anywhere from 11% to 30% of their processes—a considerable but not necessarily dominant influence on how most businesses operate. On this measure, AI will play an especially large role in the operations of financial services providers, manufacturers, and technology firms.
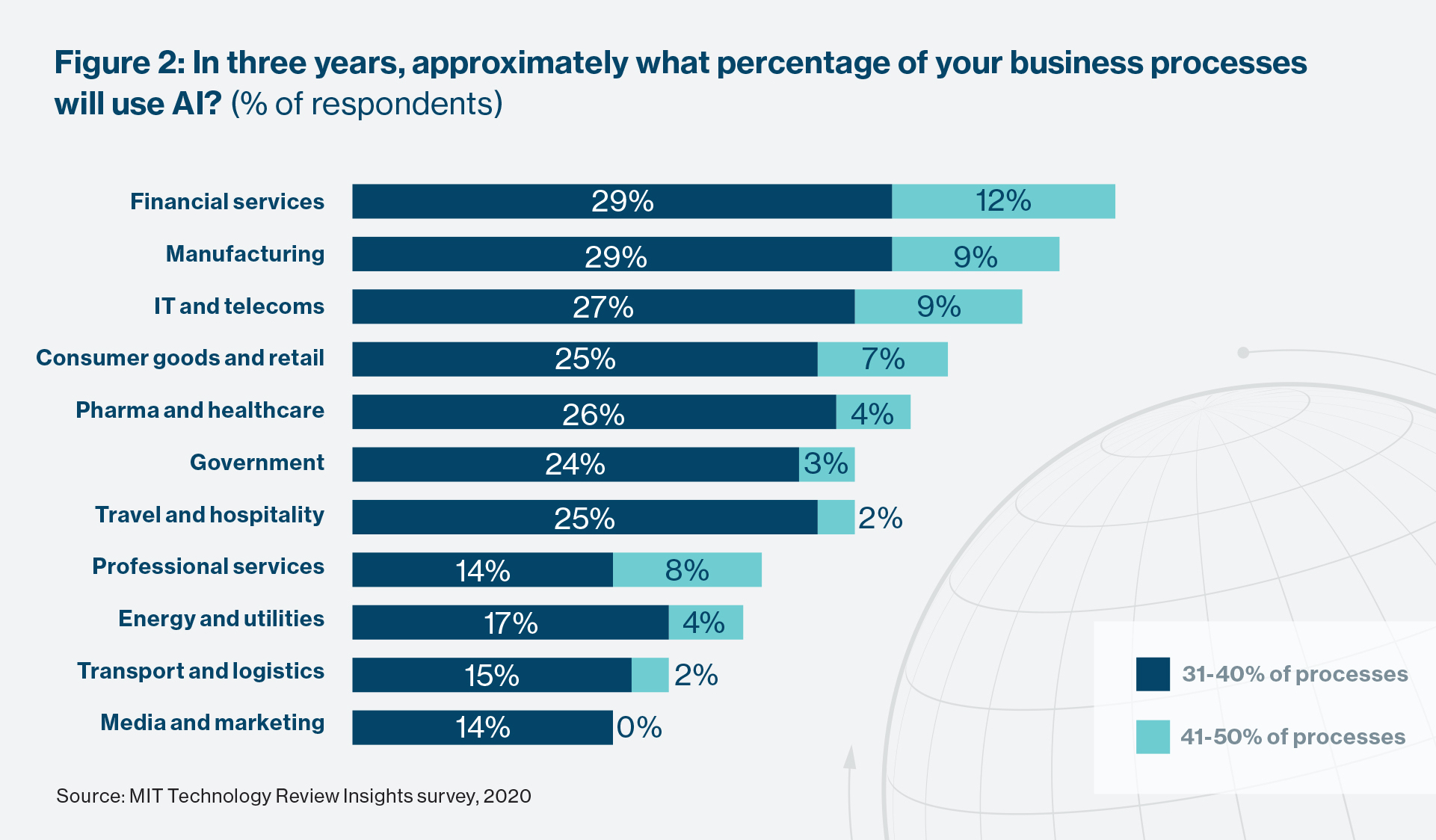
Unsure of its actual (as opposed to assumed) capabilities, and cognizant of the challenges it poses, businesses have been taking an iterative approach to AI’s deployment. According to Dirk Jungnickel, senior vice president, Enterprise Analytics, at Emirates Group, early attempts taken by his company in 2015 and 2016 to build AI capabilities often did not make it beyond the proof-of-concept or pilot stage. That began to change in mid-2018 when, he says, the firm began to “operationalize” its AI development efforts and “industrialize data science.”
