100,000 happy moments
The science of happiness is of increasing interest to psychologists and to society in general. The questions at the heart of this discipline are: what makes us happy, and what sustains this happiness over time?
A variety of factors seem to play important roles. Psychologists think about 50 percent of our happiness is the result of our genes—we seem to be pre-programmed for a certain level of happiness. By contrast, they think our environment—our life circumstances—contributes only 10 percent to our happiness levels.
The rest is under our control. Some 40 percent of our happiness levels are the result of the choices we make. These are things like investing in long-term relationships, doing meaningful work, and bonding with loved ones.
Indeed, the relatively new discipline of positive psychology steers people toward these behaviors. And an increasing number of apps help people make choices to boost their happiness levels.
But the study of these choices and behaviors is in its infancy. Happiness is not a uniform state that can be switched on and off on demand. Instead, it is a state or set of states that can be triggered by a rich tapestry of conditions and permutations of them. And yet there has been relatively little work that teases apart the nature of these conditions and how they arise.
Today, that looks set to change thanks to the work of Akari Asai at the University of Tokyo, in Japan, and colleagues from around the world. These folks have built a database of 100,000 happy moments and begun the challenging task of data mining the contents. And the team has made the database—HappyDB—publicly available online so that anybody can explore it further.
The database was straightforward to create. The team set up a task on Amazon’s Mechanical Turk crowdsourcing service that asked people to describe three happy moments in the previous 24 hours or the previous three months.
In this way, they gathered descriptions of 100,000 happy moments from equal proportions of men and women. These people—the Turkers—were based in the US, largely between 20 and 40 years of age, and mostly single.
Asai and co. have cleaned up the database in various ways such as correcting obvious spelling mistakes. That was important because initially the database contained many more references to sons than daughters.
But this turned out to be the result of people misspelling the word daughter more commonly than son. “After fixing the typos, both words ended up having almost the same frequency,” say Asai and co.
Examples of happy moments from the database include:
Went out with a friend, had some food and talked about life
I had dinner with my husband
I went for a jog this evening and the weather was nice and it was shady
I'm so excited to be able to travel to Florida next month. I'm getting giggly just thinking about it
I kissed my girlfriend in the hot tub
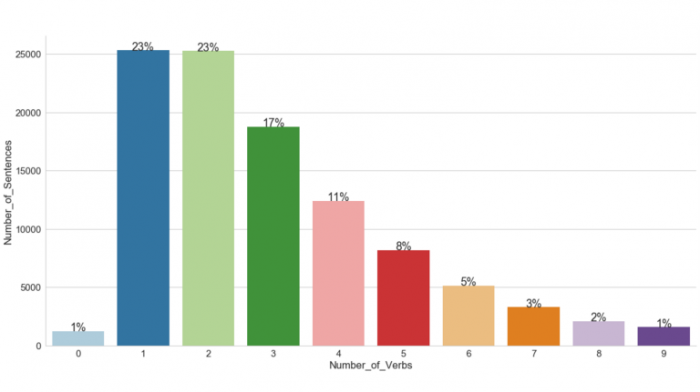
These sentences immediately raise the question of how best to analyze them. So Asai and co. have begun the task using natural language processing to analyze the activities that occurred in the happy moment, who participated in them, and what other factors might play a role.
Analysis turns out to be a complex task. For example, the superficially simple sentence “I had dinner with my husband” raise the question of what exactly about this activity made the moment happy. “The extracted activities could be “having dinner,” “being with the husband,” or something that is not explicitly in the text such as “having a date night without the children,” say Asai and co.
The team delved more deeply by analyzing the phrases using standard measures of sentiment and emotional valence. They also attempted to divide the phrases into nine categories, such as achievement, affection, and exercise.
Achievement, for example, involves activities “with extra effort to achieve a better than expected result.” Examples might include “finish work” or “complete marathon.”
Affection involves activities with meaningful interaction with family, loved ones and pets. Examples include a hug, cuddling, or a kiss.
And exercise involves activities “with intent to exercise or workout” such as run, bike, or do yoga.
Finally, the team broke down the results by whether the happy moment occurred in the previous 24 hours or the previous three months. That provided some insight into the difference between activities that provide momentary happiness and those that provide sustained happiness.
“The results suggest that moments reported in the 24-hour period tend to be activities that occur daily (e.g., foods, bedtime) and moments reported in the three-month period tend to reflect infrequent occurrences like holidays or life events,” say Asai and co.
Of course, Asai and co. point out that this kind of analysis is just the beginning of what is likely to be a complex field of natural language processing. They suggest a wide range of questions that this approach could address. For example:
What are the activities described in a given happy moment?
What other components besides activities are important in the happy moment?
Which of these aspects are most central to the happy moment?
Can we discover common paraphrasings to describe activities that appear in happy moments?
These are ambitious questions that will require significant advances in natural language processing.
Then there are additional questions such as how do happy moments vary among demographic groups, among cultures, by geography, and so on. There is plenty of gold in them thar hills.
Which is why the release of the 100,000 happy moments database is a significant step toward a better understanding of happiness and of finding ways to help individuals achieve happiness on their own terms.
Ref: arxiv.org/abs/1801.07746 : HappyDB: A Corpus of 100,000 Crowdsourced Happy Moments
Deep Dive
Policy
Is there anything more fascinating than a hidden world?
Some hidden worlds--whether in space, deep in the ocean, or in the form of waves or microbes--remain stubbornly unseen. Here's how technology is being used to reveal them.
A brief, weird history of brainwashing
L. Ron Hubbard, Operation Midnight Climax, and stochastic terrorism—the race for mind control changed America forever.
What Luddites can teach us about resisting an automated future
Opposing technology isn’t antithetical to progress.
Africa’s push to regulate AI starts now
AI is expanding across the continent and new policies are taking shape. But poor digital infrastructure and regulatory bottlenecks could slow adoption.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.