Deep learning will help keep video from clogging up the internet

Video fills the internet. Some 75% of all traffic is video content, and this volume is expected to grow three times over by 2021.
If we don’t want the insatiable demand for cat videos and streaming services to clog the pipelines forever, then, we’ll have to rely on video compression. This is the process of reencoding a video file so that it is smaller than the original. But current compression techniques are ancient by the standards of modern technology. “The fundamentals of existing video compression algorithms have not changed considerably over the last 20 years,” say Oren Rippel and co at WaveOne, a deep-learning company that is attempting to drag video compression into the 21st century.
These guys have used deep learning to develop a new compression algorithm that significantly outperforms existing video codecs. “To our knowledge, this is the first machine learning–based method to do so,” they say.
The basic idea behind video compression is to remove redundant data from a code and replace it with a shorter description that still allows the video to be reproduced later. Most video compression takes place in two steps.
The first, motion compression, looks for moving objects and attempts to predict where they will be in the next frame. Then, instead of recording the pixels associated with this moving object in every frame, the algorithm encodes only the object shape, along with the direction of travel. Indeed, some algorithms look at future frames to determine movement even more accurately, although this obviously cannot work for live broadcasts. The result is that compressed video simply translates the object across the screen.
The second compression step removes other redundancies between one frame and the next. So instead of recording the color of each pixel in a blue sky, a compression algorithm might identify the area of this color and specify that it does not change over the next few frames. So these pixels stay the same color until told to change. This is called residual compression.
The new approach that Rippel and co have pioneered uses machine learning to improve both of these compression techniques. Take motion compression, where the team’s machine-learning techniques have found new motion-based redundancies that conventional codecs have never been able to exploit.
For example, a person’s head turning from a frontal view to a side view always produces a similar result. “Traditional codecs will not be able to predict a profile face from a frontal view,” say Rippel and co. By contrast, the new codec learns these kinds of spatio-temporal patterns and uses them to predict future frames.
Another problem is to distribute the available bandwidth between motion and residual compression. In some scenes, motion compression is more important; in others, residual compression provides the greatest gains. The optimal trade-off between them differs from frame to frame.
Traditional compression algorithms find this hard because they compress both processes separately. That means there is no easy way to trade them off.
Rippel and co get around this by compressing both signals at the same time and use the frame complexity to decide how to distribute the bandwidth between them in the most efficient way.
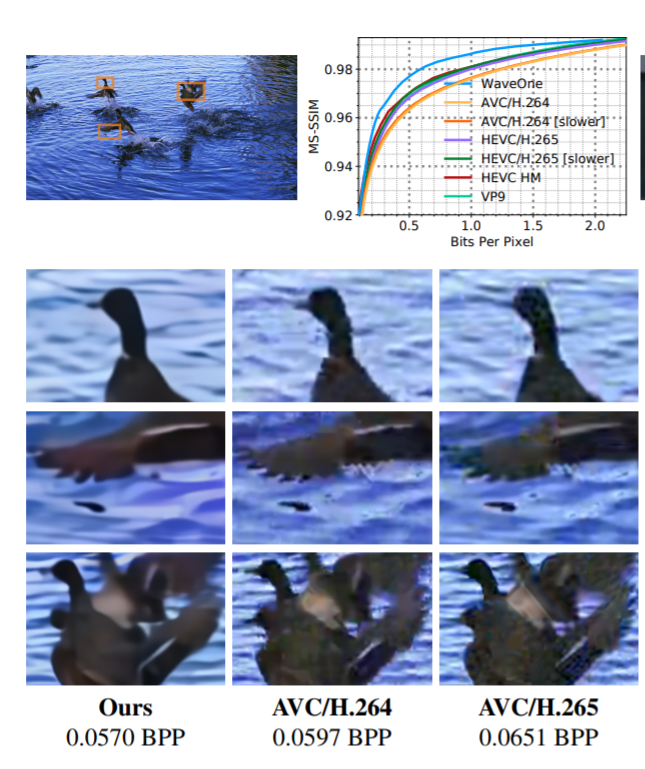
These and other improvements have allowed the researchers to create a compression algorithm that significantly outperforms traditional codecs. When compressing high-definition (1080p) video, ordinary compression algorithms, such as H.265 and VP9, produce files that are 20% larger than those produced by the new algorithm.
And the gains are even larger for standard-definition videos, such as HEVC/H.265 and AVC/H.264. These typically produce files up to 60% larger than the team’s new approach.
That’s an impressive gain that could significantly reduce the size and download times associated with online video.
However, the new approach is not without some shortcomings. Perhaps the most significant is its computational efficiency—the time it takes to encode and decode the videos. On an Nvidia Tesla V100 rig, and on VGA-sized videos, the new decoder runs at an average speed of around 10 frames per second with the encoder operating at around 2 frames per second. That has limited application for a live broadcast.
Of course, the researchers expect to make significant improvements as they move beyond the proof-of-principle stage. “The current speed is not sufficient for real-time deployment, but is to be substantially improved in future work,” they say.
Which means that thanks to this kind of machine-learning approach, future cybersurfers should be able download their Game of Thrones or cat videos in record times and stream their high-definition soccer games more efficiently then ever.
Ref: arxiv.org/abs/1811.06981: Learned Video Compression
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.