Céline Le Cotonnec, chief data innovation officer at Bank of Singapore, notes that many corporate organizations want to deliver AI use cases before having first set the right foundations in terms of IT architecture, AI capabilities, target operating model, or data governance. “My response is ‘first things first,’” she says. “We need to set up the right foundation for data before moving ahead.” This includes having “analytics translators”—people who understand AI as well as the business to scope projects, manage the delivery, measure return on investment, and understand how feasible it will be to scale up.
For large companies setting aside substantial budgets to develop AI capabilities, developing and prioritizing use cases is a considerable challenge. According to Mike Hanrahan, CEO of Walmart’s Intelligent Research Lab (IRL): “The first thing we had to invest time in was deciding where we should focus our resources.” His team identified over 250 different use cases and then filtered them down to a handful. “The filtering process was pretty complex in deciding what we should work on,” says Hanrahan. “It came down to deciding which cases were the most practical to scale.”
For Walmart, the priority cases related to management of inventory, which represents a large chunk of the multinational’s cost base, and where even small improvements in efficiency generate significant savings. Across sectors, however, businesses are pursuing a variety of use cases, in the hope that at least a couple will generate early returns and serve to build confidence and excitement in AI throughout in the organization.
Use cases today and tomorrow
Among the survey sample as a whole, quality control, customer care, and fraud detection are currently the top AI use cases. A more detailed view, however, reveals considerable variety in the main use cases pursued by different sectors. For example, over half of financial services firms (58%) and government organizations (55%) cite fraud detection as their top AI use case. Céline Le Cotonnec says that in her previous role at a global insurance firm, fraud detection use cases were the first that were implemented, since the benefit promised to be sizeable: According to a Reinsurance Group of America (RGA) survey from 2017, 3-4% of all global claims are fraudulent, with the highest incidence (4.16%) in Asia.
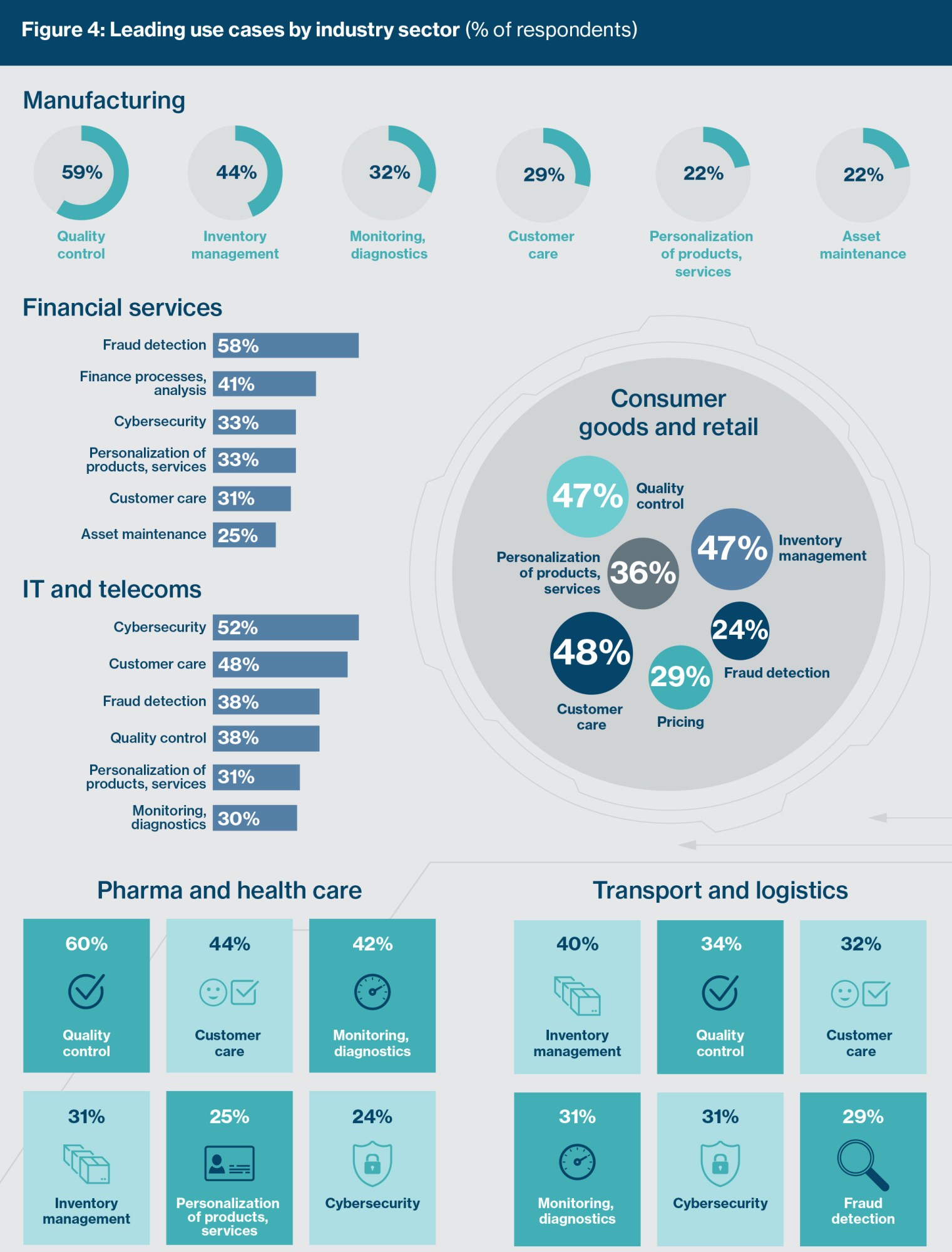
