Deep Learning Machine Beats Humans in IQ Test
Just over 100 years ago, the German psychologist William Stern introduced the intelligence quotient test as a way of evaluating human intelligence. Since then, IQ tests have become a standard feature of modern life and are used to determine children’s suitability for schools and adults’ ability to perform jobs.
These tests usually contain three categories of questions: logic questions such as patterns in sequences of images, mathematical questions such as finding patterns in sequences of numbers and verbal reasoning questions, which are based around analogies, classifications, as well as synonyms and antonyms.
It is this last category that has interested Huazheng Wang and pals at the University of Science and Technology of China and Bin Gao and buddies at Microsoft Research in Beijing. Computers have never been good at these. Pose a verbal reasoning question to a natural language processing machine and its performance will be poor, much worse than the average human ability.
Today, that changes thanks to Huazheng and pals who have built a deep learning machine that outperforms the average human ability to answer verbal reasoning questions for the first time.
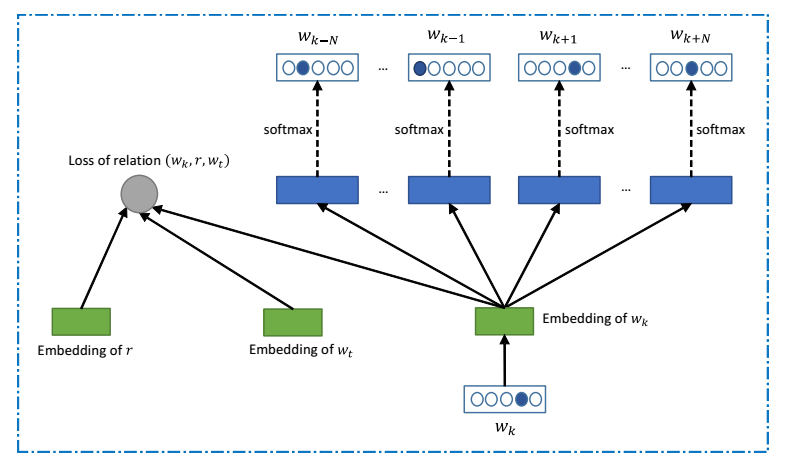
In recent, years, computer scientists have used data mining techniques to analyze huge corpuses of texts to find the links between words they contain. In particular, this gives them a handle on the statistics of word patterns, such as how often a particular word appears near other words. From this it is possible to work out how words relate to each other, albeit in a huge parameter space.
The end result is that words can be thought of as vectors in this high-dimensional parameter space. the advantage is that they can then be treated mathematically: compared, added, subtracted like other vectors. This leads to vector relations like this one: king – man + woman = queen.
This approach has been hugely successful. Google uses it for automatic language translation by assuming that word sequences in different language represented by similar vectors are equivalent in meaning. So they are translations of each other.
But this approach has a well-known shortcoming: it assumes that each word has a single meaning represented by a single vector. Not only is that often not the case, verbal tests tend to focus on words with more than one meaning as a way of making questions harder.
Huazheng and pals tackle this by taking each word and looking for other words that often appear nearby in a large corpus of text. They then use an algorithm to see how these words are clustered. The final step is to look up the different meanings of a word in a dictionary and then to match the clusters to each meaning.
This can be done automatically because the dictionary definition includes sample sentences in which the word is used in each different way. So by calculating the vector representation of these sentences and comparing them to the vector representation in each cluster, it is possible to match them.
The overall result is a way of recognizing the multiple different senses that some words can have.
Huazheng and pals have another trick up their sleeve to make it easier for a computer to answer verbal reasoning questions. This comes about because these questions fall into several categories that require slightly different approaches to solve.
So their idea is to start by identifying the category of each question so that the computer then knows which answering strategy it should employ. This is straightforward since the questions in each category have similar structures.
So questions that involve analogies are like these:
Isotherm is to temperature as isobar is to? (i) atmosphere, (ii) wind, (iii) pressure, (iv) latitude, (v) current.
and
Identify two words (one from each set of brackets) that form a connection (analogy) when paired with the words in capitals: CHAPTER (book, verse, read), ACT (stage, audience, play).
Word classification questions are like this:
Which is the odd one out? (i) calm, (ii) quiet, (iii) relaxed, (iv) serene, (v) unruffled.
And questions looking for synonyms and antonyms are like these:
Which word is closest to IRRATIONAL? (i) intransigent, (ii) irredeemable, (iii) unsafe, (iv) lost, (v) nonsensical.
And
Which word is most opposite to MUSICAL? (i) discordant, (ii) loud, (iii) lyrical, (iv) verbal, (v) euphonious.
Spotting each type of question is relatively straightforward for a machine learning algorithm, given enough to examples to learn from. And this is exactly how Huazheng and co do it.
Having identified the type of question, Huazheng and buddies then devise an algorithm for solving each one using the standard vector methods but also the multi-sense upgrade they’ve developed.
They compare this deep learning technique with other algorithmic approaches to verbal reasoning tests and also with the ability of humans to do it. For this, they posed the questions to 200 humans gathered via Amazon’s Mechanical Turk crowdsourcing facility along with basic information about their ages and educational background.
And the results are impressive. “To our surprise, the average performance of human beings is a little lower than that of our proposed method,” they say.
Human performance on these tests tends to correlate with educational background. So people with a high school education tend to do least well, while those with a bachelor’s degree do better and those with a doctorate perform best. “Our model can reach the intelligence level between the people with the bachelor degrees and those with the master degrees,” say Huazheng and co.
That’s fascinating work that reveals the potential of deep learning techniques. Huazheng and co are clearly optimistic about future developments. “With appropriate uses of the deep learning technologies, we could be a further step closer to the true human intelligence.”
Deep learning techniques are currently sweeping through computer science like wildfire and the revolution they are creating is still in its early stages. There’s no telling where this revolution will take us but one thing is for sure: William Stern would be amazed.
Ref: arxiv.org/abs/1505.07909 : Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding
Deep Dive
Artificial intelligence
Large language models can do jaw-dropping things. But nobody knows exactly why.
And that's a problem. Figuring it out is one of the biggest scientific puzzles of our time and a crucial step towards controlling more powerful future models.
Google DeepMind’s new generative model makes Super Mario–like games from scratch
Genie learns how to control games by watching hours and hours of video. It could help train next-gen robots too.
What’s next for generative video
OpenAI's Sora has raised the bar for AI moviemaking. Here are four things to bear in mind as we wrap our heads around what's coming.
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.