IQ Test Result: Advanced AI Machine Matches Four-Year-Old Child’s Score
The rapid advances in information processing technology in recent years have created computing devices with formidable powers. These machines have long been better than humans at arithmetic, certain games such as chess, and more recently at advanced pattern recognitions tasks such as face recognition.
But an outstanding questions is: to what extent do these capabilities add up to the equivalent of human intelligence? Today, we get answer of sorts thanks to the work of Stellan Ohlsson at the University of Illinois and a few pals who have put one of the world’s most powerful artificial intelligence machines through its paces using a standard IQ test given to humans.
The results show that even though computers have become far more powerful in recent years, they have some catching up to do to match human performance levels.
First some background. The science of measuring human skills and performance is known as psychometrics. When it comes to human intelligence, the most widely accepted psychometric test is the Intelligence Quotient, or IQ test.
This consists of two parts. The first is a set of questions designed to test various aspects of human performance. The second is a database of test results that future results can be compared against. This is how humans are rated; as above or below average compared to the database, for example.
IQ tests are also designed to test humans at different stages of their lives. So a test designed for adults is unlikely to provide much insight into the performance of 10-year-olds or 4-year-olds. So the process of designing tests and creating the test-result database has to be done for each of these groups.
Over the years, computer scientists have created a number of AI machines that have attempted to gain a rational understanding of the world around them. One of the most famous, called ConceptNet, has been under development at MIT since the 1990s.
To gauge its “intelligence,” Ohlsson and co used a verbal IQ test designed for children to test ConceptNet 4 (ConceptNet 5 has since been released).
This test, known as the Wechsler Preschool and Primary Scale of Intelligence, measures children’s performance in five categories: information, vocabulary, word reasoning, comprehension, and similarities.
The information category contains questions such as: “Where can you find a penguin?”
The vocabulary category contains questions such as: “What is ___?” as in “What is a house?”
In word reasoning, a child must identify something from three clues, such as: “You can see through it,” “it is square,” and “you can open it.”
The similarities questions are of the form: “Finish what I say. X and Y are both ___” as in “Finish what I say. Pen and pencil are both ___.” This requires the child to understand two concepts and find the overlap between them.
And finally, the comprehension questions are of the form: “Why do people shake hands?” This requires the construction of an explanation and so goes beyond mere information retrieval.
Ohlsson and co administered this test by feeding the questions to the AI machine in a modified form. This required some programming to allow the questions to interface with the computer’s structure of knowledge about the world.
And the results make for interesting reading. “ConceptNet does well on Vocabulary and Similarities, middling on Information, and poorly on Word Reasoning and Comprehension,” say Ohlsson and co.
In particular, the answers it gave were hugely sensitive to the way it interpreted the question. For example, in the comprehension category, the machine was asked “Why do we shake hands?”
For ConceptNet 4, this boils down to a search related to three concepts, two one-word concepts of “shake” and “hand” and one two-word concept of “shake hands.” If it uses all these concepts to search for an answer, it produces ”epileptic fit.”
However, forcing the machine to consider only single concepts produces the much more satisfactory answers ”thanks,” ”flirt,” and ”meet friend.”
But that doesn’t always work. For example, in the information category, the machine was asked “where can you find a teacher?”
The machine breaks this down into a request for three different concepts: those of “find” and “teacher” and of the two-word concept “find teacher.” Using all these, it gives the answer correctly as But if Ohlsson and co force it to consider only the two-word concept “find teacher,” it gives the puzzling answers ”band” or ”piano.”
Just why it has trouble with this kind of reasoning in certain circumstances isn’t clear.
What’s more, many of the wrong answers are entirely unlike those that children would give. For example, in the word reasoning category, ConceptNet 4 was given the following clues: “This animal has a mane if it is male,” “this is an animal that lives in Africa,” and “this a big yellowish-brown cat.”
But its top five answers were: dog, farm, creature, home, and cat.
That’s bizarre. “Common sense should at the very least confine the answer to animals, and should also make the simple inference that, “if the clues say it is a cat, then types of cats are the only alternatives to be considered,” say Ohlsson and co.
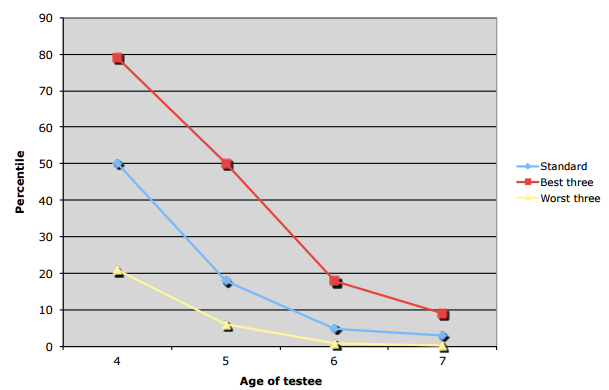
All this pointed Ohlsson and co to a clear conclusion. “The ConceptNet system scored a WPPSI-III VIQ that is average for a four-year-old child, but below average for five- to seven-year-olds,” they say.
That’s an interesting result. Of course, there are various ways that the test could be improved. One is to give the computer natural language processing capabilities. That would reduce its reliance on the programming necessary to enter the questions and is something that is already becoming possible with online assistants such as Siri, Cortana, and Google Now.
Perhaps the most significant point is that this work was done on a version of ConceptNet 4 that dates back to 2012. Artificial intelligence has changed rapidly since then. The main change has been a switch from knowledge gathering to being learning-driven. These systems now crunch vast databases of information to gain insights about language, images, and other aspects of the world. This has led to an exponential improvement in performance in many tasks, such as face recognition.
Taking Ohlsson and co’s result at face value, it’s taken 60 years of AI research to build a machine in 2012 that can come anywhere close to matching the common sense reasoning of a four-year old. But the nature of exponential improvements raises the prospect that the next six years might produce similarly dramatic improvements.
So a question that we ought to be considering with urgency is: what kind of AI machine might we be grappling with in 2018?
Ref: arxiv.org/abs/1509.03390 : Measuring an Artificial Intelligence System’s Performance on a Verbal IQ Test for Young Children
Keep Reading
Most Popular
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
The problem with plug-in hybrids? Their drivers.
Plug-in hybrids are often sold as a transition to EVs, but new data from Europe shows we’re still underestimating the emissions they produce.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.