For mobile operator Vodafone, the most successful use cases are found in customer service, according to Adi Chhabra, head of product innovation at Vodafone UK. The benefits, he says, accrue both to cost efficiency and to the customer experience. “In the telecoms industry, customer service eats up a lot of costs. Integrating AI with IVR (interactive voice response) almost instantly removes cost from these operations and it leads to faster decisions being taken to address customer issues.”
Energy firms and utilities, according to 51% of respondents from that sector, use AI to monitor the state of their networks. Monitoring and diagnosis are also a natural AI focus for organizations in the health-care industry, and 42% of respondents from these organizations are pursuing such uses. According to Tas at Philips, AI has completely changed the way the industry diagnoses cancer, and its capabilities now extend further, to selecting treatments: “Once diagnosed, AI algorithms now help us to select the right therapy. That’s complex because the options could include surgery, ablation, chemotherapy, immunotherapy, or radiation, or a combination of these. Selecting the right therapies and pathways is becoming an insights-driven, AI-enabled exercise.”
The challenges of scaling
It is clear from the executives interviewed for this report that scaling AI use cases is proving difficult. Existing technology limitations can hinder wider adoption, suggests Hanrahan in the case of real-time video analysis. When it comes to forms of personal AI, advances need to be made in natural language processing before chatbots, for example, become truly sophisticated, says Chhabra.
In some industries, regulation hinders the wider application of AI-enabled innovations. A case in point is algorithm-based insurance pricing in the United States. According to Lemonade’s Daniel Schreiber, this is currently allowed in only a handful of US states. “In the US, the world’s largest insurance market, the regulatory environment has not yet made allowances for these next-gen technologies,” he says.
Shortages of AI-related talent and skills are a frequent lament of CIOs and CTOs, and 42% of the respondents to our survey say a shortage of internal data scientists and related experts is a major constraint on their use of AI. The deficit is felt keenly among manufacturing and technology industry respondents, cited as an AI constraint by 48% and 47% of them, respectively.
