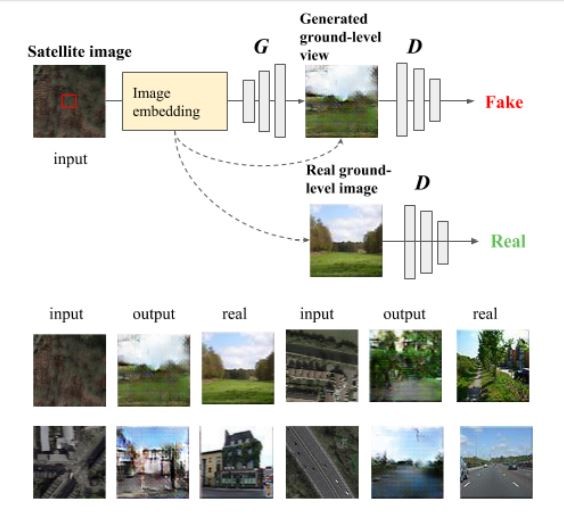
Given a satellite image, machine learning creates the view on the ground
Leonardo da Vinci famously created drawings and paintings that showed a bird’s eye view of certain areas of Italy with a level of detail that was not otherwise possible until the invention of photography and flying machines. Indeed, many critics have wondered how he could have imagined these details. But now researchers are working on the inverse problem: given a satellite image of Earth’s surface, what does that area look like from the ground? How clear can such an artificial image be?
Today we get an answer thanks to the work of Xueqing Deng and colleagues at the University of California, Merced. These guys have trained a machine-learning algorithm to create ground-level images simply by looking at satellite pictures from above.
The technique is based on a form of machine intelligence known as a generative adversarial network. This consists of two neural networks called a generator and a discriminator.
The generator creates images that the discriminator assesses against some learned criteria, such as how closely they resemble giraffes. By using the the output from the discriminator, the generator gradually learns to produce images that look like giraffes.
In this case, Deng and co trained the discriminator using real images of the ground as well as satellite images of that location. So it learns how to associate a ground-level image with its overhead view.
Of course, the quality of the data set is important. The team use as ground truth the LCM2015 ground-cover map, which gives the class of land at a one-kilometer resolution for the entire UK. However, the team limits the data to a 71x71-kilometer grid that includes London and surrounding countryside. For each location in this grid they downloaded a ground-level view from an online database called Geograph.
The team then trained the discriminator with 16,000 pairs of overhead and ground-level images.
The next step was to start generating ground-level images. The generator was fed a set of 4,000 satellite images of specific locations and had to create ground-level views for each, using feedback from the discriminator. The team tested the system with 4,000 overhead images and compared them with the ground truth images.
The results make for interesting reading. The network produces images that are plausible given the overhead image, if relatively low in quality. The generated images capture basic qualities of the ground, such as whether it shows a road, whether the land is rural or urban, and so on. “The generated ground-level images looked natural although, as expected, they lacked the details of real images,” say Deng and co.
That’s a neat trick, but how useful is it? One important task for geographers is to classify land according to its use, such as whether it is rural or urban.
Ground-level images are essential for this. However, existing databases tend to be sparse, particularly in rural locations, so geographers have to interpolate between the images, a process that is little better than guessing.
Now Deng and co’s generative adversarial networks provide an entirely new way to determine land use. When geographers want to know the ground-level view at any location, they can simply create the view with the neural network based on a satellite image.
Deng and co even compare the two methods—interpolation versus image generation. The new technique turns out to correctly determine land use 73 percent of the time, while the interpolation method is correct in just 65 percent of cases.
That’s interesting work that could make geographers’ lives easier. But Deng and co have greater ambitions. They hope to improve the the image generation process so that in future it will produce even more detail in the ground-level images. Leonardo da Vinci would surely be impressed.
Ref: https://arxiv.org/abs/1806.05129 : What Is It Like Down There? Generating Dense Ground-Level Views and Image Features From Overhead Imagery Using Conditional Generative Adversarial Networks
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.