Why asking an AI to explain itself can make things worse

Upol Ehsan once took a test ride in an Uber self-driving car. Instead of fretting about the empty driver’s seat, anxious passengers were encouraged to watch a “pacifier” screen that showed a car’s-eye view of the road: hazards picked out in orange and red, safe zones in cool blue.
For Ehsan, who studies the way humans interact with AI at the Georgia Institute of Technology in Atlanta, the intended message was clear: “Don’t get freaked out—this is why the car is doing what it’s doing.” But something about the alien-looking street scene highlighted the strangeness of the experience rather than reassured. It got Ehsan thinking: what if the self-driving car could really explain itself?
The success of deep learning is due to tinkering: the best neural networks are tweaked and adapted to make better ones, and practical results have outpaced theoretical understanding. As a result, the details of how a trained model works are typically unknown. We have come to think of them as black boxes.
A lot of the time we’re okay with that when it comes to things like playing Go or translating text or picking the next Netflix show to binge on. But if AI is to be used to help make decisions in law enforcement, medical diagnosis, and driverless cars, then we need to understand how it reaches those decisions—and know when they are wrong.
People need the power to disagree with or reject an automated decision, says Iris Howley, a computer scientist at Williams College in Williamstown, Massachusetts. Without this, people will push back against the technology. “You can see this playing out right now with the public response to facial recognition systems,” she says.
Ehsan is part of a small but growing group of researchers trying to make AIs better at explaining themselves, to help us look inside the black box. The aim of so-called interpretable or explainable AI (XAI) is to help people understand what features in the data a neural network is actually learning—and thus whether the resulting model is accurate and unbiased.
One solution is to build machine-learning systems that show their workings: so-called glassbox—as opposed to black-box—AI. Glassbox models are typically much-simplified versions of a neural network in which it is easier to track how different pieces of data affect the model.
“There are people in the community who advocate for the use of glassbox models in any high-stakes setting,” says Jennifer Wortman Vaughan, a computer scientist at Microsoft Research. “I largely agree.” Simple glassbox models can perform as well as more complicated neural networks on certain types of structured data, such as tables of statistics. For some applications that's all you need.
But it depends on the domain. If we want to learn from messy data like images or text, we’re stuck with deep—and thus opaque—neural networks. The ability of these networks to draw meaningful connections between very large numbers of disparate features is bound up with their complexity.
Even here, glassbox machine learning could help. One solution is to take two passes at the data, training an imperfect glassbox model as a debugging step to uncover potential errors that you might want to correct. Once the data has been cleaned up, a more accurate black-box model can be trained.
It's a tricky balance, however. Too much transparency can lead to information overload. In a 2018 study looking at how non-expert users interact with machine-learning tools, Vaughan found that transparent models can actually make it harder to detect and correct the model’s mistakes.
Another approach is to include visualizations that show a few key properties of the model and its underlying data. The idea is that you can see serious problems at a glance. For example, the model could be relying too much on certain features, which could signal bias.
These visualization tools have proved incredibly popular in the short time they’ve been around. But do they really help? In the first study of its kind, Vaughan and her team have tried to find out—and exposed some serious issues.
The team took two popular interpretability tools that give an overview of a model via charts and data plots, highlighting things that the machine-learning model picked up on most in training. Eleven AI professionals were recruited from within Microsoft, all different in education, job roles, and experience. They took part in a mock interaction with a machine-learning model trained on a national income data set taken from the 1994 US census. The experiment was designed specifically to mimic the way data scientists use interpretability tools in the kinds of tasks they face routinely.
What the team found was striking. Sure, the tools sometimes helped people spot missing values in the data. But this usefulness was overshadowed by a tendency to over-trust and misread the visualizations. In some cases, users couldn’t even describe what the visualizations were showing. This led to incorrect assumptions about the data set, the models, and the interpretability tools themselves. And it instilled a false confidence about the tools that made participants more gung-ho about deploying the models, even when they felt something wasn’t quite right. Worryingly, this was true even when the output had been manipulated to show explanations that made no sense.