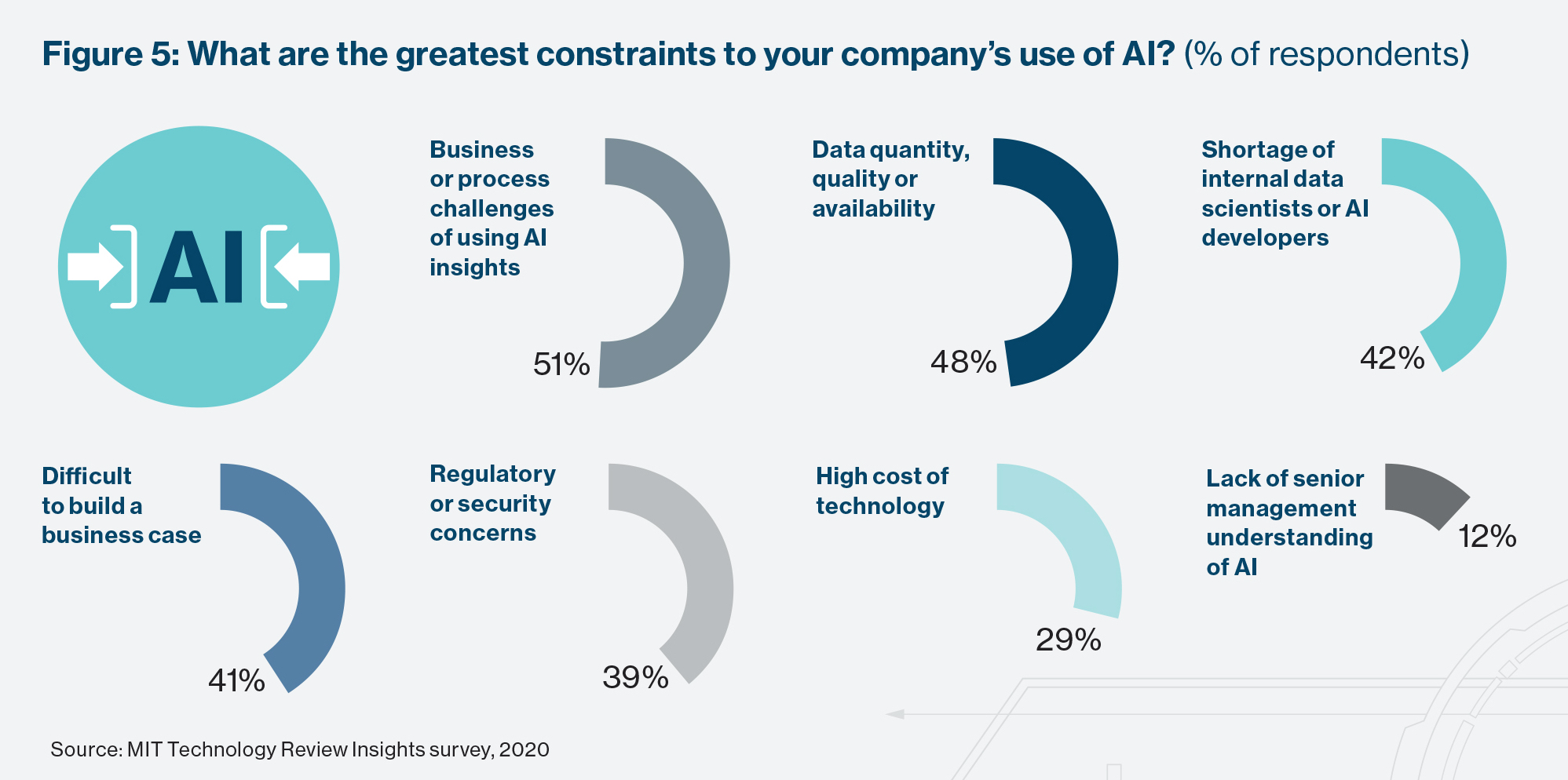
Data, indeed, is another major constraint, ranked a close second to process issues by the survey respondents (cited by 48% of them). AI models need data: the more a model ingests, the more accurate its analysis and the more likely that the decisions it prompts will hit the mark. The problem is less with the overall availability of data, however. Just 10% of respondents say they struggle with this. Difficulties integrating data in different formats, especially unstructured data, are the bigger problem, according to Le Cotonnec. Insurers should start to leverage on their unstructured data (call logs, pictures, e-mail), she says, in order to improve claims process efficiency or enhance customer experience. “We have enough data, but our ability to extract value from unstructured data is limited at the moment.” The insurance industry is not alone: it is an issue experienced by 57% of the firms in the survey (and by considerably more professional services, transport, and government organizations).
