Deep Learning Machine Solves the Cocktail Party Problem
The cocktail party effect is the ability to focus on a specific human voice while filtering out other voices or background noise. The ease with which humans perform this trick belies the challenge that scientists and engineers have faced in reproducing it synthetically. By and large, humans easily outperform the best automated methods for singling out voices.
A particularly challenging cocktail party problem is in the field of music, where humans can easily concentrate on a singing voice superimposed on a musical background that includes a wide range of instruments. By comparison, machines are poor at this task.
Today, that looks to be changing thanks to the work of Andrew Simpson and pals at the University of Surrey in the U.K. These guys have used some of the most recent advances associated with deep neural networks to separate human voices from the background in a wide range of songs.
Their approach showcases the huge advances that have been made in recent years in machine learning and neural networks. And it paves the way for a more general solution to the famous cocktail party problem which should allow, among other things, the vocals to be easily separated from the music they accompany.
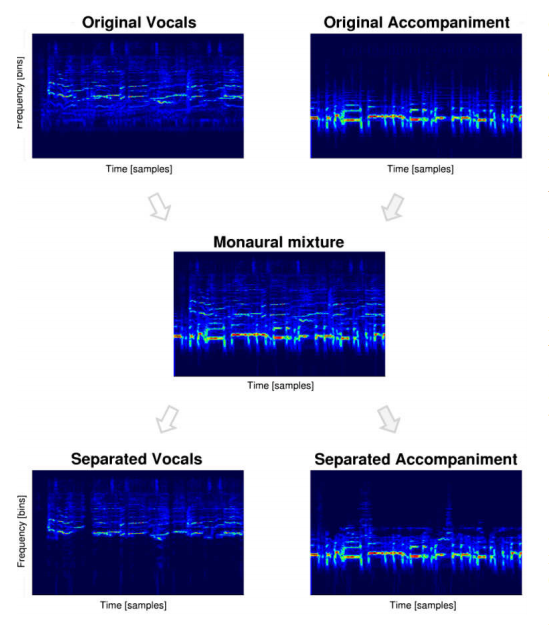
The method these guys use is relatively straightforward. They start with a database of 63 songs that are available as a set of individual tracks that each contain a different instrument or voice, as well as the fully mixed version of the song.
Simpson and co divide each track into 20-second segments and create a spectrogram for each that shows how the frequencies in the sound vary over time. The result is a kind of unique fingerprint that identifies the instrument or voice.
They also create a spectrogram of the fully mixed version of the song. This is essentially all of the component spectrograms added together.
The task of picking out a voice from this mixture is essentially the task of separating the voice’s unique spectrogram from the other spectrograms that are present.
Simpson and co trained their deep convolutional neural network to do exactly that. They used 50 of these songs to train the network while keeping the remaining 13 to test it on. In total that generated more than 20,000 spectrograms for training purposes.
The task for the neural network was simple. As an input, they gave it the fully mixed spectrogram and expected it to produce, essentially, the vocal spectrogram as the output.
The task in this kind of machine learning is one of parameter optimization. Their deep neural network has a billion parameters that need to be tuned in a way that produces the desired output.
This process of optimization—or learning—occurs by iteration. So the network begins with these parameters set randomly and then gradually improves the settings each time it scans through the database, which it did over a hundred iterations.
Having found a good setup for the network, Simpson and co then gave it the 13 songs it had not seen before to test how well it could separate the vocals from the mix.
The outputs turned out to be impressive. “These results demonstrate that a convolutional deep neural network approach is capable of generalizing voice separation, learned in a musical context, to new musical contexts,” say the team.
Simpson and co of even compared their results to those from a conventional cocktail party algorithm applied to the same data. “The main advantage of the deep neural network appears to be in its general learning of what ‘vocal’ sounds are,” they say.
In other words, having learned what a voice sounds like, a deep neural network can use this information to pick out other voices from a mix. But just how good this approach is compared to human performance, they do not say.
One immediate application is in producing music tracks minus vocals for karaoke machines. That’s clearly an … errr … important goal but there are broader implications as well.
Deep neural networks are revolutionizing machine learning in a wide range of areas. Until recently, humans had a clear dominance in pattern recognition tasks such as facial recognition and object recognition. That lead has been considerably reduced and in some cases lost altogether.
Now machines are playing catch up in the area of cocktail party problems and only a fool would bet against them triumphing in the not too distant future.
Ref: arxiv.org/abs/1504.04658 : Deep Karaoke: Extracting Vocals from Musical Mixtures Using a Convolutional Deep Neural Network
Deep Dive
Biotechnology and health
How scientists traced a mysterious covid case back to six toilets
When wastewater surveillance turns into a hunt for a single infected individual, the ethics get tricky.
An AI-driven “factory of drugs” claims to have hit a big milestone
Insilico is part of a wave of companies betting on AI as the "next amazing revolution" in biology
The quest to legitimize longevity medicine
Longevity clinics offer a mix of services that largely cater to the wealthy. Now there’s a push to establish their work as a credible medical field.
There is a new most expensive drug in the world. Price tag: $4.25 million
But will the latest gene therapy suffer the curse of the costliest drug?
Stay connected
Get the latest updates from
MIT Technology Review
Discover special offers, top stories, upcoming events, and more.