To back up the findings from their small user study, the researchers then conducted an online survey of around 200 machine-learning professionals recruited via mailing lists and social media. They found similar confusion and misplaced confidence.
Worse, many participants were happy to use the visualizations to make decisions about deploying the model despite admitting that they did not understand the math behind them. “It was particularly surprising to see people justify oddities in the data by creating narratives that explained them,” says Harmanpreet Kaur at the University of Michigan, a coauthor on the study. “The automation bias was a very important factor that we had not considered.”
Ah, the automation bias. In other words, people are primed to trust computers. It’s not a new phenomenon. When it comes to automated systems from aircraft autopilots to spell checkers, studies have shown that humans often accept the choices they make even when they are obviously wrong. But when this happens with tools designed to help us avoid this very phenomenon, we have an even bigger problem.
What can we do about it? For some, part of the trouble with the first wave of XAI is that it is dominated by machine-learning researchers, most of whom are expert users of AI systems. Says Tim Miller of the University of Melbourne, who studies how humans use AI systems: “The inmates are running the asylum.”
This is what Ehsan realized sitting in the back of the driverless Uber. It is easier to understand what an automated system is doing—and see when it is making a mistake—if it gives reasons for its actions the way a human would. Ehsan and his colleague Mark Riedl are developing a machine-learning system that automatically generates such rationales in natural language. In an early prototype, the pair took a neural network that had learned how to play the classic 1980s video game Frogger and trained it to provide a reason every time it made a move.
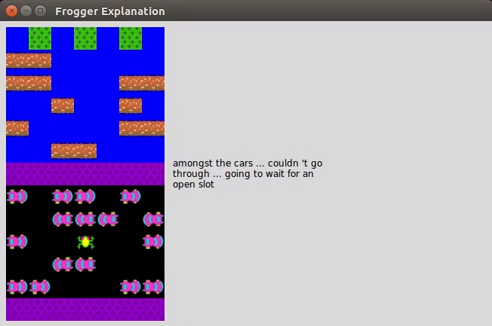
To do this, they showed the system many examples of humans playing the game while talking out loud about what they were doing. They then took a neural network for translating between two natural languages and adapted it to translate instead between actions in the game and natural-language rationales for those actions. Now, when the neural network sees an action in the game, it “translates” it into an explanation. The result is a Frogger-playing AI that says things like “I’m moving left to stay behind the blue truck” every time it moves.
Ehsan and Riedl’s work is just a start. For one thing, it is not clear whether a machine-learning system will always be able to provide a natural-language rationale for its actions. Take DeepMind’s board-game-playing AI AlphaZero. One of the most striking features of the software is its ability to make winning moves that most human players would not think to try at that point in a game. If AlphaZero were able to explain its moves, would they always make sense?
Reasons help whether we understand them or not, says Ehsan: “The goal of human-centered XAI is not just to make the user agree to what the AI is saying—it is also to provoke reflection.” Riedl recalls watching the livestream of the tournament match between DeepMind's AI and Korean Go champion Lee Sedol. The commentators were talking about what AlphaGo was seeing and thinking. "That wasn’t how AlphaGo worked," says Riedl. "But I felt that the commentary was essential to understanding what was happening."
What this new wave of XAI researchers agree on is that if AI systems are to be used by more people, those people must be part of the design from the start—and different people need different kinds of explanations. (This is backed up by a new study from Howley and her colleagues, in which they show that people’s ability to understand an interactive or static visualization depends on their education levels.) Think of a cancer-diagnosing AI, says Ehsan. You’d want the explanation it gives to an oncologist to be very different from the explanation it gives to the patient.
Ultimately, we want AIs to explain themselves not only to data scientists and doctors but to police officers using face recognition technology, teachers using analytics software in their classrooms, students trying to make sense of their social-media feeds—and anyone sitting in the backseat of a self-driving car. “We’ve always known that people over-trust technology, and that’s especially true with AI systems,” says Riedl. “The more you say it’s smart, the more people are convinced that it’s smarter than they are.”
Explanations that anyone can understand should help pop that bubble.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.