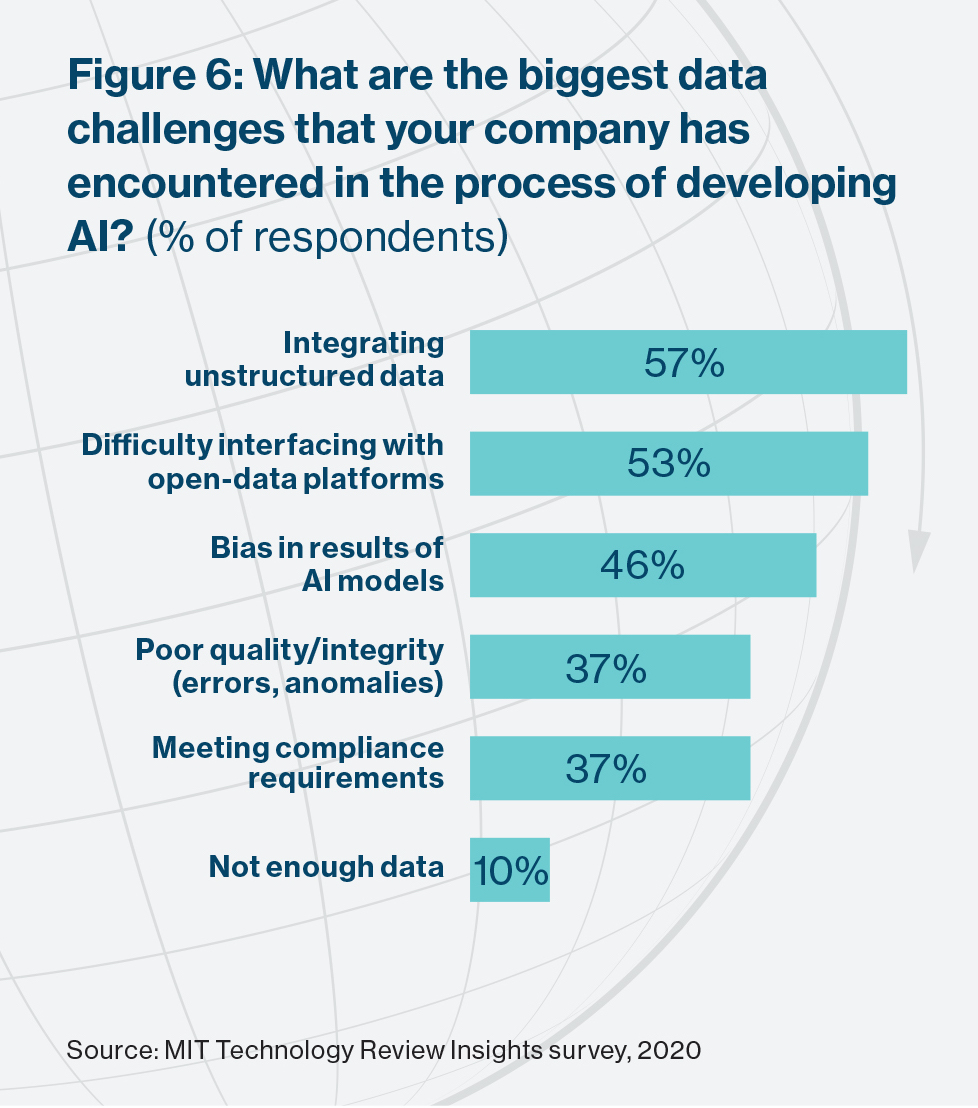
Unlocking opportunities for data sharing
In June 2019, 10 large pharmaceutical producers formed a consortium for the express purpose of sharing drug research data that each can use to train their AI algorithms. It is not the first time that drug majors have engaged in R&D collaboration. But it is the first instance in this industry of research collaboration in which AI is both enabler and beneficiary. Consortium members trawl each other’s data using “federated learning” techniques, which are a decentralized form of machine learning. This allows the data being searched to remain in each company’s servers rather than being pooled in a central repository. The companies can safeguard what they consider proprietary, while the use of blockchain ensures full traceability of the data. The ultimate objective: simplifying and accelerating drug discovery and development, resulting in new and less- costly drugs and treatments reaching the market.
This example highlights how the use of AI, in combination with other technologies, can facilitate efficient and secure data sharing between companies, and the benefits that could result from powerful AI models built on shared data. The benefits could take the form of new efficiencies, new products and services, or even new value chains that form around data-sharing arrangements.
