The computing power needed to train AI is now rising seven times faster than ever before

In 2018, OpenAI found that the amount of computational power used to train the largest AI models had doubled every 3.4 months since 2012.
The San Francisco-based for-profit AI research lab has now added new data to its analysis. This shows how the post-2012 doubling compares with the historic doubling time since the beginning of the field. From 1959 to 2012, the amount of power used doubled every two years, tracking Moore’s Law. This means the resources used today are doubling at a rate seven times faster than before.
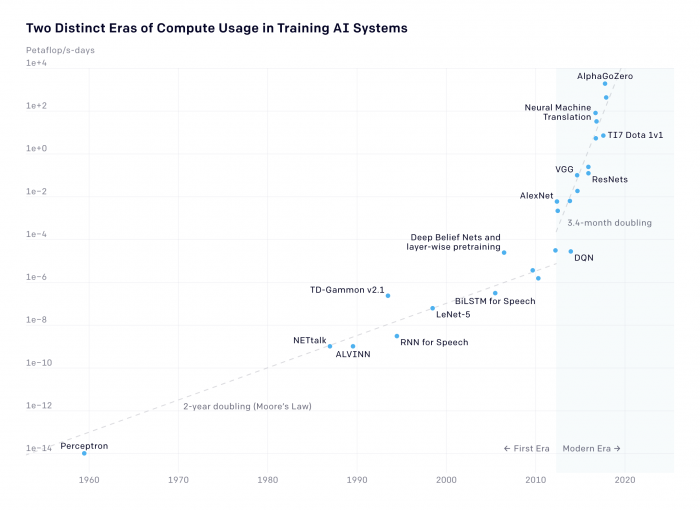
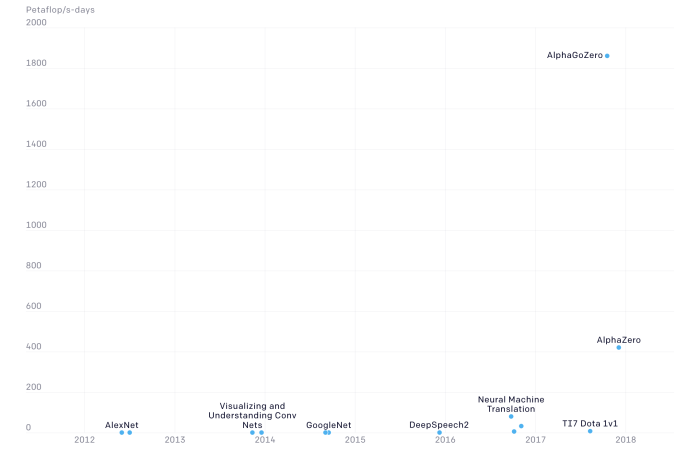
This dramatic increase in the resources needed underscores just how costly the field’s achievements have become. Keep in mind that the above graph shows a logarithmic scale. On a linear scale (below), you can more clearly see how compute usage has increased by 300,000-fold in the last seven years.
The chart also notably does not include some of the most recent breakthroughs, including Google’s large-scale language model BERT, OpenAI’s language model GPT-2, or DeepMind’s StarCraft II-playing model AlphaStar.
In the past year, more and more researchers have sounded the alarm on the exploding costs of deep learning. In June, an analysis from researchers at the University of Massachusetts, Amherst, showed how these increasing computational costs directly translate into carbon emissions.
In their paper, they also noted how the trend exacerbates the privatization of AI research because it undermines the ability for academic labs to compete with much more resource-rich private ones.
In response to this growing concern, several industry groups have made recommendations. The Allen Institute for Artificial Intelligence, a nonprofit research firm in Seattle, has proposed that researchers always publish the financial and computational costs of training their models along with their performance results, for example.
In its own blog, OpenAI suggested policymakers increase funding to academic researchers to bridge the resource gap between academic and industry labs.
Correction: A previous version of this article incorrectly stated the doubling time today is more than seven times the rate before. The resources used are doubling seven times faster, and the doubling time itself is one-seventh the previous time.
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.