When AI Supplies the Sound in Video Clips, Humans Can’t Tell the Difference
Machine learning is changing the way we think about images and how they are created. Researchers have trained machines to generate faces, to draw cartoons, and even to transfer the style of paintings to pictures. It is just a short step from these techniques to creating videos in this way, and indeed this is already being done.
All that points to a way of creating virtual environments entirely by machine. That opens all kinds of possibilities for the future of human experience.
But there is a problem. Video is not just a visual experience; generating realistic sound is just as important. So an interesting question is whether machines can convincingly generate the audio component of a video.
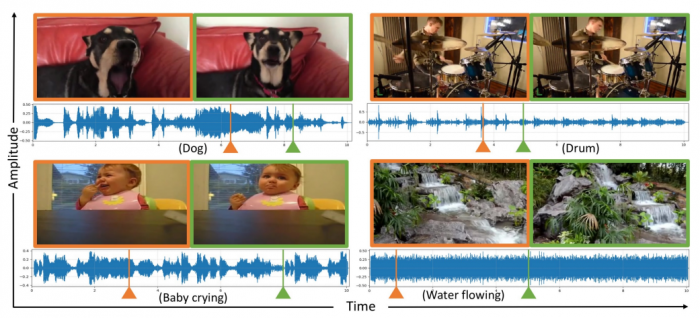
Today we get an answer thanks to the work of Yipin Zhou and pals at the University of North Carolina at Chapel Hill and a few buddies at Adobe Research. These guys have trained a machine-learning algorithm to generate realistic soundtracks for short video clips.
Indeed, the sounds are so realistic that they fool most humans into thinking they are real. You can take a test yourself here to see if you can tell the difference.
The team take the standard approach to machine learning. Algorithms are only ever as good as the data used to train them, so the first step is to create a large, high-quality annotated data set of video examples.
The team create this data set by selecting a subset of clips from a Google collection called Audioset, which consists of over two million 10-second clips from YouTube that all include audio events. These videos are divided into human-labeled categories focusing on things like dogs, chainsaws, helicopters, and so on
To train a machine, the team must have clips in which the sound source is clearly visible. So any video that contains audio from off-screen events is unsuitable. The team filters these out using crowdsourced workers from Amazon’s Mechanical Turk service to find clips in which the audio source is clearly visible and dominates the soundtrack.
That produced a new data set with over 28,000 videos, each about seven seconds in length, covering 10 different categories.
Next, the team used these videos to train a machine to recognize the waveforms associated with each category and to reproduce them from scratch using a neural network called SampleRNN.
Finally, they tested the results by asking human evaluators to rate the quality of the sound accompanying a video and to determine whether it is real or artificially generated.
The results suggest that machines can become pretty good at this task. “Our experiments show that the generated sounds are fairly realistic and have good temporal synchronization with the visual inputs,” say Zhou and co.
And human evaluators seem to agree. “Evaluations show that over 70% of the generated sound from our models can fool humans into thinking that they are real,” say Zhou and co.
That’s interesting work that paves the way for automated sound editing. A common problem in videos is that extraneous noise from an off-screen source can ruin a clip. So having a way to automatically replace the sound with a realistic machine-generated alternative will be useful.
And with Adobe’s involvement in this research, it may not be long before we see this kind of capability in commercial video editing software.
Ref: arxiv.org/abs/1712.01393 : Visual to Sound: Generating Natural Sound for Videos in the Wild
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.