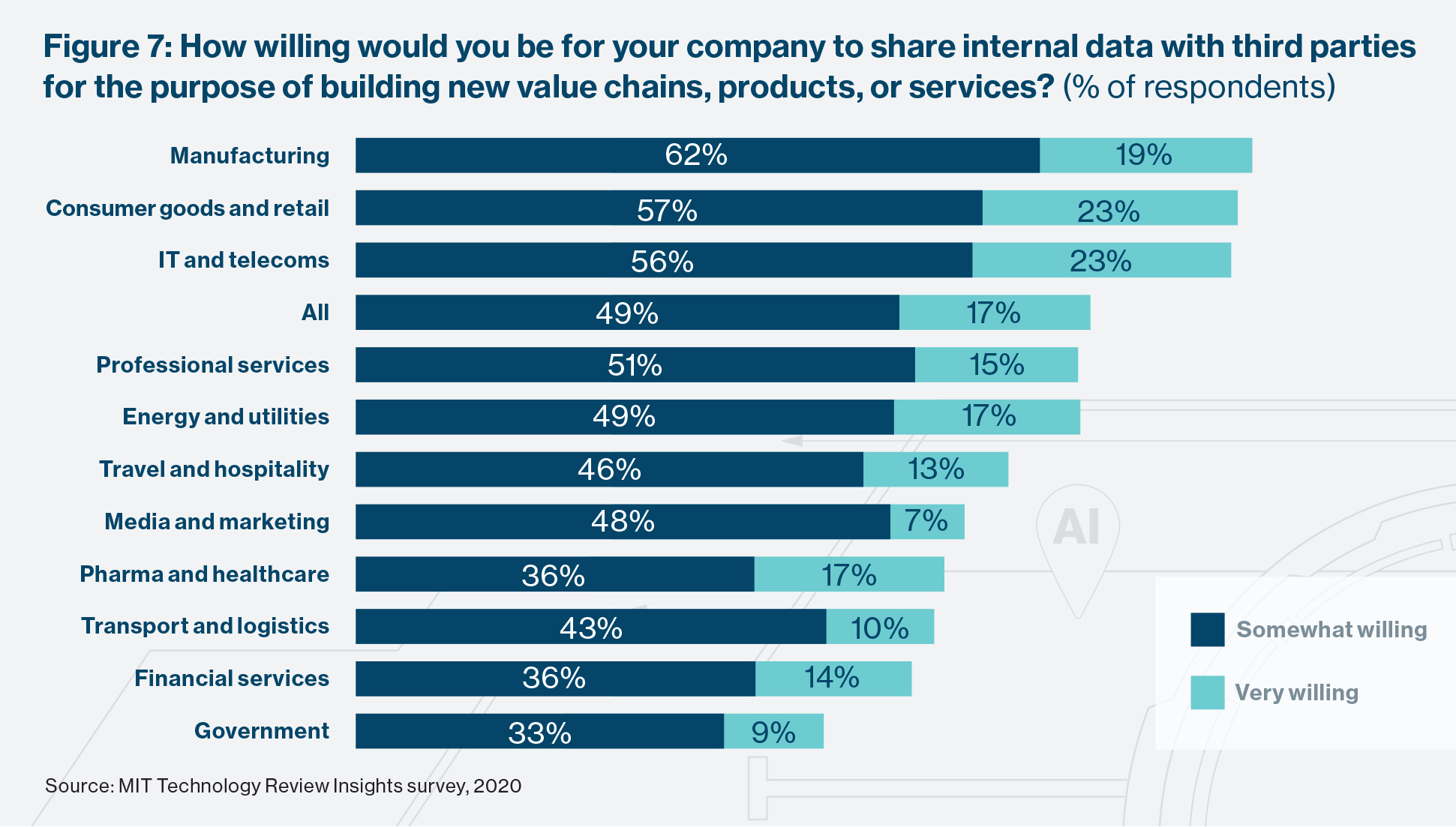
Two-thirds (66%) of our survey respondents express a willingness to share their own data for these purposes. Manufacturers, consumer goods and retail firms, and technology companies are the most enthusiastic, although all sectors exhibit a large degree of readiness. How are they looking to gain from it? Manufacturers see their chief wins in the forms of greater supply chain speed and visibility, more efficient production operations, and faster and more innovative product development. Respondents from the consumer goods and retail and pharma and health-care sectors cite the same supply chain and product development gains. IT and telecoms executives see the benefits chiefly in enhanced customer service experiences and stronger cybersecurity and fraud prevention, the same benefits as are top-of-mind for financial industry respondents.
Sharing data across value chains and between different providers in a customer journey can be a huge benefit to consumers, says Tony Bates at Genesys. “We generate billions of interactions that we can build common data models around. But we also need other forms of data. There is a need to share data across the different large technology stacks that we use and manage. If we can do this in an anonymized and secure way, we as an industry can ensure that our customers get much more personalized experiences than they are getting now.”
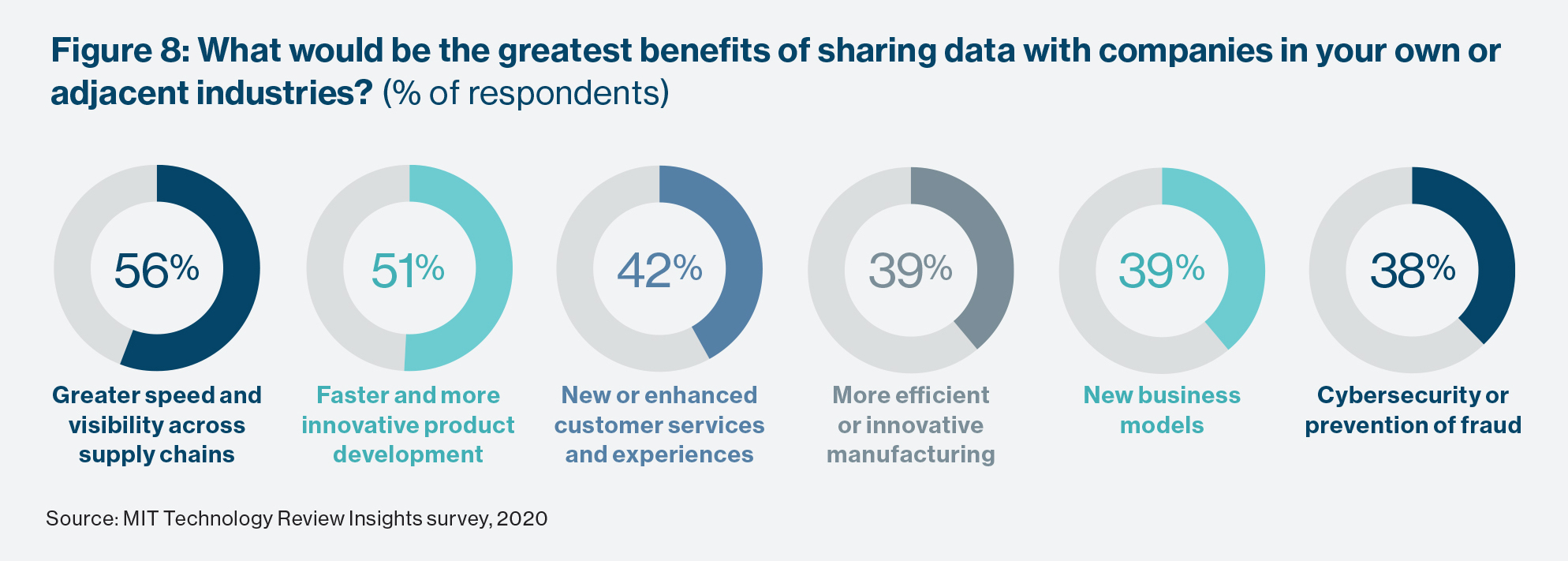
For business-to-consumer companies in particular, the chief hindrance to date has been the difficulty of ensuring anonymity of their customers’ data. Chhabra at Vodafone says that complete anonymity has been elusive: “As much as you want to anonymize, users of shared data can find ways to track the customers the data refers to.” He believes that blockchain and newer developments such as Ocean Protocol, which works similarly to federated learning in allowing the decentralized searching of data, will eventually ensure that AI models can be run on fully anonymized data.
Creating the ability to share data securely is one piece of the puzzle. The other, says Chhabra, is creating an incentive for companies to go ahead and share it. Those behind Ocean Protocol, a nonprofit platform developed by a Singapore- based foundation, see its technology underpinning the formation of “data marketplaces” in which companies, consumers, and other parties share or trade data.
In whatever forms of sharing companies take part, they must learn how to value the data they hold and the data they need, says George Bailey, managing director of the Digital Supply Chain Institute, a research organization. It may mean assigning a monetary price to different types of data, or identifying what data it is willing to exchange in return for that of other parties. He cites the examples of sporting goods producers that see a benefit in obtaining data from companies that support fitness apps, and consumer durables producers seeking data on end-user preferences and characteristics from retailers. Bailey also advocates data valuation and trading within companies as a means of overcoming entrenched data siloes.
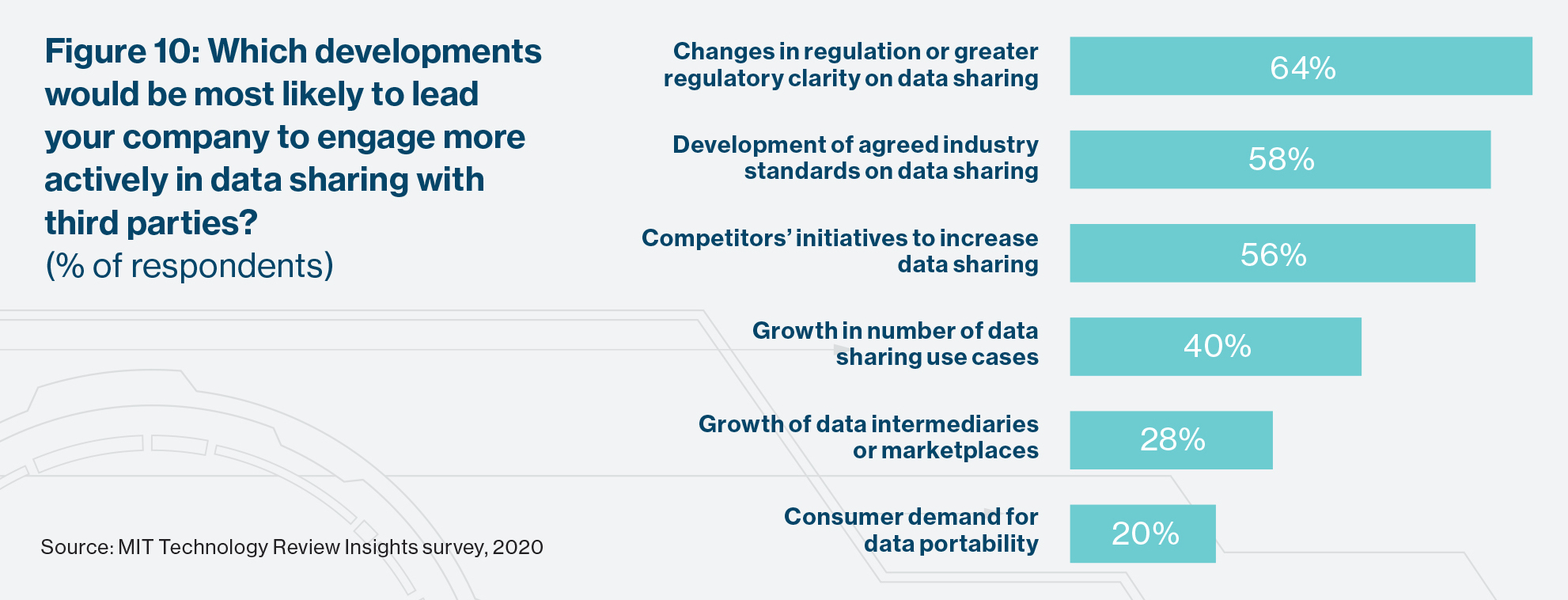
From vision to reality
Data sharing on a scale that leads to new AI-enabled efficiencies, products, and value chains is a vision to be realized rather than a current reality. All those we interviewed believe it will come to pass, but that it will take time before board and C-suite misgivings about the security and privacy risks of doing so are eased. That view is reflected in the survey, where 64% of respondents say that regulation needs to change or be clarified, and 58% that industry standards need to be developed, before their firms will embrace data sharing widely.
Stringent data privacy regulations, such as the European Union’s General Data Protection Regulation (GDPR), in force since 2018, understandably give executives pause in light of the penalties they could face for failure to meet its requirements. Blockchain technology may be part of the solution, but Chhabra also highlights what is known as the “GDPR-blockchain paradox”—the former requires the ability of data erasure at an individual’s request, while non-erasure—full traceability—is inherent in the latter.
How such issues are resolved remains to be seen, but some organizations advocate the establishment of data trusts to facilitate sharing. One is the Open Data Institute (ODI), a UK-based nonprofit organization: it maintains that there is a strong appetite among UK businesses for such trusts set up as independent institutions to act as stewards of the data being shared.
Philips, says Jeroen Tas, is a big proponent of creating a non-commercial trust to manage health-care data, and is in talks with the European Commission to support such initiatives. “There is a consensus in this industry that says, ‘Maybe we shouldn’t just be investing in brick-and-mortar hospitals and other facilities. Maybe the future of health care is a very solid health-data infrastructure that’s secure.”
For more, please download the full report.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.